SAS Visual Text Analytics 8.4 (VTA) on SAS Viya 3.4 uses Machine Learning algorithms to autogenerate Concepts and Facts. In this blog, I will use the new autogenerate functionality to find insights on the problem of Human Trafficking. Public awareness of Human Trafficking is a way to continue fighting this problem.
Tom Sabo and Adam Pilz presented at the 2018 SAS Global Forum (SGF) an outstanding paper titled, Using SAS® Text Analytics to Assess International Human Trafficking Patterns. They identified common themes across the reports, used LITI rules to extract relationships between source and destination countries involved in trafficking and built a geographic network diagram that covers the types of trafficking as well as whether the countries involved are invested in addressing the problem.
In this blog, I don’t attempt to reproduce their paper but have three primary objectives:
- To increase awareness on the terrible problem of Human Trafficking
- To show how to use SAS Visual Text Analytics 8.4’s Machine Learning features of auto-generation of Concepts and Fact rules
- To show how to work with a new VTA 8.4 feature called the Sandbox. Also, this blog will be used as an introduction to an exercise for the VTA course that I teach
Tom Sabo shared with me the 63,648 rows of sentence level data he used to prepare his SGF paper. Data was obtained from the U. S. Department of State Trafficking in Persons (TIP) reports from 2013-2017.
VTA is the SAS offering designed to effectively extract insights from unstructured data in large scale. Because VTA easily processes big data, I included all the 63,648 rows in the analysis I show in this blog. For this reason, some results might differ from the ones presented in the Pilz and Sabo paper.
Sabo cites: “The International Labour Organization estimates that there are 20.9 million victims of human trafficking globally, and that forced labor and human trafficking generates 150 billion dollars in illicit gains annually. Of the 20.9 million victims, 26% are children, and 55% are women and girls.”
Because of my background in Operations Research and Analytics, I found the paper Overcoming Human Trafficking via Operations Research and Analytics: Opportunities for Methods, Models, and Applications by Konrad, Trapp and Palmbach informative and insightful. From this paper, I will be referring the following:
- Human Trafficking is defined as holding a person in involuntary servitude (domestic, labor or sexual servitude) by force, coercion or debt bondage.
- The “3P” paradigm defines broad categories for activities to fight human trafficking: Prevent, Protect, and Punish.
- Data that could be used to fight this problem has several limitations, a critical one is that criminal data is collected by authorities and institutions, while data on victims is collected by non-governmental organizations (NGOs) and service providers. Because each collects data for its own purposes, data is fragmented, dispersed and not shared.
The co-authors Van Scotter, McGaugh, McManus, Agrigento, and Kari of this paper Human Trafficking Research: The Persistence and Movement of Phone Numbers in Escort Ads (SASGF 2019-3972) describes how text analytics was used to identify traffickers’ regular patterns of behavior with the goal of beginning to understand these patterns and predict them in the future.
Rule development in the Concepts node
I will describe the process that I followed and how I used the new VTA 8.4 functionality in the Concepts Node. There are no data requirements to use this functionality. The next paragraphs briefly describe them: a) the Sandbox tab, b) the Create CLASSIFIER rules, c) the Autogenerate Concept rules, and d) the Autogenerate Fact rules.
To enable the automatic concept rule generation, from the Pipelines tab, select the Concepts node and checkmark both boxes as the screenshot below shows:
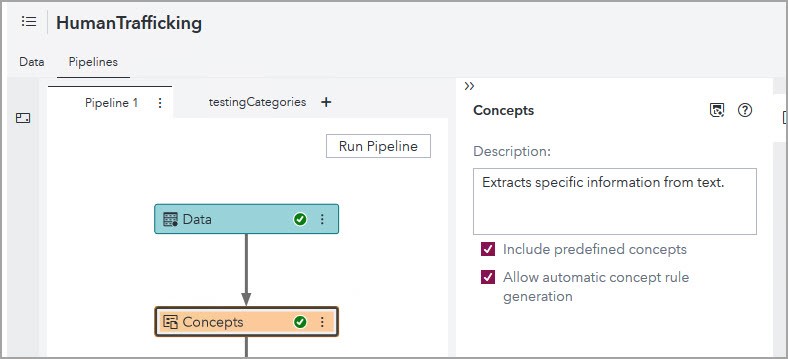
The Sandbox tab
Usually one writes the rules associated to a Custom Concepts in the Edit Concept tab. However, writing the rules in the new Sandbox tab allows for faster testing since only the rules in the Sandbox are compiled into the model instead of all the custom concepts rules in the Concept Node. You can see matches just as if you would have run the entire model.
