When building information extraction models using rule-based approaches, one challenge is discovering the right vocabulary to add to the rule set. What if we could use a similarity metric to discover such words and quickly expand our model coverage? Using such features and Natural Language Processing capabilities like text parsing and information extraction in SAS Visual Text Analytics helps us uncover emerging trends and unlock the value of unstructured text data.
As a data scientist, I want to build a model to extract information about company performance related to ESG metrics. ESG stands for Environmental, Social, and Governance, and these metrics and related strategies go hand in hand with strong financial performance. Investors want to know what ESG areas that companies are focusing on and what improvements they are targeting. I will build a model to discover this information from corporate ESG reports. In this blog post, I will explore how to use SAS Visual Text Analytics and SAS Studio interactively to achieve this goal.
Prepare the data and term list
The data consists of various company reports, such as CRI reports, CSR reports, Env Reports, 10K reports, etc. obtained from their official websites. Before feeding them to the model, the data was pre-processed including file conversion (convert PDF into text), splitting into paragraphs, and removing duplicates and noises. For data variables, I extracted and kept the “Company” and “Year” variables in the data for trend analysis. Finally, I came up with a 26MB-sized dataset, comprised of 157 reports for the companies of interest. I uploaded this data to SAS Data Explorer and visualized it using SAS Visual Analytics.

I have a rough idea of how the data is distributed and want to gain more insights from the text data. For example, what areas of ESG do companies focus on most? How has their reporting changed in the past 5 years?
To answer the questions, I collected a starting list of ESG terms from ESG-related websites.
| Environmental (21) |
environment, environmental, sustainable, sustainability, biodiversity, renewable, green, climate, material, energy, wind, solar, forest, water, waste, carbon, emission, effluent, pollutant, hazardous, disposal |
| Social (26) |
reputation, ethic, ethics, labor, employment, employee, compensation, pay, occupational, health, safety, equity, equal, fairness, transparent, transparency, bias, training, education, diverse, diversity, discrimination, nondiscrimination, freedom, minority, woman |
| Governance (17) |
compliance, regulation, planning, value, economic, financial, business, strategy, performance, risk, innovation, stakeholder, management, process, opportunity, responsible, responsibilityl |
This term list is not large. And the terms like "emission" and "energy" may have hyponyms such as "air emission, co2 emission", "solar energy, wind energy", etc. Also, when checking the terms on the Text Parsing node I found some high-frequency terms that were not on my list, such as "recycle, electricity, security". It seems that this list is not sufficient to cover the breadth of the ESG topic areas. I want to extend the term lists in the model with the relevant ones used in their reports without reading through all the data we collected.
Next, let’s explore how to expand the terms on SAS Visual Text Analytics and SAS Studio.
Find similar words on SAS Visual Text Analytics
The Text Parsing node on SAS Visual Text Analytics finds all the terms in my data and groups the variants of terms via word tokenization and lemmatization. In addition, multiword concepts are detected as noun groups and added to the terms list. Another function, “Find similar”, finds terms in the training data that share a similar context with the target vocabulary and assigns them a similarity score. The similarity scores indicate how likely it is that other terms appear in the same context as a selected term.
Now, I am using this function to expand our vocabulary. The table below shows the similar words for the search term “carbon” sorted by similarity score. We can see that similar words for the word ‘carbon’ contain many carbon-related phrases used in the data, such as “carbon offset, carbon emission, carbon footprint, carbon neutrality” and so on. Also, we can find the words that do not contain “carbon”, such as “footprint, net zero goal, removal solution”, etc., but are somewhat related.

The similar words generated by the “Find Similar” function behind the SAS Visual Text Analytics look helpful although we need to manually filter out some less relevant words.
Can we utilize this function to programmatically get similar words for a word list in batch? Before answering this question, let’s see how it is working behind the scenes. You’ll find the key points in the log for the “Text Parsing” node. Here, the tpAccumulate action outputs a 'parent' table that contains a compressed representation of the sparse term-by-document matrix and a 'term' table that contains the summary information about the terms in the document collection. The tmSvd reduces the dimensionality of the matrix into reduced dimensions using these two tables. Then, the tmFindSimilar action computes similarity scores of terms based on singular value decomposition (SVD) projections.
Find similar words programmatically in SAS Studio
Armed with this understanding, we can move to SAS Studio for programming. Here, you can write SAS or Python programs as you like. I will use Python to demonstrate.
Import libraries and connect to CAS server
Connect to the CAS server of the working environment and import the Python SWAT package to run CAS actions.
