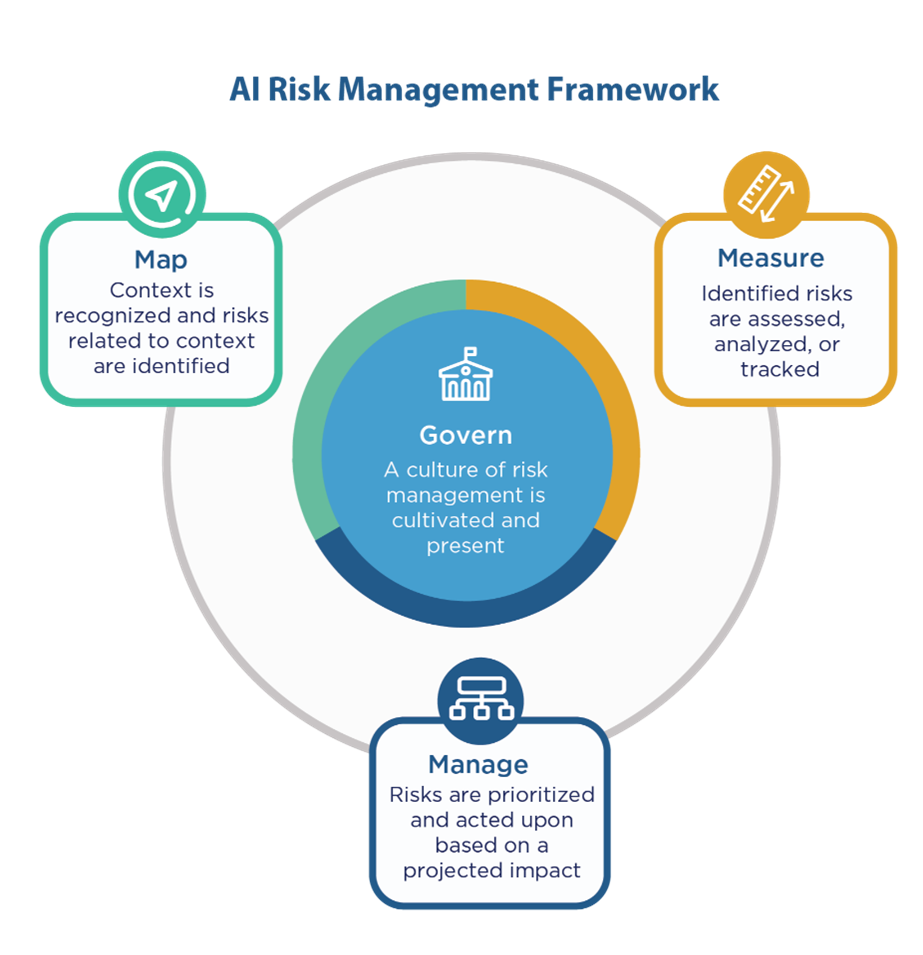
The National Institute of Standards and Technology (NIST) has released a set of standards and best practices within their AI Risk Management Framework for building responsible AI systems.
NIST sits under the U.S. Department of Commerce and their mission is to promote innovation and industrial competitiveness. NIST offers a portfolio of measurements, standards, and legal metrology to provide recommendations that ensure traceability, enable quality assurance, and harmonize documentary standards and regulatory practices. While these standards are not mandatory or compulsory, they are designed to increase the trustworthiness of AI systems. This framework is very detailed with recommendations across four functions: govern, map, measure, and manage. This blog will focus on a few of these recommendations and where they fit within a model’s lifecycle.
Defining project and roles
Accountability structures are in place so that the appropriate teams and individuals are empowered, responsible, and trained for mapping, measuring and managing AI risks. – Govern 2
Analytics is a team sport with data scientists, IT/engineering, risk analysts, data engineers, business representatives and other groups all coming together to build an AI system. Thus, to ensure project success, the roles and responsibilities for this project should be defined and understood by all stakeholders. A clear definition of roles and responsibilities prevents duplication of efforts, ensures all tasks are accounted for and allows for a streamlined process.