As the Sandbox is more of a playpen concept, you must copy any rules you like from the Sandbox tab to the Edit Concept tab. The screenshot below shows concept autogenerated rules and their matching documents.
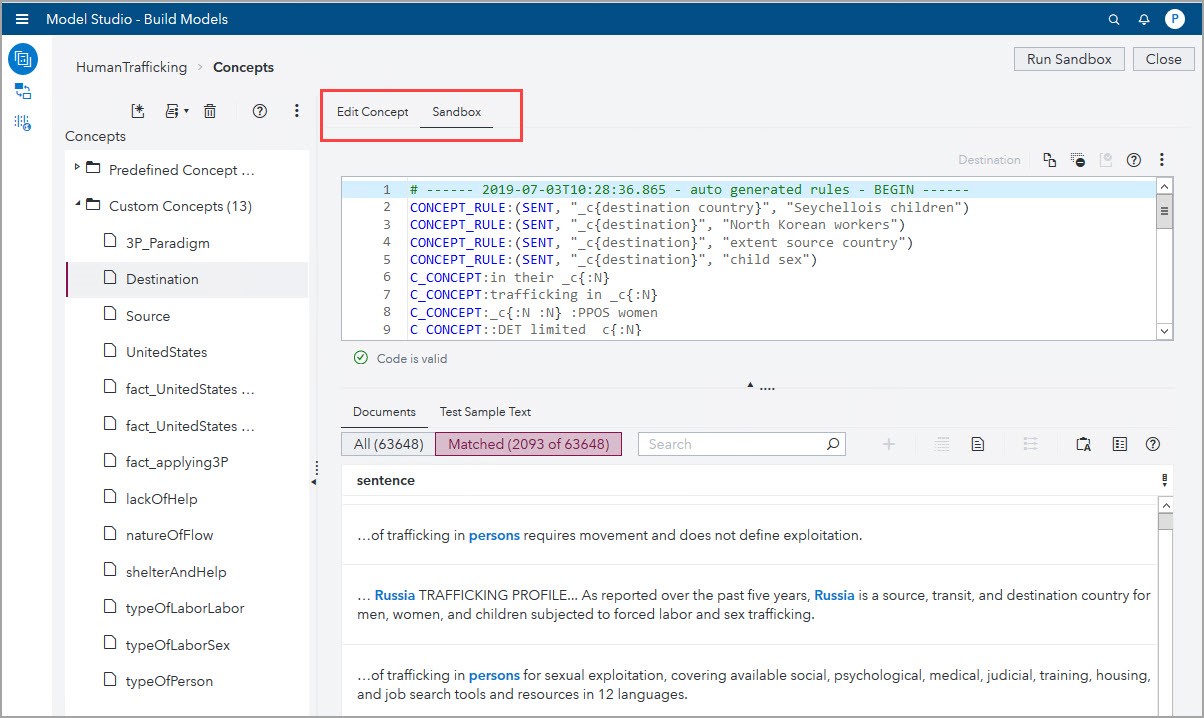
Create CLASSIFIER rules
One of the new features in VTA 8.4 is being able to highlight desired text and create a CLASSIFER rule from it by using a button. One can add CLASSIFIER rules to a Concept definition by simply highlighting text in the Documents tab and clicking the plus icon. The screenshot below shows the steps to follow to have a CLASSIFIER rule auto generated:
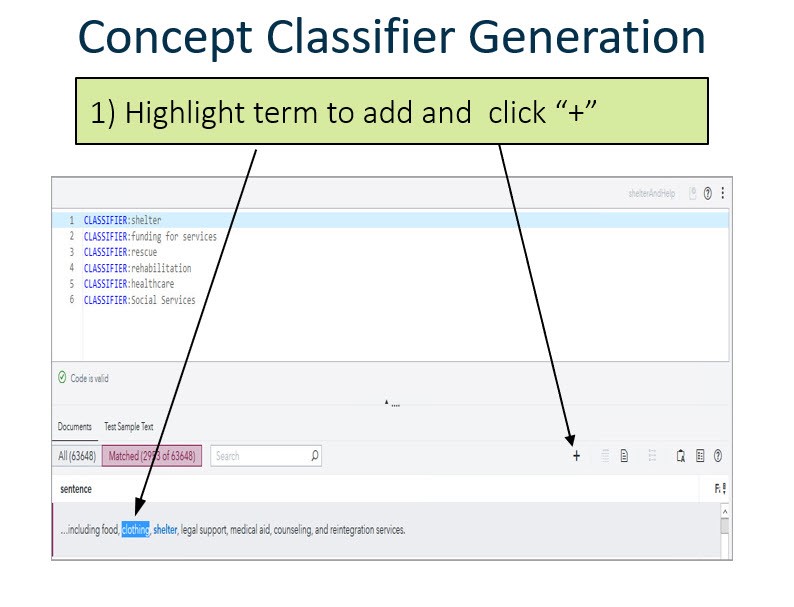
Autogenerate Concept rules
This new feature creates and suggests concept rules for Custom Concepts. Several types of rules can be autogenerated CLASSIFIER, C_CONCEPT and CONCEPT_RULE. These are the steps to follow to autogenerate Concept rules:

There were 25 autogenerated rules in the Sandbox, here are the first ones:
Autogenerate Fact rules
Facts are related pieces of information in a document. The autogeneration of Facts is used to see relationships between already created concepts. One or two rules will be generated. The first rule will use the SENT operator which can be changed to ORD, DIST_n, or AND. The second rule is likely to have a second operator: ORD, ORDDIST_n, or DIST_n.
These are the steps to follow to autogenerate Fact rules:
- Create a new concept, in the screenshot below the new concept is fact_UnitedStates_3P
- Select Autogenerate Concept Rules
- In the new window Fact Rule Generation, move two concepts from the Available concepts column to the Selected concepts column
- Click Generate Rules

In the screenshot below, you can see in the Sandbox the autogenerated fact rule, which is of the type PREDICATE_RULE in this example. When the Sandbox is run, the matching comments appear in the Matched tab. In the screenshot below there are 115 matching comments that relate the two concepts of United States and the 3P_Pararadigm.
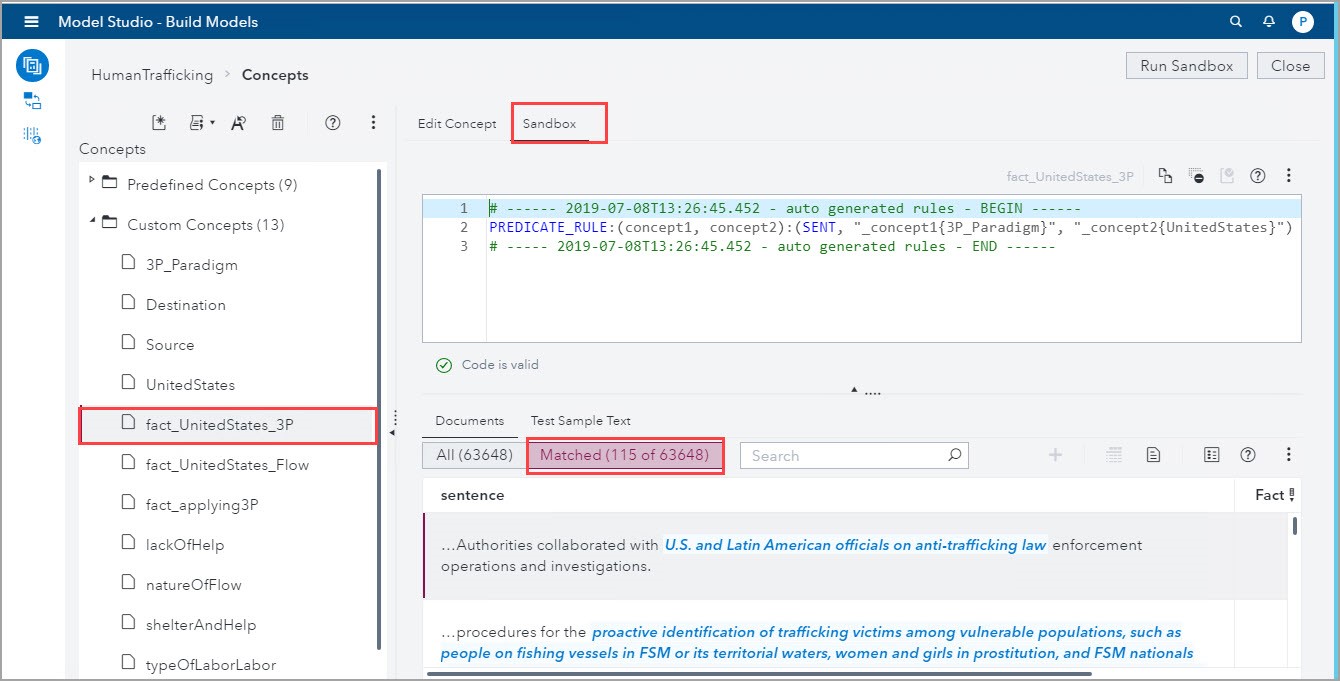
Development of new Concept rules
When working with new data, how do you decide what you want to investigate? One suggestion is to start with the out-of-the-box functionality in SAS Visual Analytics and use the Text Object. From here, you might see a pattern or that the data skews toward a category that you would like to dig into.
The Text Object in Visual Analytics requires that each row have a unique identifier, so I used Prepare Data to do two things. First, I added a unique indicator and second, I added the country name of the report to the beginning of the sentence.
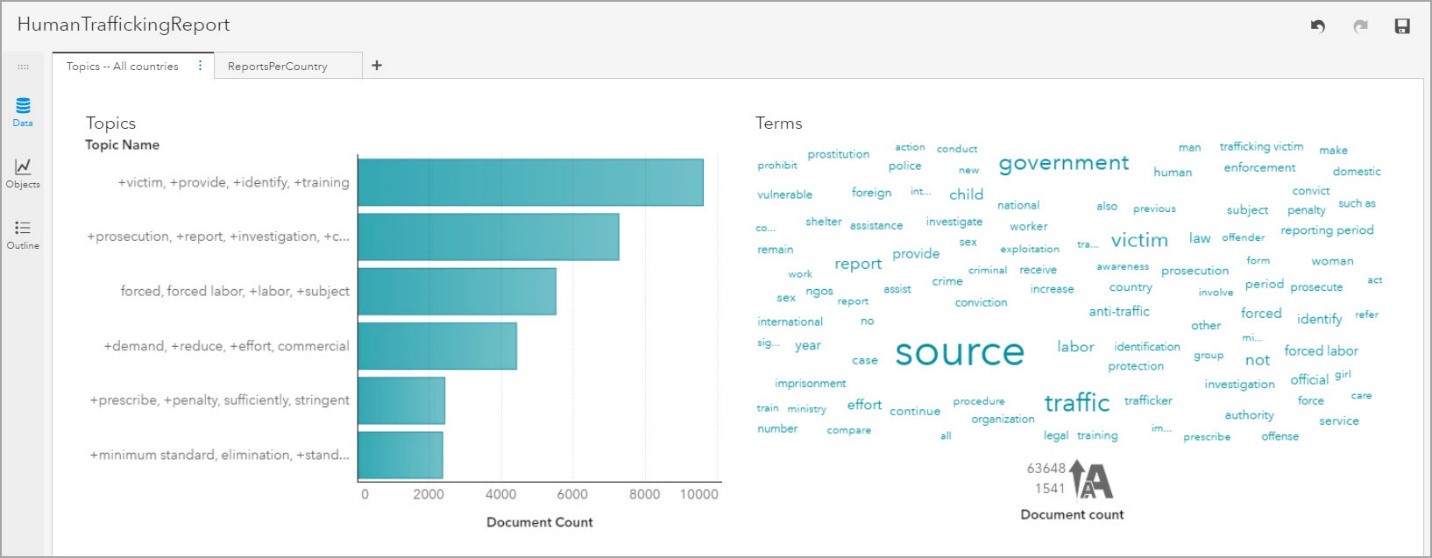
Here is a screenshot of the Text Object in SAS Visual Analytics. One can see the most frequently occurring topics in the Bar Chart, and the Word Cloud indicates that the words that occur with higher frequency are larger in size are: source, government, traffic, and victim.