# Import libraries from swat import * import pandas as pd # Connect to CAS server host = 'sas-cas-server-default-client' s = CAS(host , 5570, username, password, timeout=1e7) s.sessionprop.setsessopt(caslib='CASUSER', timeout=1e7) # Load CAS action sets s.loadactionset('textManagement') s.loadactionset('textMining') s.loadactionset('textUtil') s.loadactionset('fedSql') s.loadactionset('textParse') |
Generate Document Term Matrix using tmMine action
You can write the program by referring to the code snippet from the log. I used the tmMine action which combines the tpParse, tpAccumulate, and SVD functionality into one. This action helps to make the code more concise.
# Terms and word projection tables are created using the tmMine action s.tmMine(docId='did', text='text', documents=dict(name='ALL_REPORTS_ID'), terms=dict(name='terms', replace=True), parent=dict(name='parent', replace=True), reduce=4, k=160, wordPro=dict(name='svdout', replace=True)) |
Convert Terms table to SAS data frame and create term to termnum map
Because the tmFindSimilar action searches by term ID, we need to get the term IDs for the seed term list. To do this, I converted the ‘terms’ table to a SASDataFrame and created a dictionary to map terms and term IDs. The terms have different term IDs for their different part-of-speech tags. Thus, one term may have more than one term ID.
# Create term-to-termnum map df_terms = s.CASTable(name='terms').to_frame() dict_termnum = {} for term, termnum in list(zip(df_terms._Term_, df_terms._Termnum_)): if term in dict_termnum: dict_termnum[term].add(termnum) else: dict_termnum[term] = set() dict_termnum[term].add(termnum) |
Find top N similar words
Next, I created a findSimilar function that utilizes the tmFindSimilar action to generate the top N similar words for a targeted word. I also have some ideas on narrowing down the candidate terms given that:
- They are likely not stop words
- They are more likely to be nouns, noun phrases, adjectives or verbs
def findSimilar(termid, model='svdout', n=20): s.tmFindSimilar(table=dict(name=model), termnum=termid, nSVD=160, casout=dict(name='casout', replace=True), prefix='col') s.fedSql.execDirect(casout=dict(name='outsimilarTerms', replace=True), query="select a._term_, a._role_, b.* from (select * from terms where _ispar_ != '.' and _keep_='Y' and _role_ in ('N','nlpNounGroup','A', 'V')) a join casout b on a._termnum_ =b._termnum_ ") df_similar = s.CASTable(name='outsimilarTerms',).sort_values(by="_Similar_", ascending=False).to_frame().head(n) return df_similar |
Now, I can use the findSimilar function to generate similar words for a word list and rank them by the times they are recommended. Also, I can exclude the candidates belonging to the seed list and those where the length is shorter than 4 characters.
def findSimilarSet(word_list, dict_termnum): cand_dic = dict() for word in word_list: if word in dict_termnum: termids = dict_termnum[word] for termid in termids: try: df_tmp = findSimilar(termid) for term in list(df_tmp._Term_): if not term in word_list and len(term)>4: if term in cand_dic: cand_dic[term] += 1 else: cand_dic[term] = 1 except: pass cand_dic = dict(sorted(cand_dic.items(), key=lambda item: item[1], reverse=True)) return cand_dic |
All set. Let’s try with the environmental term list.
