
Authors: Yan Xu and Brandon Reese
As one of the most prestigious machine learning and AI conferences, NeurIPS 2022 attracted researchers and practitioners from all over the world. They exchanged the latest research ideas and progress in machine learning (ML), deep learning, and AI. For 2022, NeurIPS had a hybrid format. The in-person portion took place in New Orleans, LA from November 28th to December 3rd. The virtual portion spanned December 5th to 9th.
Analytics R&D director Yan Xu and Analytics R&D manager Brandon Reese attended NeurIPS 2022, where SAS made several notable contributions. One was a workshop, co-organized by Yan and Brandon, that concentrated on higher-order optimization in machine learning. The other was Brandon, Yan, and other SAS colleagues participating in and winning fifth place in the EURO Meets NeurIPS 2022 Vehicle Routing Competition.
First, we will share the motivation and the highlights of the higher-order optimization workshop. Then we will discuss the background of the Vehicle Routing competition and what we accomplished during the competition.
Higher-order optimization in machine learning
The higher-order optimization (HOO) workshop at NeurIPS 2022 focused on optimization methods that make use of derivative information beyond gradients. As we know, optimization is one of the key components of model training algorithms in machine learning. For example, when training a supervised model, an optimization problem with a general formula is solved:
minimize \(\frac{1}{n}\sum_{i=1}^n(L(w,x_i,y_i)+\lambda_1||w||_1+\frac{1}{2}\lambda_2||w|\rvert_2^2 )\)
Where n is the number of observations, L is the loss function (can be log loss, mean square error, etc.), w is the model parameter vector, \(x_i\) is input observation i, \(y_i\) is the target output of observation i, and \(\lambda_1\) and \(\lambda_2\) are the regularization hyperparameters.
Currently, first-order methods that only use the first derivative (gradient) dominate in machine learning. This is particularly the case in deep learning because of their simplicity in implementation, low per-iteration computational cost, and strong practical performance. Classical first-order methods include gradient descent (GD), stochastic gradient descent (SGD), and SGD with Momentum. Despite their popularity, first-order methods have their own limitations. They usually need extensive hyperparameter tuning to be performant and might suffer from convergence issues when problems are ill-conditioned.
Higher-order methods like Newton and quasi-Newton (QN) are widely used in many scientific and engineering areas. These would include areas such as operations research, chemical process control, robotics, and manufacturing. Higher-order methods utilize local curvature information to speedup the solution process. They require much less hyperparameter tuning compared to first-order methods. Although generally, they are more applicable to small and medium problems. One challenge of higher-order methods is the high computational cost and memory requirement for computing, storing, and using higher-order information.
Active research and development aim to resolve this challenge. For example, the SAS deep learning toolkit provides QN and second-order methods besides SGD and SGD variants. To further promote higher-order methods and encourage more research in this area, SAS organized a workshop for higher-order optimization algorithms in ML. We collaborated with Jarad Forristal (University of Texas-Austin), Albert Berahas (University of Michigan), Jelena Diakonikolas (University of Wisconsin-Madison), and Martin Takac (MBZUAI). The workshop had three main goals:
- discuss the gap between first-order and higher-order methods
- create an environment where higher-orders methods are fairly considered and compared
- foster healthy discussion of the pros and cons of higher-order methods
Plenary speakers
The organizers of the HOO 2022 workshop invited several renowned researchers as plenary speakers. There were five plenary talks.
Tensor Methods for Nonconvex Optimization presented several higher-order regularization algorithms with a better complexity. Deterministically Constrained Stochastic Optimization introduced novel sequential quadratic optimization methods for solving problems with nonlinear systems of equations and inequalities. A Fast, Fisher-Based Pruning of Transformers without Retraining proposed a post-training framework for transformers that produces a 2x reduction in FLOPs and 1.56x speedup in inference latency. Efficient Second-Order Stochastic Methods for Machine Learning described a few second-order methods including QN and natural gradient that are competitive with first-order methods. Low-Rank Approximation for Faster Convex Optimization showed that many problems, including eigenvalue decomposition and composite convex optimization, can significantly benefit from exploiting low-rank structure.
Papers and awards
The workshop accepted 24 papers, which covered a wide range of topics in higher-order optimization. Topics such as cubic regularization, sequential quadratic programming, distributed Newton methods, and the Levenberg-Marquardt algorithm. To recognize the outstanding accomplishments in this research area, the workshop gave two awards. After a fierce competition, the winners were:
- SAS Best Paper Award: How Small Amount of Data Sharing Benefits Higher- Distributed Optimization and Learning by Mingxi Zhu and Yinyu Ye. In this paper, the authors proposed a novel idea of sharing a small amount of data to speed up distributed higher-order optimization algorithms. The experiment results show a huge speedup when sharing 1% data for least squares regression, and Newton's method outperforms Gradient Descent for logistic regression.
- SAS Best Poster Award: Disentangling the Mechanisms Behind Implicit Regularization in SGD by Zachary Novack, Simran Kaur, Tanya Marwah, Saurabh Garg, and Zachary Lipton. In this paper, the authors studied the reasons why small-batch SGD produces better generalization than full-batch versions. Through extensive experiments, many interesting results were found. For instance, the paper claims that average micro-batch gradient norm regularization recovers small-batch SGD generalization.
