
This post, written by Radhikha Myeni and Jagruti Kanjia, will demonstrate how easy it is to build and deploy a machine learning pipeline by using SAS and Python. The Model Studio platform provides a quick and collaborative way to build complex pipelines by dragging and dropping nodes from a web-based interface. These pipelines would typically include feature engineering, model building, autotuning of hyperparameters, model interpretation, and model comparison. The capability to fully integrate open-source software into these pipelines adds flexibility and extensibility. This enables data scientists to expand their SAS toolbox with additional technologies to solve their business problems.
We will use examples to showcase pipelines that contain SAS-based preprocessing followed by a Python model or Python-based preprocessing followed by a SAS model. To deploy these models, the pipelines are registered to SAS Model Manager and published to various destinations like SAS Micro Analytic Service and Cloud Analytic Server (CAS).
Model Studio encompasses other types of pipelines (Forecasting, Text Analytics) but the focus here is on the Open Source Code node. This node can execute Python and R scripts in a data mining and machine learning pipeline. In the past, you could easily incorporate Python code into the pipeline by using the Open Source Code node. That pipeline could then be compared with other pipelines in the project. However, you could not deploy the pipeline into production. Starting with the 2021.1.1 release of SAS Viya 4, the production capabilities of these pipelines were incrementally added. There is full support to register these pipelines to SAS Model Manager in the 2021.1.4 release. Note that this registration capability applies to Python language although support for R language will be coming soon.
User interface changes
First, we will show you the user interface components needed to support Python code deployment in a pipeline. Figure 1 displays the new Scoring Code pane in the code editor of the Open Source Code node. It was added in the 2021.1.1 release. It enables you to provide the score Code in addition to the train Code.
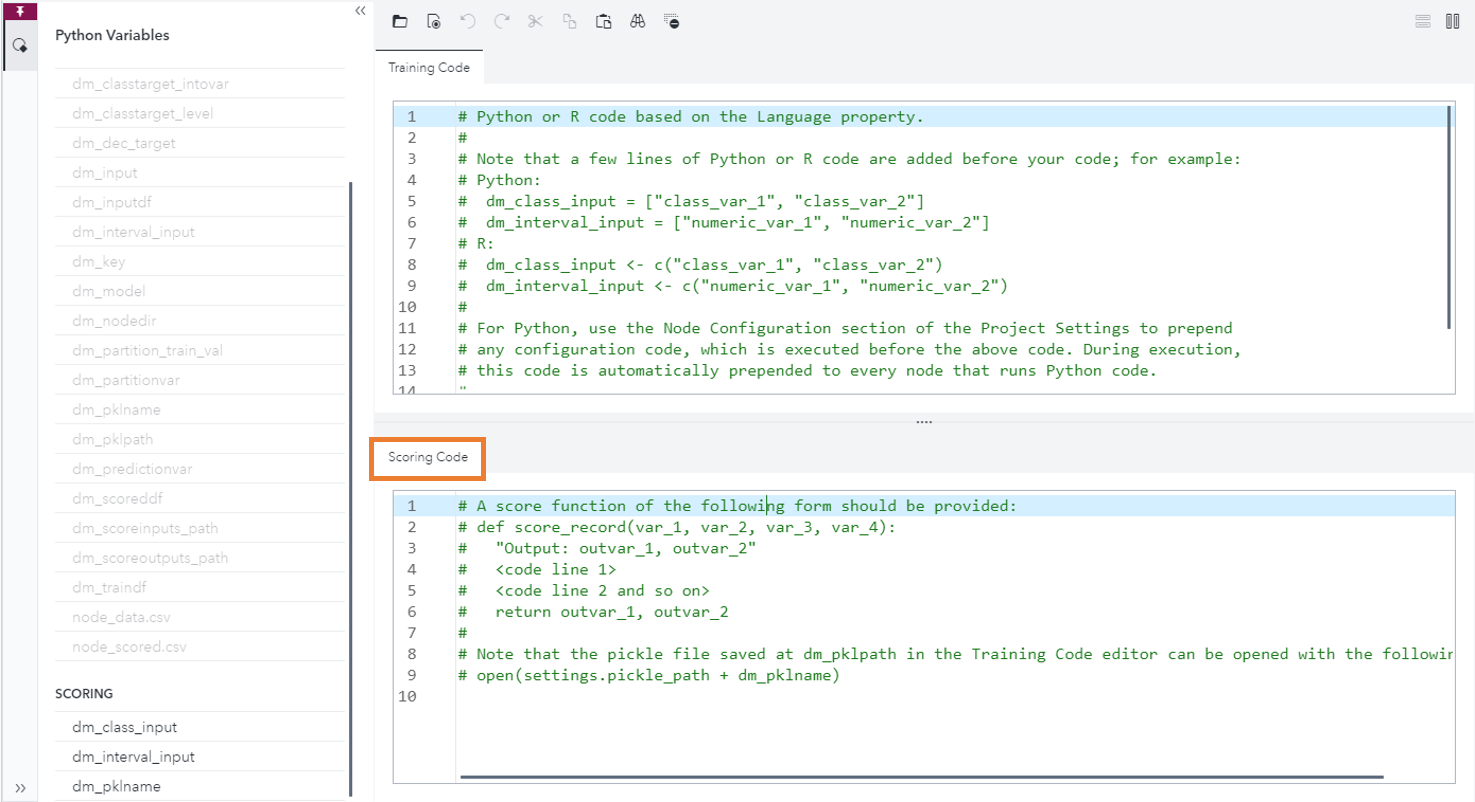
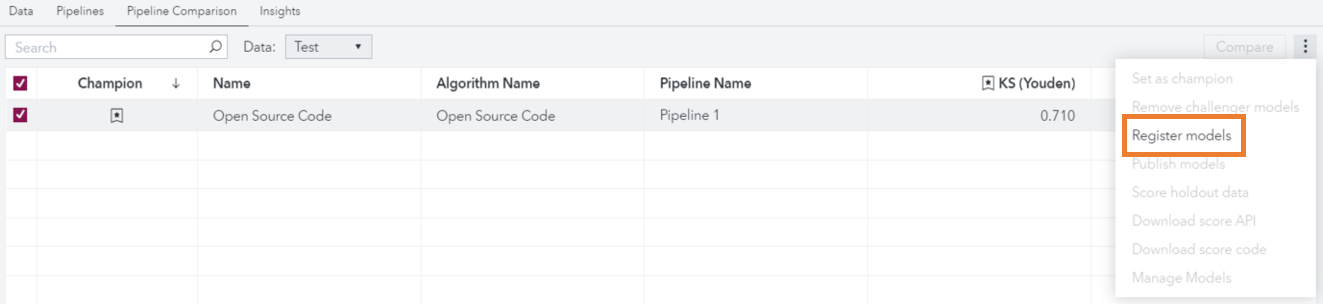
Figure 2 displays the Register models button for a Python model that is included in the Pipeline Comparison tab. This button allows you to register the pipeline to SAS Model Manager. It was not available for open-source models before the 2021.1.1 release.
Examples
