The model management process, which is part of ModelOps, consists of registration, deployment, monitoring and retraining. This post is part of a series examining the model management process, orchestrated through the Model Manager (MM) APIs. The focus of part one is on model registration, specifically on using the APIs from Python to register a Python model into MM. This piece is for users familiar with MM, but not with using the APIs. Subsequent posts cover scoring and monitoring open-source models and integrating with CI/CD pipeline tools.
SAS Model Manager allows for the management of both SAS and open-source models in a single, centralized repository. This is normally achieved through an intuitive graphical user interface (GUI), but for open-source users, a more favorable method is accessing MM through its APIs. APIs, which stands for Application Programming Interface, are a software layer between MM and open-source clients to allow those clients to access the MM functionality.
Why? By using the Model Manager APIs:
- Model management seamlessly integrates within open-source notebooks and IDEs.
- Customers can build custom applications on-top of the MM functionality.
- SAS Model Manager is embedded within advanced ModelOps processes involving DevOps and CI/CD.
Making API Requests in Python
As stated above, the API provides the client (in this case, Python) a way to access the MM functionality. For example, if you want to create a new model, instead of clicking “New Model” in the GUI, you could execute the following Python code:
create_model = requests.post( url = "http://yourViyaServer.com/modelRepository/models", headers = {"Authorization": auth_token, "Content-Type": "application/vnd.sas.models.model+json"}, data = {"name": "Python_GradientBoost","projectId": project_id} } |
This preceding code represents an API request, where you make a call to the Viya server to interact with a specific resource. With MM, possible resources include models, model projects, repositories, performance definitions and so on. While this post will not detail specific API concepts – understand that as part of the API request you normally provide the following information:
- URL of the API resource – this is the Viya server URL followed by the API endpoint that indicates what resource we are interacting with.
- API Headers – the metadata of the API request. This can be quite detailed, but the most common header information provided includes the Authentication method (to authenticate the request) and the Content-Type (which is the data type of the resource).
- API Body Data – the data of the API request. For this request, this is the metadata for the model we want to create.
This all brings up the following questions: How to determine what API endpoint to use? What header information to fill out? And what information to send in the body? You may already notice coding all of this with each request gets laborious. So what if these API requests could be simplified?
This is where the sasctl comes in. sasctl is a Python library available on the sassoftware Github page which simplifies making SAS Viya API requests in Python. Using sasctl, the above API request to MM simplifies to:
from sasctl import model_repository as mr create_model = mr.create_model({"name": "Python_GradientBoost"}, project=project_id) |
The user doesn’t have to code any of the required API information other than provide the model metadata they wish to submit. Let's explore where the magic occurs.
Documentation – How do I know what to use?
How do we know what sasctl function to use? Additionally, if you weren’t using sasctl and instead coding from scratch, how do you know what API endpoint to use, or what header information and what metadata to provide? This is where the SAS Viya API documentation comes in and is located on developer.sas.com.
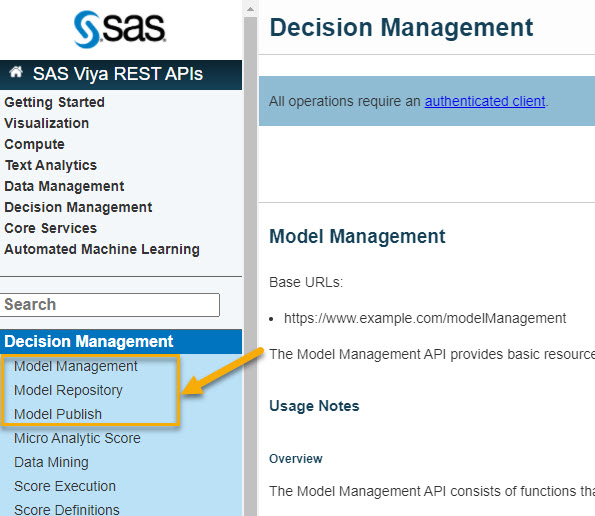
The MM APIs fall under the Decision Management section. There, the MM API functions are grouped according to the various microservices responsible for their operation. Understanding what microservice is responsible for what particular MM functionality tells you which API request to make:
- modelManagement – contains services related to performance monitoring and workflow interaction
- modelRepository – contains services related to models, projects and repositories
- modelPublish – publishing models and managing publishing destinations
For a more thorough understanding sasctl, refer to the sasctl documentation. You may also want to refer to the Jon Walker's SAS Global Forum paper Manage Model Development via a Python IDE. Just as with the APIs, sasctl functionality is grouped according to the relevant microservices. Since this post covers only registration, we will interact with the modelRepository microservice.