ESG_terms = ["environment", "environmental", "sustainable", "sustainability", "biodiversity", "renewable", "green", "climate", "material", "energy", "wind", "solar", "forest", "water", "waste", "carbon", "emission", "effluent", "pollutant", "hazardous", "disposal"] cand_dic=findSimilarSet(ESG_terms, dict_termnum) print('%s similar terms generated in total' %len(cand_dic.items())) similar_dic = {"similar_term":[], "recommended_times":[], "term_frequency":[]} for word, freq in cand_dic.items(): similar_dic["similar_term"].append(word) similar_dic["recommended_times"].append(freq) print(pd.DataFrame.from_dict(similar_dic).head(20)) |
Output:
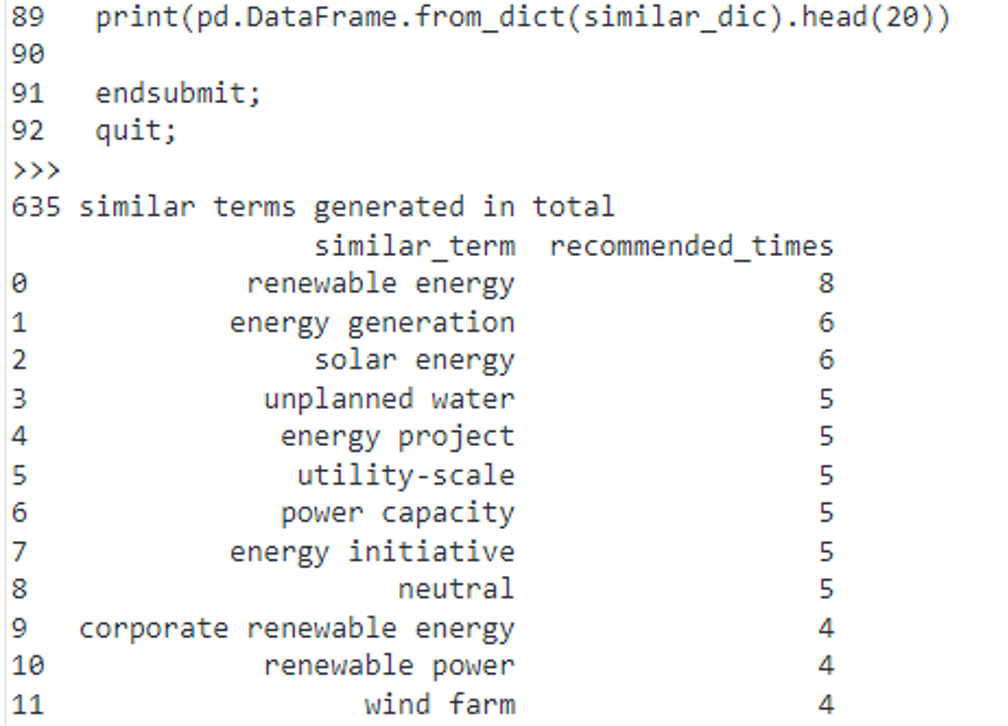
It generated 635 similar words for this term list. “Renewable energy” was recommended 8 times and ‘solar energy’ was recommended 6 times. The table below shows similar words with a frequency greater than 2, which means they are recommended more than two times.
Similar words for Environmental term list (Frequency > 2)
| renewable energy energy generation solar energy unplanned water energy project utility-scale power capacity energy initiative neutral corporate renewable energy renewable power nonhazardous waste |
wind farm solar array solar farm energy match clean carbon reduction carbon emission surface water freshwater water stress landfill final disposal |
non-hazardous nonhazardous hazardous waste air emission sustainability goal electricity demand grid mix geothermal renewable electricity energy deal new wind wind energy |
new solar farm solar power water-related water consumption water withdrawal water usage waste management program carbon offset carbon footprint dioxide carbon negative footprint |
The similar words generated for the environmental word list look promising! In addition, using a word list instead of a single word to generate similar words allows more “important” words to come first. I only need to review the suggested vocabulary list and filter out some irrelevant words.
Similarly, I ended up with 717 and 542 similar words for my Governance and Social term list respectively.
Information extraction model and visualization
Now I have a richer vocabulary after a quick check and filtering out irrelevant words. Next, I want to build an information extraction model on the SAS Visual Text Analytics Concept node to continue the exploration. For such unstructured text data without any labels, the LITI rule-based model is a good choice. I can also take advantage of the predefined concepts such as nlpPercent, nlpMoney, and nlpMeasure to help identify ESG-related metrics. Then, create fact rules using ESG terms and metrics concepts. With expanded ESG-related terms, the model returned 1.7k more fact matches. This number wasn't noticeable since the refined terms didn't contribute much to the number. For example, the "energy" initially returned 825 results, while the refined model only returned 26 more results. But what I see in the results are more granular terms, such as "renewable energy, clean energy, solar energy, carbon-free energy", etc.
After some post-processing of the results, I was ready to create a report in Visual Analytics. On the left part, I added a bar chart with the frequency of company on the ESG report and a pie chart with the frequency of ESG category. On the right part, I added a line chart to show how their reports changed over the years, and a word cloud with the frequency of ESG terms. Then connected these two charts with the bar chart and pie chart. Also, I added and connected a list table with the text, which was the ESG category, terms and metrics arguments, and the matched text span.
