In this blog, I use a Recurrent Neural Network (RNN) to predict whether opinions for a given review will be positive or negative. This prediction is treated as a text classification example. The Sentiment Classification Model is trained using deepRNN algorithms and the resulting model is used to predict if new reviews are positive or negative. I provide two versions of the code: one in CASL and the other one in Python but both will call the same deepRNN algorithms executed by CAS.
Machine learning is embedded in many SAS algorithms and offerings. In 2019, Gartner positioned SAS as a Leader for the sixth consecutive year for the Data Science & Machine Learning Platforms.
From Oliver Schabenberger’s post on Advancing AI with deep learning and GPUs:
"At SAS, we have been building AI systems for decades, but a few things have changed to make today’s AI systems more powerful." … "Our advancements are not just aiming at neural networks and certain machine learning algorithms, for which GPU-specific implementations are being developed. They apply to the general mathematics that are underpinning many of our analytic tools and solutions."
SAS Visual Text Analytics (VTA) is the SAS offering designed to effectively extract insights from unstructured data at a large scale. It combines the power of Natural Language Processing (NLP), Machine Learning (ML) and Linguistic Rules. VTA is a web-based application built on SAS Viya™ platform and powered by CAS. Because CAS has an open architecture that supports 3rd-party programming interfaces, many Text Analytics Actions Sets can be executed from CASL, Lua, R and Python.
Natural Language Processing (NLP) is an exciting field with many applications. Briefly, NLP is a branch of artificial intelligence that helps computers understand, interpret and manipulate human language. NLP draws from many disciplines, including computer science and computational linguistics.
Deep Learning is a type of machine learning that trains a computer to perform human-like tasks, such as recognizing speech, identifying images or making predictions. Deep Learning’s Recurrent Neural Networks (RNNs) are specifically designed to handle sequence data, such as sentiment analysis and text categorization, automatic speech recognition, forecasting and time series, and so on. The network is recurrent because the network feedbacks into itself and makes decisions in several steps. The output for each element depends on the computations of its preceding elements. SAS Deep Learning actions support three model types: Recurrent Neural Network (RNN) the original and quite simple in architecture, Long Short-Term Memory (LSTM) and Gate Recurrent Unit (GRU). In this blog I use LSTM, because LSTM goes many steps back and uses that information to make good predictions on what will happen next.
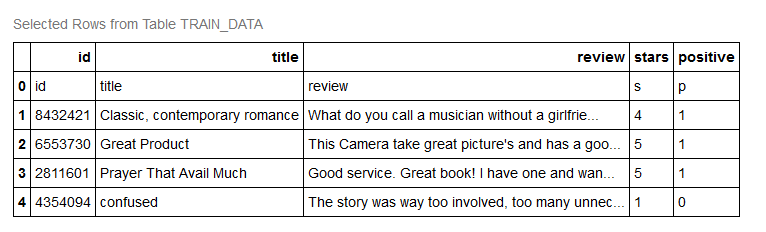
Below there are few lines of the input dataset, we can see the title of the review and the initial part of the review itself:
Humans use expressions such as “very good”, “excellent”, and similar expressions when we have a favorable opinion (or sentiment). These expressions “are related” to each other. Word embedding algorithms are used to automatically detect similar features for words and concepts that are related. Word embeddings are numeric vector representations of words trained based on large corpus. Words that are related end up getting mapped to a more similar feature vector. Popular word embeddings include Word2Vec, GloVe and FastText, and they are publicly available for download. In this blog, I use the 100-dimensions of pre-trained GloVe Word representation when training the model and when scoring the new reviews.
Running DeepRNN in MPP
In this example, I ran DeepRNNs in a massively parallel processing (MPP) environment. Running code in an MPP environment versus a symmetric multi-processor (SMP) environment requires a bit of understanding. As Stephen Foerster mentions in his blog Threads and CAS DATA Step:
“CAS spreads its data and its processing over multiple machines. On each of those machines, the data is divided further into blocks, while the processing is divided further into threads. Each thread grabs a subset of the data blocks on its machine and performs the prescribed logic on that subset. The results from all of the threads are then gathered together and output.”