Now let us look at three examples dealing with how SAS and Python can be combined in the preprocessing and the supervised learning lanes of the pipeline. The code is in the GitHub repository sas-viya-dmml-pipelines in the open_source_code_node folder. You will find detailed steps on setting up and running these examples in the README files of the corresponding folders.
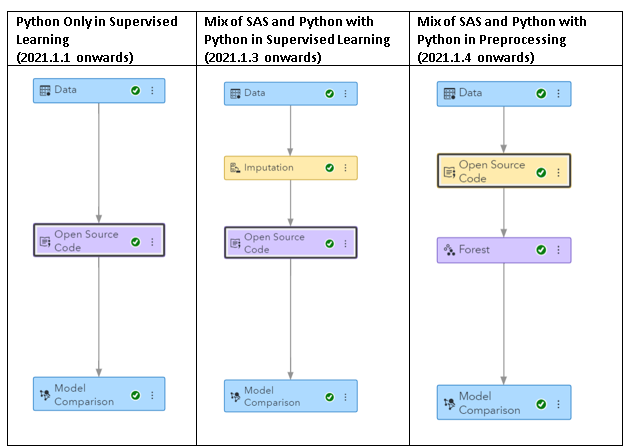
Table 1 showcases various example pipelines and states the release numbers where those capabilities are available. Here is a brief description of the steps included in each pipeline.
- The “Python Only in Supervised Learning” example does imputation of missing values, one-hot encoding of class inputs and builds a RandomForestClassifier (from sklearn package) by using Python.
- The “Mix of SAS and Python with Python in Supervised Learning” example does imputation of missing values by using the Imputation node while one-hot encoding of class inputs and model building are done in Python.
- The “Mix of SAS and Python with Python in Preprocessing” example does imputation of missing values in Python while model building is done by using the Forest node. The one-hot encoding of class inputs is skipped here as the Forest node and other SAS nodes in general support class and interval inputs natively.
Prerequisites
The following Kubernetes overlays need to be applied to the SAS Viya 4 environment before running the examples.
- Apply sas-open-source-config overlay (this example needs only the Python part that is under the python directory of the overlay)
- Apply sas-microanalytic-score astores overlay
Data
The Home Equity (HMEQ) data set is used for all the examples. It contains loan performance information for 5,960 home equity loans with a binary target variable (BAD) indicating whether the applicant eventually defaulted or not. The outcome occurs in 1,189 cases or 20% of the data. For each applicant, 12 input variables were recorded. The data set has missing values and contains class and interval inputs. So we will impute missing values and one-hot encode class inputs when necessary.
Rules when writing score code (in Scoring pane)
When registering pipelines to SAS Model Manager, you will need to provide score code (as a Python function) in addition to train code. The score function should be of the following form:
def score_record(var_1, var_2, var_3, var_4): "Output: outvar_1, outvar_2" <code line 1> <code line 2 and so on> return out_1, out_2 |
The first line of the score function should contain the "Output: outvar_1, outvar_2" string listing the return variables names in the order they will be returned when the function is called.