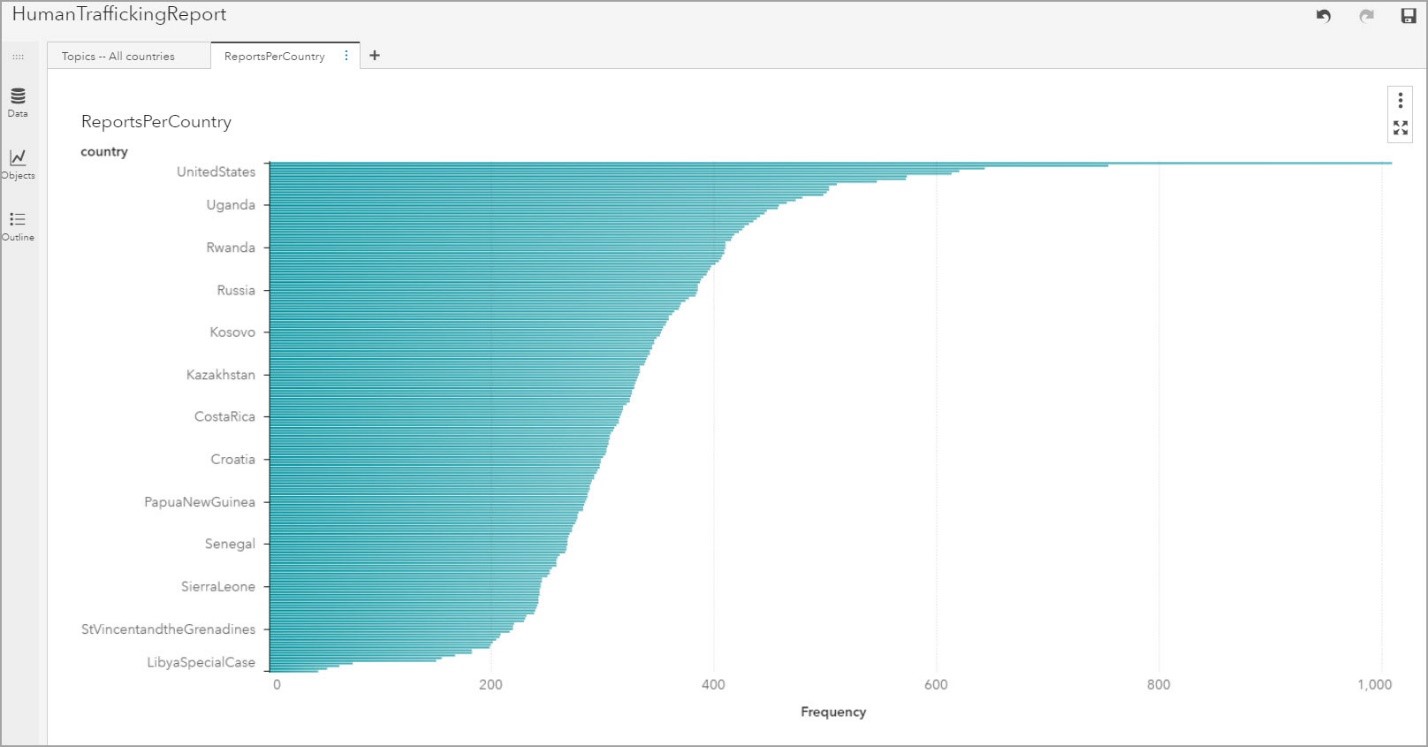
Next, I created a Histogram of Reports Per Country, and I noticed that there were many reports that included United States. Thus, I decided to analyze those reports.