Now that I’ve reminded you how data is processed in an MPP environment, let’s consider RNNs where its algorithm feedbacks into itself and makes decisions in several steps. For the analyst who is accustomed to getting identical runs each and every time, consider the MPP environment:
- Global data ordering. Each time you load your data when you have multiple workers, there is no guarantee that the data will be distributed across workers in the same fashion.
- Local data ordering. When multiple threads are used, there is no guarantee that data will be read in a specified order by a particular worker.
- Worker communication. Part of this communication may involve a global summing operation. There is no guarantee that the sum will be performed in the same order each time. Since we are using floating point arithmetic, even tiny differences for initial computations can manifest as significant differences in later computations when we do training. This effect is compounded for RNN models because there are many more backpropagation steps for such models compared to either CNN or DNN models.
- Order of computation matters. Assume that your data consists of three mini-batches. You will get different final weights after one pass through your data if you process mini-batch 0, then 1, and then 2 versus mini-batch 2, then 0, and then 1.
Therefore, it is highly recommended that you load your data to a global caslib and run your RNNs from using that data. At least all of the analysts will be using the same global data ordering.
Implementation
Both implementations shown below, one in CASL and the other in Python, use global tables that were loaded to the caslib “ANALYTIC” which is a global library in our GEL MPP collection. This MPP environment has 5 servers: one controller and 4 workers, 4 cores per server for a total of 20 cores.
First, I created global tables to be used in both the CASL and the Python programs. See both programs in the Code section below.
CASL code main steps:
- Create CAS Connection and declare caslibs
- Upload cvs and txt datasets into CAS (Amazon Stanford Reviews and GloVe datasets). Then promote the local cas tables to the ANALYTIC caslib, so they are global cas tables. Once these tables are promoted, this step doesn’t need to be repeated.
- Explore data visually, there are many ways to do this in SAS Studio 5.1.
- Build a Text Classification Model using the rnnTrain of the action set DeepRNN.
- Score the new dataset (reviews_test) using rnnScore. This step uses the model trained in the previous step.
- Print the results and use fedsql to see how specific new reviews were scored. For that, I am using the ID of the reviews.
Python code main steps:
- Import Python modules
- Create CAS connection and specify that “ANALYTIC” is the active caslib. A key line of code is: sess.sessionProp.setSessOpt(caslib=”ANALYTIC”)
- Fetch a few rows from each table
- Same as step 4 above, run the rnnTrain action but now expressed using Python syntax. Notice how similar both codes are. Also, notice that ALL parameters and inputs are the same. This is important because we want to create the same RNN.
- Same as step 5 above, run the rnnScore action but now expressed using Python syntax. Again, notice how similar both codes are, and that the same inputs are used.
- In Python, we can just fetch a few rows to see how new reviews were scored.
CODE
CASL
cas mySession sessopts=(caslib=ANALYTIC timeout=1800 locale="en_US" metrics='true');
libname CASUSER cas caslib=CASUSER;
libname ANALYTIC cas caslib=ANALYTIC;
/* These lines only need to be ran once, its results are global tables in the ANALYTIC caslib
data CASUSER.train_data;
infile '/gelcontent/demo/ANALYTICS/data/reviews_train_5000.csv' dsd truncover;