If a pickle file is saved in dm_pklpath in the Training Code pane of the code editor, it can be accessed in the Scoring Code pane with the following Python code:
open(settings.pickle_path + dm_pklname) |
Here is a full sample of the score code from the “Mix of SAS and Python with Python in Supervised Learning” example:
import pickle import numpy as np import pandas as pd with open(settings.pickle_path + dm_pklname, 'rb') as f: ohe = pickle.load(f) model = pickle.load(f) def score_method(IMP_DELINQ, IMP_DEROG, IMP_JOB, IMP_NINQ, IMP_REASON, IMP_CLAGE, IMP_CLNO, IMP_DEBTINC, IMP_MORTDUE, IMP_VALUE, IMP_YOJ, LOAN): "Output: P_BAD0, P_BAD1, I_BAD" record = pd.DataFrame([[IMP_DELINQ, IMP_DEROG, IMP_JOB, IMP_NINQ, \ IMP_REASON, IMP_CLAGE, IMP_CLNO, IMP_DEBTINC, IMP_MORTDUE, \ IMP_VALUE, IMP_YOJ, LOAN]],\ columns=dm_class_input + dm_interval_input) rec_intv = record[dm_interval_input] rec_class = record[dm_class_input].applymap(str) rec_class_ohe = ohe.transform(rec_class).toarray() rec = np.concatenate((rec_intv, rec_class_ohe), axis=1) rec_pred_prob = model.predict_proba(rec) rec_pred = model.predict(rec) return float(rec_pred_prob[0][0]), float(rec_pred_prob[0][1]), float(rec_pred[0]) |
Note that complex objects in Python are saved as pickle files and used in score code. The score code for SAS nodes is saved in the SAS Data Step code (DS1). Or it's saved as a SAS analytic store binary (ASTORE) depending on the complexity of that node. The score code for the entire pipeline is then constructed by stacking these individual parts by using DS2 (a SAS advanced programming language).
Scoring in SAS Model Manager
The last step in all three examples is registering the pipeline to SAS Model Manager. You can then choose to score new data from the Scoring tab within SAS Model Manager itself. Or you can publish the pipeline to one of the supported destinations. To score new data from the Scoring tab, you need to request your SAS administrator to add the current user to CASHostAccountRequired (CHAR) group.
As a CHAR user, you can select the “New Test” button from the Scoring tab of the registered project, choose the model and input table from the pop-up window shown in Figure 3 and select the Run button.
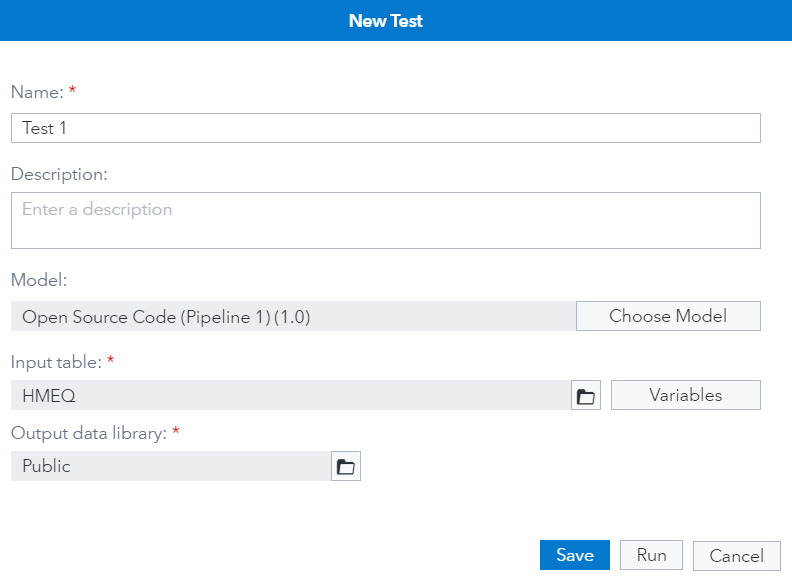
Figure 4 shows the test execution entry in the Scoring tab after the test run completes. Verify that the pipeline scored successfully by using the Status column and view output and log by clicking the table icon in the Results column.

Machine learning pipeline using SAS and Python summary
The Model Studio platform enables data scientists to intuitively build and deploy machine learning pipelines in a web-based interface by drag and drop of nodes. Starting with SAS Viya release 2021.1.4, Python can also be added to this mix. This allows diverse and comprehensive pipelines to be easily trained and deployed with just a few clicks. The ability to mix SAS and Python technologies allows data scientists to fill the gaps in their capabilities. It also provides a variety of ways to solve their business problems.
We hope this gives you an overview of how to build and deploy a machine learning pipeline using SAS and Python. The next step would be trying out the examples on GitHub so you can take this knowledge further. More examples will be added to GitHub in the near future, so keep an eye on the repo!
LEARN MORE | Integrate SAS with Python LEARN MORE | SAS Viya