Develop Concepts in Model Studio
In the Concepts node, I defined several concepts using the new VTA 8.4 functionality. I will illustrate three cases:
- The Destination concept shows that sometimes the concept autogenerated rules are not useful per-se but facilitate the identification of the word patterns to correctly defined the new concept.
- The 3P_Paradigm concept is an example when the concept autogenerated rules greatly enhanced the initially Create CLASSIFIER rules.
- The fact_UnitedStates_3P shows an example when the Autogenerate Fact rules quickly identified useful relationships between two concepts.
Destination Concept
Trafficking occurs between Source and Destination countries. I developed this concept to find the destination country.
Here are the steps I took to develop its definition:
1) As explained in the Create CLASSIFIER rules section, I created these CLASSIFIER definitions:
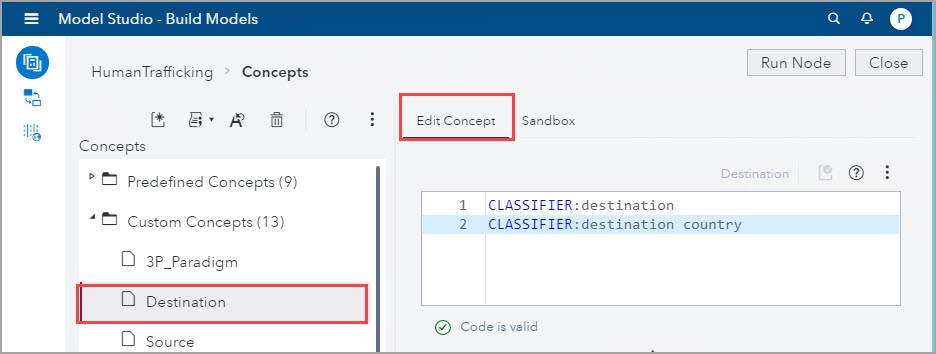
2) I used the Autogenerate Concept rules and after running the node, several rules appeared in the Notice in the screenshot below that the rules generated didn’t extract the specific country destination, but the matched documents showed me the structure I had to formulate to define the Destination concept correctly:

3) I did all these steps in the Sandbox (I followed a similar process every time I worked in the Sandbox):
a. Iterated several times thru these steps:
- I commented all autogenerated concepts but one or two, then ran the Sandbox and analyzed its matching documents.
- Based on that analysis, I created/modified one (or more) of rules in the Sandbox.
- In the Test Sample Text tab, I copied several documents to test the active rules in the Sandbox, as shown in the screenshot below. One uses the Test Sample Text tab to see if the rules, either in the Sandbox or the Edit Concept tab, extract the information that one wants to extract.