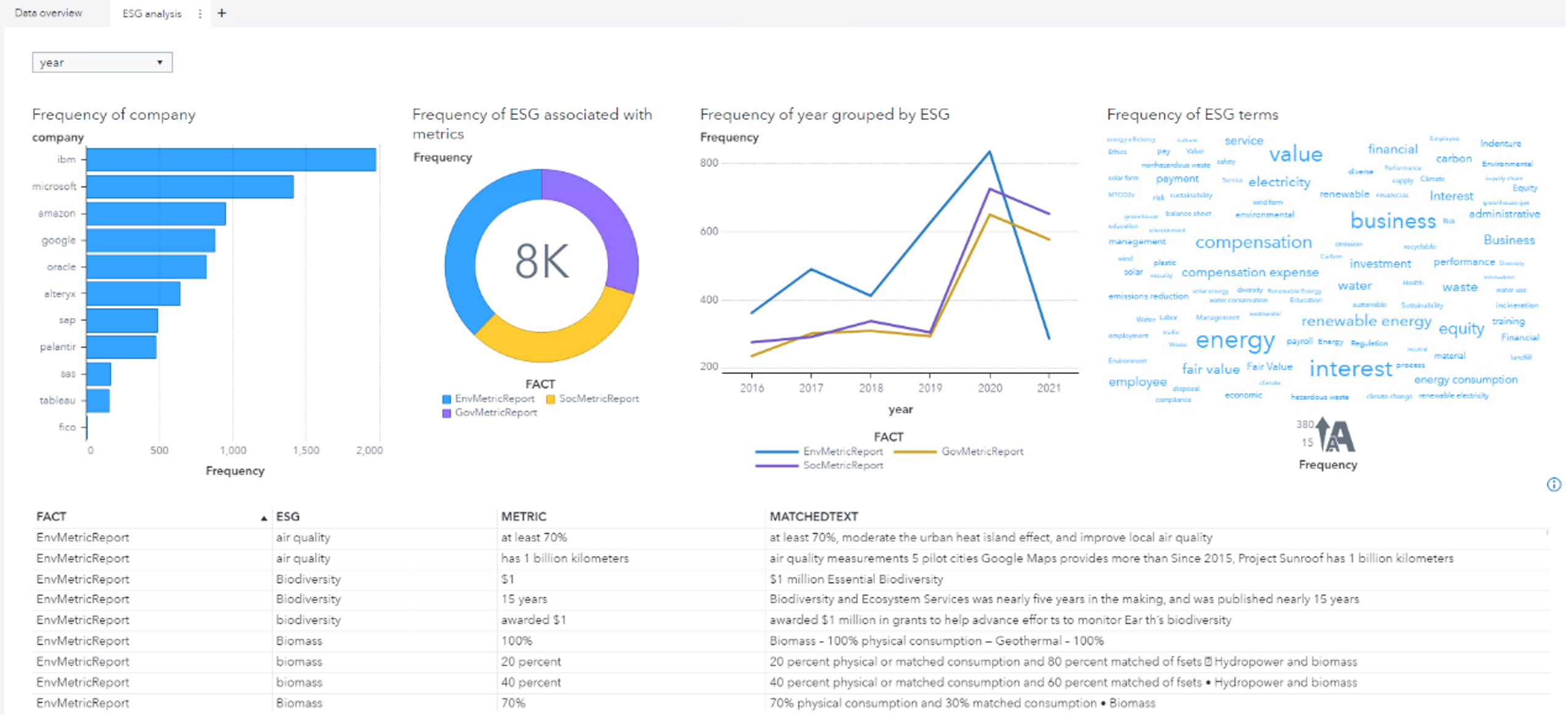
Based on the visualization, IBM and Microsoft reported the most ESG-related metrics. This is somewhat consistent with the data distribution. When clicking on the companies in the bar chart to view the details, I found IBM focused most on "energy" and "electricity" and Microsoft focused most on "business" and "indenture". Also, I can see how the reports changed in the past 5 years from the line chart. By clicking on the ESG pie chart, I can check which areas the companies are most concerned about in each category.
Summary
This blog post aimed to provide a strategy for expanding terms using the SAS similar word detection technique to facilitate model development. The exploration with ESG data showed this approach works well in expanding domain-related vocabularies even on a relatively small amount of data. When I experimented with different data volumes with this method of term expanding, it showed that larger data is more likely to yield better results. Moreover, you can consider such extensions by leveraging open-source pre-trained word embedding models that are trained on large corpora. For expanding a word list that is not domain-related, for example, the expansion of a sentiment word list, using a word embedding model trained on more extensive data will achieve better results. To leverage the pre-trained models, you only need to import the pre-trained word embedding to SAS Data Explorer and use the example code shown above to find similar words. My experiments showed that this method also works well in expanding sentiment vocabularies. Try it out on your project and let us know what you find!
Learn more
- Check out additional documentation on corpus analysis and for SAS Visual Text Analytics.
- Keep exploring by checking out the ebook “Make Every Voice Heard with Natural Language Processing” or try SAS Viya for free.