Context is established and understood. AI capabilities, targeted usage, goals and expected benefits and costs compared with appropriate benchmarks. Risks and benefits are mapped for all components of the AI system including third-party software and data. – Maps 1, 3 and 4
AI projects should be well-defined and documented to prevent future knowledge gaps and ensure decision transparency. The proposed model usage, the end users, the expected performance of the AI system, strategies for resolving issues, potential negative impacts, deployment strategies, data limitations, potential privacy concerns, testing strategies and more should be documented and stored in a shared location. Documenting the relevant information may increase initial project overhead; however, the benefits of a well-documented and understood model outweigh the initial costs.
Addressing data privacy concerns and potential data biases
System requirements (e.g., “the system shall respect the privacy of its users”) are elicited from and understood by relevant AI actors. Design decisions take socio-technical implications into account to address AI risks. – Map 1.6
Within the training data, organizations should ensure that personally identifiable information (PII) and other sensitive data are masked or removed when not required for modeling. Keeping PII data within the training table increases the risk of private information being leaked to bad actors. Removing PII and following the principle of least privilege also adhere to common data and information security best practices.
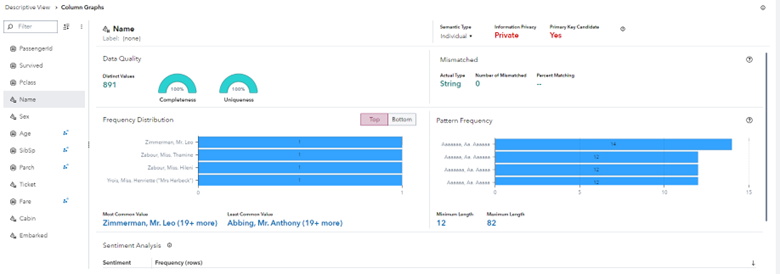
Scientific integrity and TEVV considerations are identified and documented, including those related to experimental design, data collection and selection (e.g., availability, representativeness, suitability), system trustworthiness and construct validation. – Map 2.3
Organizations should review how well the training data represents the target population. Using training data that is not representative of the target population can create a model that is less accurate for specific groups, resulting in undue harm to those groups. It can also create a model that is less effective overall. Furthermore, the intended or unintended inclusion of protected class variables in the training data can create a model that treats groups differently. Even when protected class variables are removed from the training data, organizations must also check the data for proxy variables. Proxy variables are variables that have a high correlation with and are predictive of protected class variables. For example, a well-documented proxy variable is the number of past pregnancies, which is highly correlated with an individual’s sex.
For some use cases, these protected class variables may be important predictors and should remain in the training data. This is most common in health care. Use cases for predicting health risk may include race and gender predictors because symptoms may manifest differently across groups. For example, the differences in heart attack symptoms in men and women are well documented. For other use cases, such as models aimed to predict who should receive a service or a benefit, this can lead to discrimination.
Assessing model performance, fairness and explainability
Evaluations involving human subjects meet applicable requirements (including human subject protection) and are representative of the relevant population. – Measure 2.2
Model performance provides information on how accurately the model can predict the desired event. This helps us understand how useful the model may be for our AI system. Beyond performance at the global level, data scientists need to understand how well the model performs across various groups and classes. A model that performs worse on specific groups may point to a lack of representation within the training data. Additionally, a model that is less accurate on specific groups may cause harm to those groups by making the wrong decision using that model.