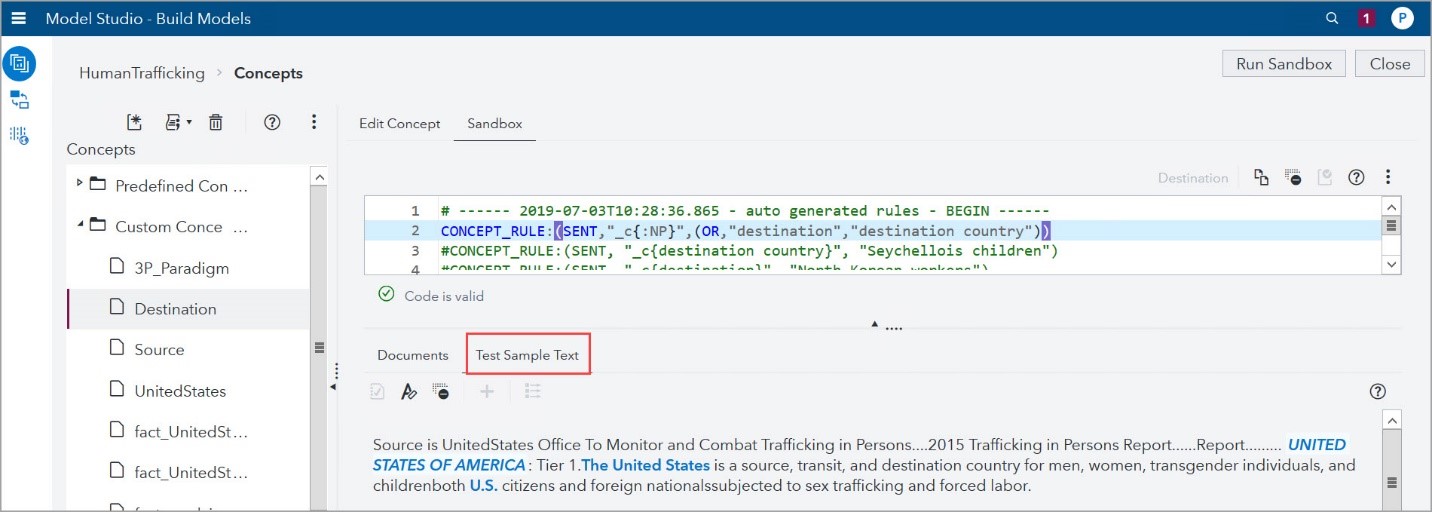
b. I got good results with this rule type CONCEPT_RULE:(SENT,”_c{:NP}”,(OR,”destination”,”destination country”)). It matched most countries, and other items not needed. I modified it slightly and defined the rule CONCEPT_RULE:(SENT,”_c{nlpPlace}”,(OR,”destination”,”destination country”)) as the final definition for the concept Destination because it extracted the destination country correctly.
c. I moved this final rule to the Edit Concept tab for my Destination custom concept.
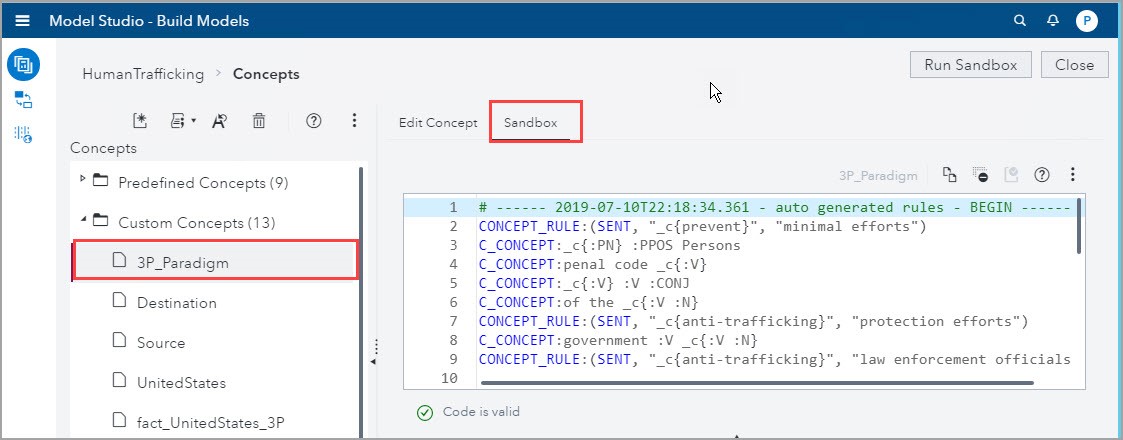
The 3P_Paradigm Concept
The “3P” paradigm defines broad categories for activities to fight human trafficking: Prevent, Protect, and Punish.