Register a Python model via Model Manager API
Let’s now cover this process using sasctl rather than coding the APIs from scratch. The step-by-step process is functionally similar to the performed in the GUI – except now with code.
In the GUI, these steps are:
- Authenticate
- Create new Model Project in Model Repository
- Update Model Project variables and metadata
- Create new Model
- Upload Model contents (training code, scoring code, etc.)
Using sasctl, the steps are:
- Import sasctl and Authenticate
- Create a new Model Project in Model Repository
- Retrieve Model Repository UUID
- Create new Model Project using Model Repository UUID
- Update Model Project variables and metadata
- Create new Model
- Upload Model contents (training code, scoring code, etc.)
It’s important to note sasctl has a function called sasctl.register_model(), which performs this entire sequence as a single Python function as a matter of convenience for pure model registration. In an example, let's unpack what’s happening at each individual step of the registration process as an individual API request.
In this example, the model we want to register is a Gradient Boosting model from scikit-learn has already been trained in Jupyter Notebook. This model has several files associated with it:
- training code (gboost_train.py)
- scoring code (gboost_score.py)
- Python pickle – this is a binary file containing the model logic used as part of the score code (gboost_V3_6_8.pkl)
- requirements file (requirements.txt) that contains the version information for the packages needed to create the model
As part of our model registration, we are going to import these files as model content. Depending on the model complexity and business problem, there might be more files and different types, but these are the files generally associated with a Python model. Below are examples of each file.
Training code
%%writefile artefacts/gboost_train.py from sklearn.metrics import accuracy_score from sklearn.model_selection import train_test_split from sklearn.ensemble import GradientBoostingClassifier import pandas as pd def train(input_df, warmstart=False): """ :param input_df: pandas.DataFrame warmstart: True/False to trigger warm_start option :return: sklearn.GradientBoostingClassifier """ target = input_df.columns[0] class_inputs = list(input_df.select_dtypes(include=['object']).columns) # impute data input_df = input_df.fillna(input_df.median()) input_df['JobType'] = input_df.JobType.fillna('Other') input_df_ABT = pd.concat([input_df, pd.get_dummies(input_df[class_inputs])], axis = 1).drop(class_inputs, axis = 1) df_all_inputs = input_df_ABT.drop(target, axis=1) # Create training and validation sets X_train, X_valid, y_train, y_valid = train_test_split( df_all_inputs, input_df[target], test_size=0.33, random_state=54321) # Build sklearn Gradient Boost gb = GradientBoostingClassifier(random_state=54321, warm_start=warmstart) gb.fit(X_train, y_train) return gb |
Scoring code
%%writefile artefacts/gboost_score.py import pickle import pandas as pd def score(input_df, model): """ :param input_df: pandas.DataFrame model: scikit-learn.GradientBoostingClassifier :return: pandas.DataFrame """ inputs = input_df.drop(['Default'], axis=1) proba = model.predict_proba(pd.get_dummies(inputs.fillna(inputs.median()),columns=['LoanReason','JobType'])) return pd.DataFrame(proba, columns=('P_Default0', 'P_Default1')) |
Pickle File
In Jupyter Notebook, you can use the built-in %%writefile magic functionality to write cell contents as text files, allowing us to save the training and scoring code as files to import later. Here is how to create the pickle file:
modelPklName = 'gboost' tool_version = str(sys.version_info.major)+'_'+str(sys.version_info.minor)+'_'+str(sys.version_info.micro) pklFileName = modelPklName+'_V'+tool_version+'.pkl' import pickle with open(path+pklFileName, 'wb') as fp: pickle.dump(gb, fp) fp.close() |
Requirements file
The requirements.txt file is normally written out, but here we create it with Python code:
package_list = ['pandas', 'numpy', 'sklearn'] path = os.getcwd()+'/artefacts/' with open(path+'requirements.txt', 'w') as fp: for package_name in package_list: package = sys.modules[package_name] if package_name == 'sklearn': package_name = 'scikit-learn' fp.writelines([f'{package_name}=={package.__version__}\n']) |
sasctl step-by-step
sasctl has built-in utility functions helping create some of these files automatically as a matter of convenience; however, users may want to create them manually if the model has more complex requirements or more specific customization based on the business problem.