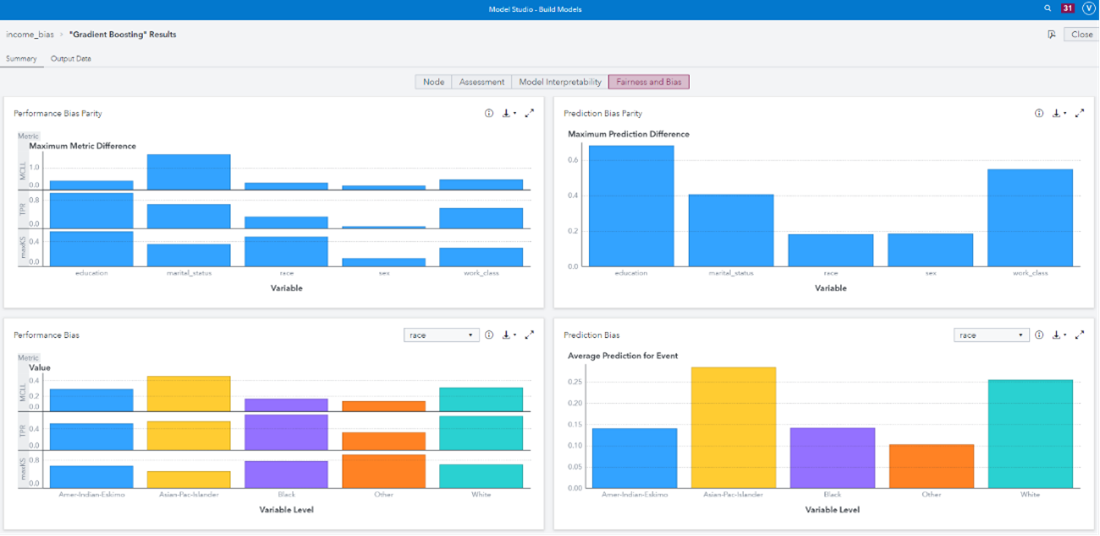
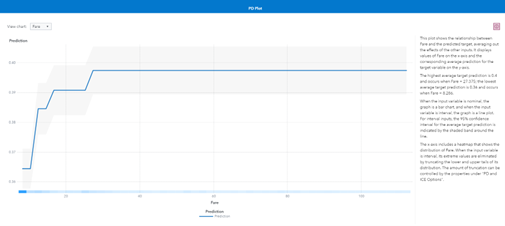
Finally, model explainability helps stakeholders understand how the inputs to a model affect the model’s prediction. By understanding this relationship, data scientists and domain experts can determine if the model captures well-known connections between factors. For example, as the debt-to-income ratio increases, an individual’s probability of default should also increase. Additionally, explainability can provide evidence that a model is fair by demonstrating that a model is using factors that are unrelated to protected group status.
Deploying and monitoring production models
The functionality and behavior of the AI system and its components – as identified in the MAP function – are monitored when in production. – Measure 2.4
All models decay, but models don’t decay at the same rate. Model decay leads to a decrease in model accuracy, so any decision being made using that model will be wrong more often. After a model is deployed into production, it should be monitored so organizations can understand when it is time to take action to maintain their analytical models, whether it be to retrain the model, select a new champion model, end the workflow, or retire the project.
Reoccurring audit
Post-deployment AI system monitoring plans are implemented, including mechanisms for capturing and evaluating input from users and other relevant AI actors, appeal and override, decommissioning, incident response, recovery, and change management. Measurable activities for continual improvements are integrated into AI system updates and include regular engagement with interested parties, including relevant AI actors. – Mange 4.1 and 4.2
The NIST AI Risk Management Framework recommends reviewing the project on a recurring basis to validate that the project parameters are still valid. This provides a regular audit of AI systems, allowing organizations to remove systems no longer in use. The benefit to the organization cannot be understated. Removing systems no longer in use both minimizes the risk of someone leveraging a deprecated model and can even help save on infrastructure costs.
Getting started
Adopting these recommendations may seem daunting, but SAS® Viya® makes it easy and it provides the tooling required to map these recommendations to steps within a workflow. To take it a step further, SAS provides a Trustworthy AI Lifecycle Workflow with these steps predefined. The aim of the workflow is to make NIST’s recommendations easy to adopt for organizations.
Get started with SAS’ Trustworthy AI Lifecycle Workflow
Sophia Rowland, Kristi Boyd, and Vrushali Sawant contributed to this article.