1) As explained in the Create CLASSIFIER rules section, I created several CLASSIFIER definitions

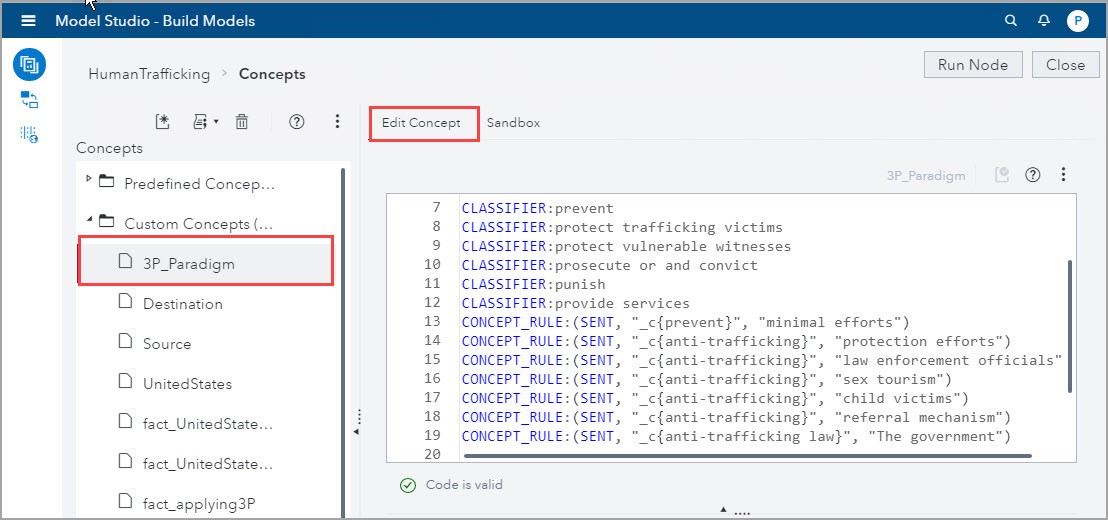
2) I used the Autogenerate Concept rules and after running the node, more than 26 rules appeared in the These rules provide more information on the word patterns, and I believe these autogenerated rules would provide additional insights if they were explored further. I copied to the Edit Concept tab several CONCEPT_RULES as shown in the screenshot below:
The fact_UnitedStates_3P Concept
This fact relates information from two concepts.
1) In addition to the 3P_Paradigm concept described above, I developed the United States concept as:
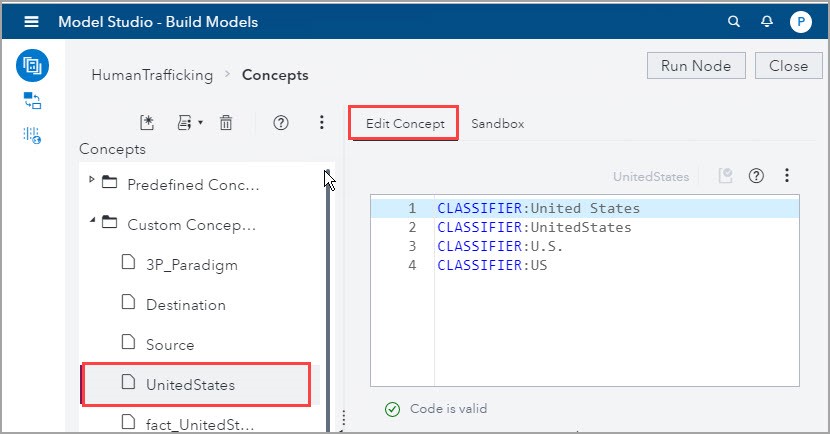
There are 1,406 documents that have the strings in these CLASSIFIER rules. There are 462 documents that have the strings United States as a transit or destination country, and 1,009 documents that have the string UnitedStates as origin country.
2) Using the Autogenerate Fact rules functionality, I found 115 documents that have information on the 3P efforts where the United States has been involved. The screenshot below shows some of the matching documents:

Summary
The machine learning autogenerated concept and fact rules in VTA 8.4 facilitate the process of developing LITI rules to extract and find information in text documents.
There are many important problems where the use of Text Analytics provides valuable insights. In this blog, I showed how the new features in SAS Visual Text Analytics 8.4 speed up the development of your model to provide insights on the problem of Human Trafficking.
Future steps
In your opinion, what are the projects/problems/challenges where Text Analytics can provide insights to solve them?
For more information about SAS Visual Text Analytics, please check out:






