
Authors: Jonny McElhinney, Julia Florou-Moreno, and Priti Upadhyay
The capabilities of Generative AI (GenAI) and Large Language Models (LLMs) to analyze text have become widely used and even required in some industries since the rise of ChatGPT in 2023. This blog post investigates LLMs as an option for enhancing SAS’ robust computer vision capabilities. SAS Event Stream Processing (ESP) is used to assess images in real time for real-world use cases and explore the accuracy, latency, token cost, and execution of the image processing capabilities of GPT-4o. We will evaluate these criteria against the typical computer vision development life cycle with SAS ESP. We will demonstrate how to combine the two philosophies to make models and pipelines more transferable across industries and use cases.
In our line of work, we see companies jump at the chance to use GenAI. They use it to complete natural language understanding, text processing, extraction, and summarization tasks as part of a broader pipeline used with SAS analytics. Now, we are seeing the rise of capabilities beyond natural language input in the form of Multimodal Generative AI models. This approach integrates and simultaneously processes multiple forms of data, that include text, images, and even audio, to enhance the understanding and interpretation of information. Multimodal models leverage the strengths of different kinds of data to provide a more comprehensive analysis than what is possible with a single modality.
One such model is GPT-4o, OpenAI's newest flagship model, released in May 2024. OpenAI boasts that GPT-4o generates text twice as fast as GPT-4 while the token cost is half the price. In addition to processing text, audio, and image data, the model has improved reasoning, image processing, audio comprehension, and automatic speech recognition.
Computer vision with SAS
Before the rise of Generative AI, traditional deep learning methods were the go-to method for tackling computer vision problems in Applied AI. Many SAS customers continue to generate value with the help of traditional computer vision model deployments.
Deep learning computer vision models can be deployed to edge devices like CCTV cameras to process multiple frames per second with the help of SAS ESP. SAS ESP enables customers to process high-resolution video footage in real time and make automated decisions in fields such as manufacturing or Customer Packaged Goods (CPG) within milliseconds. Figure 1 shows a flowchart for a typical SAS computer vision model deployment.
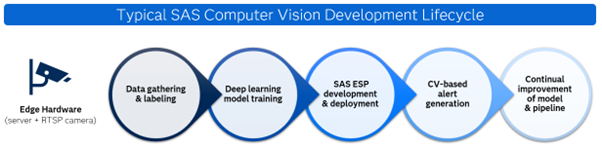
The process can be lengthy and complex to achieve the best results. It often requires videos or frames from the target environment that must be manually labeled before training a deep learning model to provide adequate context. This is time-consuming and labor-intensive. Even then, ‘model drift’ can occur if the camera environment changes slightly or edge cases or rarer events/classes are underrepresented in training data. This can require repeated labeling/training steps to keep the model performing at the desired accuracy level. Reducing the amount of time and work involved in labeling and training is a key motivation for testing new Vision Language Models (VLMs), such as GPT-4o. This is because VLMs are trained on large and diverse image and text data sets, improving their ability to adapt to new contexts.
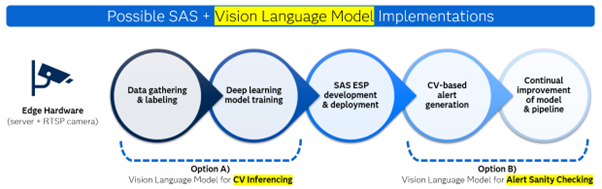
As shown in Figure 2, there are different possibilities for integrating a VLM into a SAS computer vision pipeline. As an inferencing engine to replace a deep learning model, it could replace the need for early model development stages. Or, later in the pipeline, it could act as a final layer of automated review of the SAS ESP outputs. We will review the execution of GPT-4o and evaluate which option best satisfies the accuracy, cost, and latency requirements.
Prompt engineering and safeguarding GPT-4o
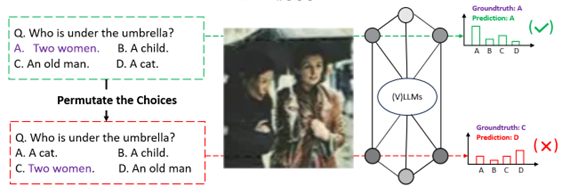
One concern with LLMs is their tendency to ‘hallucinate’ in responses, as occasionally happens when conversing with models like ChatGPT. Similarly, early research into VLMs shows issues to be wary of in the world of image interpretation. Alzahrani et al. demonstrate how models can return different responses when asked about an image purely based on the order of the answers presented, as shown in Figure 3.
GPT-4o takes input in the form of a system message, prompts, and images. We fully control the system messages and prompts to safeguard the model responses. The system message, in particular, is very critical and is usually used to set the tone of the chatbot. Figure 4 shows an example of user input and response from GPT-4o. Users can request outputs in natural language or a particular format (a JSON string, for example) per the use case requirement.

We can be more precise and ask specific questions like the number of people wearing vests to get a more direct response. We ran the same prompt and system message combination multiple times to check its consistency. According to our tests, simpler prompts result in fewer hallucinations. The response from the GPT-4o should be monitored through various images to check that the model is not hallucinating. Metrics such as precision, recall, and F1 score provide a good indication of its performance for a particular application.
API token cost and usage optimization
Cost analysis
OpenAI charges for GPT-4o based on the number of tokens. The cost of input and output tokens varies. Tokens are primarily words, start and end tokens, punctuation, and trailing spaces. But GPT-4o also includes images. According to the latest figures, the input tokens (system message, prompt, input images) are priced at $5 per million tokens. In contrast, the output tokens (VLM response) are priced at $15 per million tokens. Reducing output tokens by providing specific instructions will result in significant savings.
The images are charged according to the level of detail used for processing each one. When the image is processed at a low detail level, a fixed 85 tokens are charged. In contrast, if the image is processed at a high detail level, the number of tokens for the image can be pretty high (for example, 4k resolution = 1105 tokens).
Token usage example
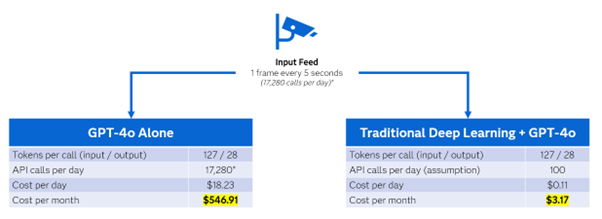
Figure 5 outlines a detailed cost example with input text and images. In this example, we compare using GPT-4o alone for image analysis to using GPT-4o to review alerts generated by a traditional deep learning computer vision pipeline. Note that we are making assumptions about input/output token count as well as the number of ‘alerts’ to review per day for just one camera.
Inference time analysis
GPT-4o’s response time to API calls is also essential for inference on real-time video streams, as SAS ESP processes network camera feeds with high efficiency. Once SAS ESP preprocesses the input, an API call is made to the OpenAI server for inference.
During our testing, GPT-4o’s response time generally ranged from 3-4 seconds per API call, making it difficult to use on real-time video streams. Additionally, offline inferencing becomes a requirement if sensitive customer data cannot leave an internal network due to data protection laws.
Vision Language Models versus traditional methods
Whether traditional deep learning computer vision models (like YOLO or SAM) or pretrained foundational vision language models are the winners depends on the application. Traditional deep learning models require huge data collection and labeling. Pretrained foundation models do not need this phase but might need fine-tuning and careful engineering for a particular application.
Generally, the traditional models have a smaller footprint and higher speed, thus lowering the cost compared to the foundation models. Foundation models have a better understanding of context, allowing for their application across a wide variety of use cases because they are trained on a large amount of data. However, traditional deep learning models are customized for a narrow range of applications. A change in the requirement of the application (for example, detecting a new class) would require a complete retraining of the traditional models. This is not the case with large foundation models.
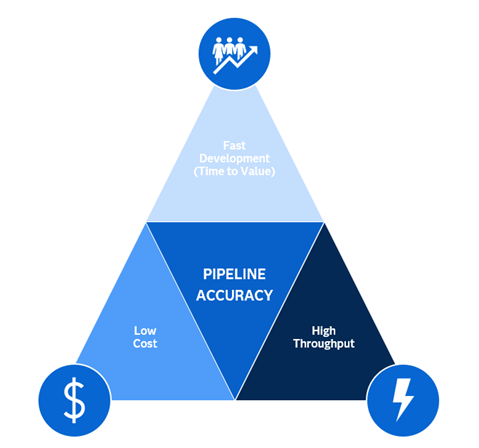
Models like Large Language and Vision Assistant (LLaVA) and Florence 2 are available in open source. They can allow for local inference on edge devices, possibly reducing the inference time. Overall, performance, data set preparation and training time, inference time, and cost are the critical factors to consider before finalizing a particular model. These criteria are shown in Figure 6. Here, pipeline accuracy is the critical focus, and there will always be a trade-off among the three outer factors.
Summary
GPT-4o does a great job of understanding context, though its performance should be validated for hallucinations before using it for a particular application. Subsequently, with each new VLM release, the contextual element and token cost will likely continue to improve.
Currently, we don’t believe that VLMs can entirely replace the established method of traditional deep learning models for computer vision use cases. However, we see potential in using them in a low-cost manner to manually ensure the sensible output of a traditional model (Option B, Figure 2). This represents a good trade-off in terms of accuracy, throughput, and cost.
Overall, we found GPT-4o's computer vision capabilities very impressive, if a little slow to execute. This is especially true when compared with a traditional deep learning model that has been developed and trained over several months to produce the same detections. Even with carefully constructed prompts and system messages, hallucinations can occur unpredictably and introduce risk, whereas our knowledge of the training data enables us to understand predictions from a traditional model better.
LEARN MORE | Computer Vision with SAS LEARN MORE | Warehouse Space Optimization Use Case LEARN MORE | Recipe Optimization Use Case