input id :$10. title :$150. review :$100. stars :$1. positive :$1.;
run;
data CASUSER.test_data;
infile '/gelcontent/demo/ANALYTICS/data/reviews_test_100.csv' dsd truncover;
input id :$10. title :$150. review :$100. stars :$1. positive :$1.;
run;
filename source "/gelcontent/demo/ANALYTICS/data/glove_100d_tab_clean.txt" encoding="utf-8";
proc import datafile=source
dbms=dlm
out=CASUSER.word_embeddings
replace;
delimiter='09'x;
getnames=yes;
run;
proc casutil sessref=mySession outcaslib="ANALYTIC" ;
promote casdata="train_data" incaslib="CASUSER";
quit;run;
proc casutil sessref=mySession outcaslib="ANALYTIC" ;
promote casdata="test_data" incaslib="CASUSER";
quit;run;
proc casutil sessref=mySession outcaslib="ANALYTIC" ;
promote casdata="word_embeddings" incaslib="CASUSER";
quit;run;
*/
proc cas;
session mySession;
deepRnn.rnnTrain /
inputs={"review"}
target='positive'
nominals="Positive"
table={caslib='ANALYTIC',name='train_data'}
modelWeights={caslib='ANALYTIC',name='trainedWeights_deepRNN', replace=TRUE}
modelOut={ name='trainedModel_deepRNN', replace=TRUE}
hiddens={10}
recurrentTypes={'GRU'}
directions={'bidirectional','normal'}
optimizer={miniBatchSize=2,
algorithm={method='adam',
gamma=0.5,
beta1=0.9,
beta2=0.999,
learningRate=0.01,
clipGradMax=1000,
clipGradMin=-1000,
lrPolicy='step',
stepsize=10},
maxEpochs=12,
logLevel=2}
textParms={initInputEmbeddings={caslib='ANALYTIC',name='word_embeddings'}},
recordSeed=12345
nThreads=10
;
deepRnn.rnnScore result=results/
initWeights='trainedWeights_deepRNN'
table='test_data'
modelTable='trainedModel_deepRNN'
textParms={initInputEmbeddings={name='word_embeddings'}}
copyvars={'id','title','review','positive'}
casOut={name='scoringResult_deepRNN', replace=True}
;
print results;
run;
quit;
proc fedsql sessref=mySession;
create table ANALYTIC.PrintResultsRNN {options replace=true} as
select
id, title, review, positive, _DL_PredP_
from ANALYTIC.scoringResult_deepRNN
where id in (1336450, 3529475, 6284941, 4932630,2835536);
quit;
proc cas;
session mySession;
table.fetch /
table={name='PrintResultsRNN'}, sortBy='id';
run;
quit;
* CAS mySession TERMINATE;
Python
##SentimentAnalysisWithDeepRNNActionSet_PythonVersion
# 1. Import Python modules
import swat
import pandas as pd
from swat import *
from pprint import pprint
try:
from StringIO import StringIO
except:
from io import StringIO
import swat.cas.datamsghandlers as dmh
# 2. Create CAS Connection and specify that "ANALYTIC" is the active caslib
############################################################
# NOTE: Adjust the following parameters below:
# - your CAS Host below depending on your RACE image
# (e.g. intcas01.race.sas.com)
# - your username on the RACE image (e.g. 'sasdemo03')
# - your password on the RACE imgae (e.g. 'Orion123')
############################################################portnumber = 5570
portnumber=5570
sess = swat.CAS('intcas01.race.sas.com', portnumber, 'sasdemo03', 'Orion123', caslib="ANALYTIC")
sess.sessionProp.setSessOpt(caslib="ANALYTIC")
print (sess)
sess.loadactionset('deepRNN')
# 3. Data check: tables are global tables already loaded into the ANALYTIC caslib
# Fetch a small sample of the full Stanford Amazon review data set to train model
sess.table.fetch(table="train_data",to=5)
# Fetch a small sample of the data set to score
sess.table.fetch(table="test_data",to=5)
# Fetch the file with Word Representation (embeddings)
# The user can use any form of word representation. For the purpose of this demo, we will be using 100-dimensions of
# pre-trained GloVe Word representation
sess.table.fetch(table="word_embeddings",to=2)
# 4. Build a Text Classification Model using RNN
# We will demonstrate training a deep learning model using Recurrent Neural Networks (RNN) for text classification problem.