All the research presented in the workshop demonstrated that substantial progress has been made in higher-order optimization for machine learning and deep learning. Some of the methods, including second-order quasi-Newton and conjugate gradient, have produced competitive results. The workshop presented the challenges and directions of further improving higher-order methods and making them mainstream methods in machine learning.
Vehicle routing competition
A particularly interesting NeurIPS 2022 component was the EURO Meets NeurIPS 2022 Vehicle Routing Competition. A vehicle routing problem (VRP) finds a set of elementary cycles in a graph that start and end at a common depot, visits all customer nodes once, and satisfies vehicle capacity limits at minimum cost. Figure 1 is an example of using three vehicles to satisfy the demands of 12 customers. The customers are represented by circles in Figure 1.
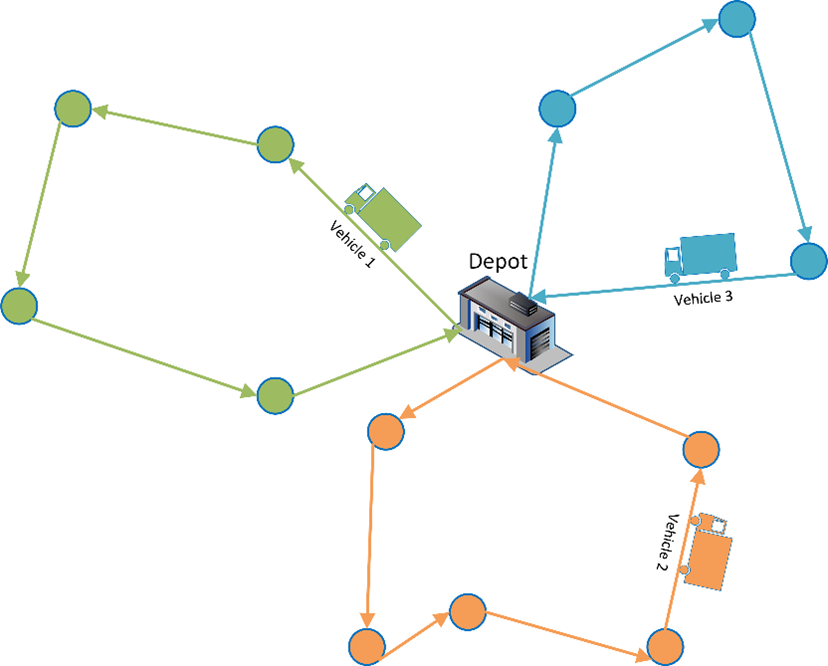
VRP is a classical operations research (OR) problem. Traditionally, the approach is first to formulate it as an optimization problem. Then the problem is solved either exactly or heuristically. Recently, VRP has become a popular topic in the machine learning community because of its enormous business value and significant scientific challenge.
With the purpose of fostering strong collaboration between the OR and ML communities, some researchers organized the competition. The competition involved solving static VRP with time windows (VRPTW) as well as a dynamic variant in which new orders arrive during the day. The competition provided a state-of-the-art VRPTW solver and three strategies for the dynamic variant as a baseline solver. The participants' goal was to try to improve the baseline solver by adding their own ideas. The competition was divided into two phases: the qualification phase and the final phase. The top ten teams in the qualification phase moved to the final phase.
EURO meets NeurIPS 2022 vehicle routing competition results
The VRP competition was well received by both the OR and ML communities. According to the organizers, 150 teams registered, 50 teams submitted, and there were approximately 800 submissions from all teams. Brandon and Yan formed a team, Miles To Go Before We Sleep (MTGBWS). The team also included SAS colleagues Steve Harenberg, Laci Ladanyi, and Rob Pratt. For the qualification phase, MTGBWS achieved first place for the static VRPTW, 13th place for the dynamic variant, and 7th place overall. For the final phase, MTGBWS finished in 4th place for static VRPTW, 7th place for the dynamic variant, and 5th place overall.
The main improvements made by MTGBWS came in two areas: software engineering and new dispatch heuristics. Extensive benchmarking and proper versioning helped the team to readily identify performance bottlenecks. This pushed the results of the static solver to the next level. To improve the dynamic VRPTW, MTGBWS tried several promising ideas. The most effective ones were the two novel dispatch heuristics. Rather than dispatching all optional customers, the dispatch heuristics selected only a subset of them based on the angle or distance with the depot and must-go customers. More details about the new methods and improvements by MTGBWS will be shared in a future post.
Several important lessons were learned from this competition. Regarding the static VRPTW, there is minimal room for improvement in solution quality (measured by objective value) for the competition problem instances (data sets). Classical OR approaches can quickly find high-quality solutions for the static VRPTW on small and medium problem instances provided by the competition. The objective value difference between first place and 10th place was less than 0.1%. On the contrary, the dynamic VRPTW variant offers plenty of opportunities for enhancements across instances of all sizes. The objective value difference between first place and 10th place was more than 9%. Although OR approaches are still effective, ML approaches demonstrated huge potential. The top two teams for the dynamic VPRTW used neural networks in selecting which set of customers to visit next.
Summary
NeurIPS 2022 provided an exciting opportunity for researchers and practitioners to share progress and brainstorm new ideas for advancing machine learning and its related fields. By organizing a workshop and participating in the VRP competition, we learned the latest developments in machine learning and made our own unique contribution to the community.