Import sasctl and authenticate to Viya
Now you can start the registration process. In Python, import the sasctl module and the relevant functionality. Next, authenticate Jupyter Notebook with SAS Viya by starting a sasctl session:
from sasctl import model_repository as mr s = Session(server,user,password) |
The Python variable 's', is the sasctl session object and contains our authentication token for subsequent API requests. If you wish, use s.get_token to retrieve the raw auth token.
Retrieve Model Repository UUID
To create a model, you first need to create a new model project. To do that, specify a model repository for the new project. This requires retrieving the Universally Unique Identifier (UUID) of the chosen repository using the API. The UUID retrieval code is:
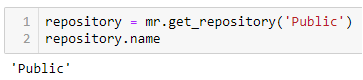
repository = mr.get_repository('Public') |
The returned Python variable contains the API response from the request above. The API response contains information about the model repository including the UUID required. If you return the variable as a dictionary, you can see the full API response.
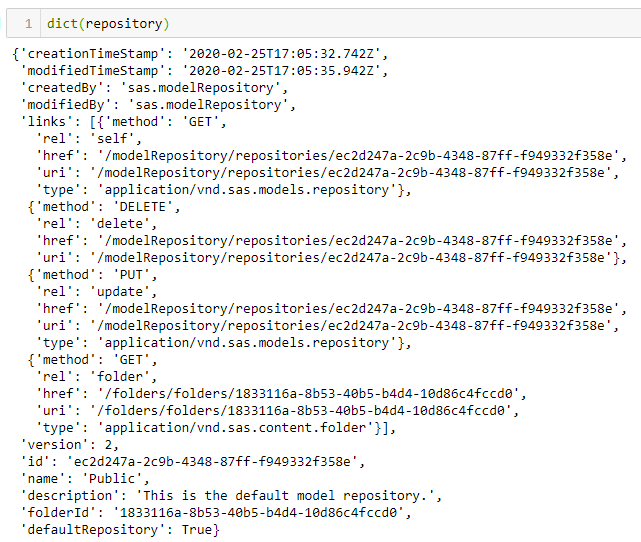
Access the attributes by interacting with the Python variable as a dictionary, like so:
This method of creating the model project follows the same steps performed in the GUI, just with code.
Create Model Project in Model Repository
Next, create the model project. Specify the model project metadata and provide the repository information you retrieved from the previous API call.
project = mr.create_project( { 'name':'Python_Retrain_API', 'description':'Project demonstrating management of open source models in Viya', 'function':'classification', 'targetLevel':'binary', 'variables': [ {"name": "CredLineAge","role": "Input","type": "Decimal","length": 12}, {"name": "CredLines","role": "Input","type": "Decimal","length": 12}, {"name": "DebtIncRatio","role": "Input","type": "Decimal","length": 12}, {"name": "DerogatoryMarks","role": "Input","type": "Decimal","length": 12}, {"name": "LoanValue", "role": "Input","type": "decimal","length": 12}, {"name": "MortgageDue","role": "Input","type": "decimal","length": 12}, {"name": "Inquiries","role": "Input","type": "decimal","length": 12}, {"name": "HomeValue","role": "Input","type": "decimal","length": 12}, {"name": "YearsOnJob","role": "Input","type": "decimal","length": 12}, {"name": "P_Default0","role": "Output","type": "Decimal", "description":"Probability of not defaulting"}, {"name": "P_Default1","role": "Output","type": "Decimal", "description":"Probability of defaulting"}] }, repository ) |
Update Model Project variables and metadata
If you want to update any of the model project metadata information, you can interact with the "project" Python variable as if it were a dictionary to make any changes. Then submit the edited variable with another API request:
project['targetVariable'] = 'Default' project['eventProbabilityVariable'] = 'P_Default1' project['classTargetValues'] = '1,0' project['targetEventValue'] = '1' project_update = mr.update_project(project) |
Create Model
You can now create a model representation in the model project as follows:
model = mr.create_model( {'name':'Python_GradientBoost','trainCodeType':'Python', 'scoreCodeType':'Python'}, project, algorithm='scikit-learn.GradientBoostingClassifier', modeler='Thierry Jossermoz', function='classification', tool='Python 3' ) |
Import Model Content
After you create the project, attach the model content to the model, and assign a file role specifying the file type. In this instance, use the Python open() function to read the data and send it through the API:
trainfile = mr.add_model_content( model, open(os.getcwd()+'/artefacts/gboost_train.py', 'rb'), name='gboost_train.py', role='train' ) scorefile = mr.add_model_content( model, open(os.getcwd()+'/artefacts/gboost_score.py', 'rb'), name='gboost_score.py', role='scoreResource' ) requirements = mr.add_model_content( model, open(os.getcwd()+'/artefacts/requirements.txt', 'rb'), name='requirements.txt', role='documentation' ) python_pickle = mr.add_model_content( model, open(os.getcwd()+'/artefacts/'+pklFileName, 'rb'), name=pklFileName, role='python pickle' ) |
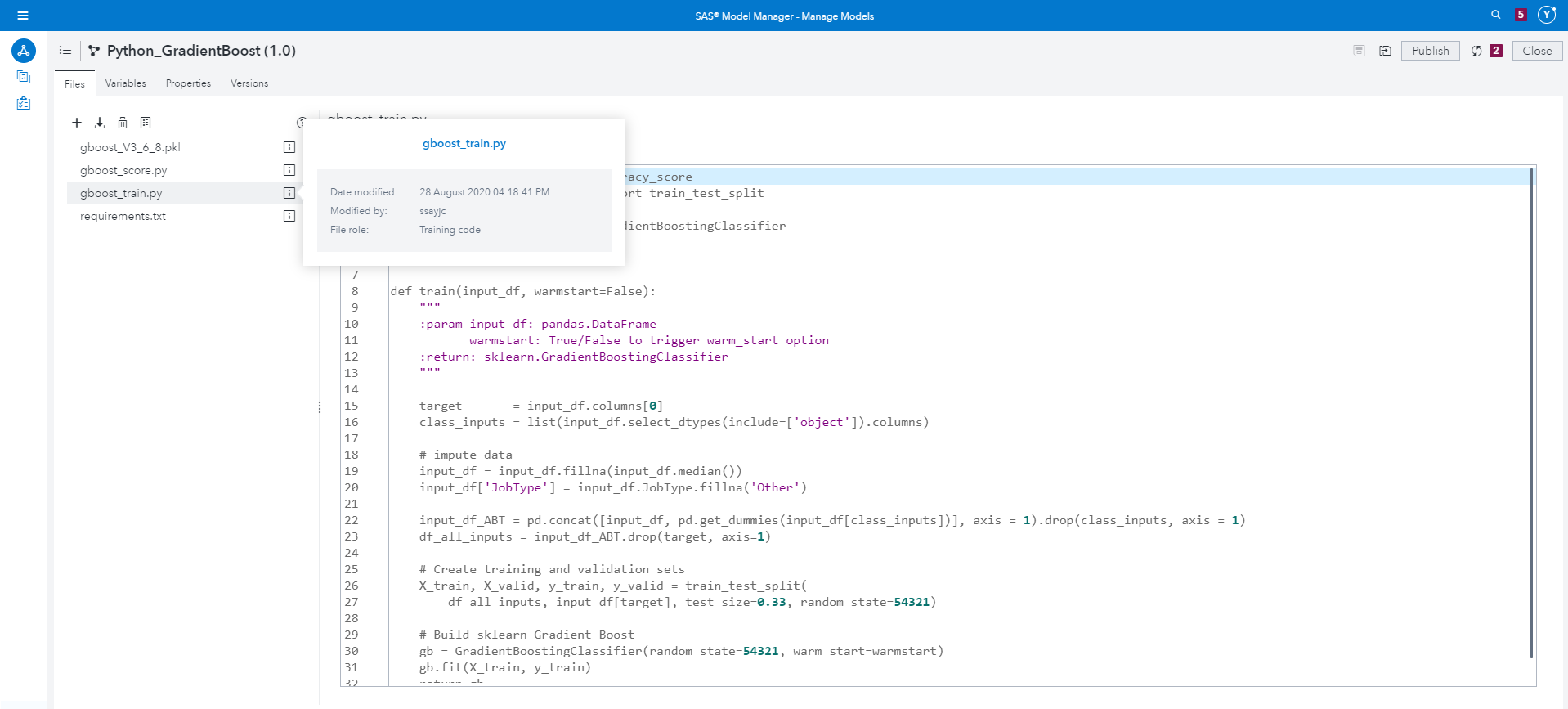
In Model Manager, you can verify the model project and model creation with the correct metadata and content.
Summary
This blog post introduced the concepts behind the Model Manager APIs and how to use them, as well as a step-by-step process for registering a Python model into Model Manager through the APIs.
Thanks for reading! Hopefully you found this blog post helpful in understanding the MM APIs. Remember, this is part one of the series. Look for the next entries which cover:
- Scoring and monitoring your open-source model
- Integrating with CI/CD pipeline tools