# Here we treat sentiment analysis as a text classification example.
# Train the Sentiment Classification Model
# Training with deepRNN the model for sentiment analysis: use reviews as input and predict the polarity
# of the review (positive vs. negative)
sess.rnnTrain(inputs=["review"],
target='positive', nominals="Positive",
table='train_data',
modelWeights=dict(name='trainedWeights_deepRNN', replace=True),
modelOut=dict(name='trainedModel_deepRNN', replace=True),
hiddens=[10],
recurrentTypes=['GRU'],
directions=['bidirectional','normal'],
optimizer=dict(miniBatchSize=2,
algorithm=dict(method='adam',
gamma=0.5,
beta1=0.9,
beta2=0.999,
learningRate=0.01,
clipGradMax=1000,
clipGradMin=-1000,
lrPolicy='step',
stepsize=10),
maxEpochs=12,
logLevel=2),
textParms=dict(initInputEmbeddings='word_embeddings'),
recordSeed=12345,
nThreads=10)
# Save the table for future use without having to re-train
sess.save(table='trainedWeights_deepRNN', caslib='ANALYTIC',
name='demo_sentiment_trainedWeights_deepRNN.sashdat', replace=True)
#5. Score using the Sentiment Classification Model
sess.fetch('test_data')
r = sess.rnnScore(initWeights='trainedWeights_deepRNN',
table='test_data',
modelTable='trainedModel_deepRNN',
textParms=dict(initInputEmbeddings='word_embeddings'),
copyvars=['id','title','review','positive'],
casOut=dict(name='scoringResult_deepRNN', replace=True))
print(r['ScoreInfo'])
#6. See predicted scores for the new reviews
sess.fetch('scoringResult_deepRNN', to=6, fetchVars=('id','title','review','positive','_DL_predP_'))
#sess.close()
Analysis of Results
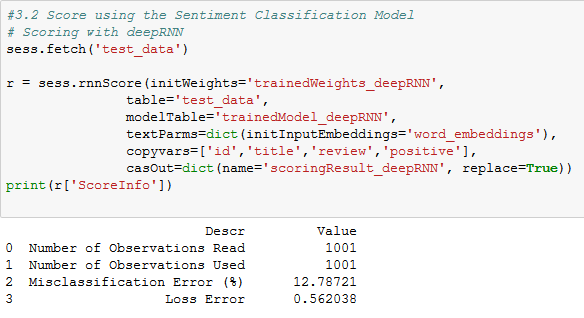
Recall the nature of RNN and running in a MPP environment. These reasons why we would expect to get different results each time we run the RNN in CAS. In fact, I ran both programs several times and got different percentages for Misclassification Error and for Loss Error. I remembered that “tiny differences for initial computations will manifest as significant differences in later computations when we do the training.”
We expect that the larger the data the closer the results will be. Below are the photos with similar results in for multiple runs of the same RNN, one executed via CASL and one via Python. I would consider this something of a “one off” and not something that we should expect “regularly”.
From CASL

From Python
Predicted Scores for New Reviews
It is interesting to compare the column "positive" to "_DL_PredP_"

Concluding Throughts
Take advantage of massively parallel processing (MPP) architecture to execute Deep Recurrent Neural Networks (RNN) on massive amounts of data quickly. Sentiment analysis is an ideal application to use Deep RNNs. It is important to understand how multi-threaded processing works in a distributed environment so that the results can be understood and properly analyzed. It is also a developer advantage that calling CAS actions from either CASL or Python are so very similar. For several procedures and actions, CASL and Python codes are very similar.
References
CODE
CASL
cas mySession sessopts=(caslib=ANALYTIC timeout=1800 locale="en_US" metrics='true'); libname CASUSER cas caslib=CASUSER; libname ANALYTIC cas caslib=ANALYTIC; /* These lines only need to be ran once, its results are global tables in the ANALYTIC caslib data CASUSER.train_data; infile '/gelcontent/demo/ANALYTICS/data/reviews_train_5000.csv' dsd truncover; input id :$10. title :$150. review :$100. stars :$1. positive :$1.; run; data CASUSER.test_data; infile '/gelcontent/demo/ANALYTICS/data/reviews_test_100.csv' dsd truncover; input id :$10. title :$150. review :$100. stars :$1. positive :$1.; run; filename source "/gelcontent/demo/ANALYTICS/data/glove_100d_tab_clean.txt" encoding="utf-8"; proc import datafile=source dbms=dlm out=CASUSER.word_embeddings replace; delimiter='09'x; getnames=yes; run; proc casutil sessref=mySession outcaslib="ANALYTIC" ; promote casdata="train_data" incaslib="CASUSER"; quit;run; proc casutil sessref=mySession outcaslib="ANALYTIC" ; promote casdata="test_data" incaslib="CASUSER"; quit;run; proc casutil sessref=mySession outcaslib="ANALYTIC" ; promote casdata="word_embeddings" incaslib="CASUSER"; quit;run; */ proc cas; session mySession; deepRnn.rnnTrain / inputs={"review"} target='positive' nominals="Positive" table={caslib='ANALYTIC',name='train_data'} modelWeights={caslib='ANALYTIC',name='trainedWeights_deepRNN', replace=TRUE} modelOut={ name='trainedModel_deepRNN', replace=TRUE} hiddens={10} recurrentTypes={'GRU'} directions={'bidirectional','normal'} optimizer={miniBatchSize=2, algorithm={method='adam', gamma=0.5, beta1=0.9, beta2=0.999, learningRate=0.01, clipGradMax=1000, clipGradMin=-1000, lrPolicy='step', stepsize=10}, maxEpochs=12, logLevel=2} textParms={initInputEmbeddings={caslib='ANALYTIC',name='word_embeddings'}}, recordSeed=12345 nThreads=10 ; deepRnn.rnnScore result=results/ initWeights='trainedWeights_deepRNN' table='test_data' modelTable='trainedModel_deepRNN' textParms={initInputEmbeddings={name='word_embeddings'}} copyvars={'id','title','review','positive'} casOut={name='scoringResult_deepRNN', replace=True} ; print results; run; quit; proc fedsql sessref=mySession; create table ANALYTIC.PrintResultsRNN {options replace=true} as select id, title, review, positive, _DL_PredP_ from ANALYTIC.scoringResult_deepRNN where id in (1336450, 3529475, 6284941, 4932630,2835536); quit; proc cas; session mySession; table.fetch / table={name='PrintResultsRNN'}, sortBy='id'; run; quit; * CAS mySession TERMINATE; |
Python
##SentimentAnalysisWithDeepRNNActionSet_PythonVersion # 1. Import Python modules import swat import pandas as pd from swat import * from pprint import pprint try: from StringIO import StringIO except: from io import StringIO import swat.cas.datamsghandlers as dmh # 2. Create CAS Connection and specify that "ANALYTIC" is the active caslib ############################################################ # NOTE: Adjust the following parameters below: # - your CAS Host below depending on your RACE image # (e.g. intcas01.race.sas.com) # - your username on the RACE image (e.g. 'sasdemo03') # - your password on the RACE imgae (e.g. 'Orion123') ############################################################portnumber = 5570 portnumber=5570 sess = swat.CAS('intcas01.race.sas.com', portnumber, 'sasdemo03', 'Orion123', caslib="ANALYTIC") sess.sessionProp.setSessOpt(caslib="ANALYTIC") print (sess) sess.loadactionset('deepRNN') # 3. Data check: tables are global tables already loaded into the ANALYTIC caslib # Fetch a small sample of the full Stanford Amazon review data set to train model sess.table.fetch(table="train_data",to=5) # Fetch a small sample of the data set to score sess.table.fetch(table="test_data",to=5) # Fetch the file with Word Representation (embeddings) # The user can use any form of word representation. For the purpose of this demo, we will be using 100-dimensions of # pre-trained GloVe Word representation sess.table.fetch(table="word_embeddings",to=2) # 4. Build a Text Classification Model using RNN # We will demonstrate training a deep learning model using Recurrent Neural Networks (RNN) for text classification problem. # Here we treat sentiment analysis as a text classification example. # Train the Sentiment Classification Model # Training with deepRNN the model for sentiment analysis: use reviews as input and predict the polarity # of the review (positive vs. negative) sess.rnnTrain(inputs=["review"], target='positive', nominals="Positive", table='train_data', modelWeights=dict(name='trainedWeights_deepRNN', replace=True), modelOut=dict(name='trainedModel_deepRNN', replace=True), hiddens=[10], recurrentTypes=['GRU'], directions=['bidirectional','normal'], optimizer=dict(miniBatchSize=2, algorithm=dict(method='adam', gamma=0.5, beta1=0.9, beta2=0.999, learningRate=0.01, clipGradMax=1000, clipGradMin=-1000, lrPolicy='step', stepsize=10), maxEpochs=12, logLevel=2), textParms=dict(initInputEmbeddings='word_embeddings'), recordSeed=12345, nThreads=10) # Save the table for future use without having to re-train sess.save(table='trainedWeights_deepRNN', caslib='ANALYTIC', name='demo_sentiment_trainedWeights_deepRNN.sashdat', replace=True) #5. Score using the Sentiment Classification Model sess.fetch('test_data') r = sess.rnnScore(initWeights='trainedWeights_deepRNN', table='test_data', modelTable='trainedModel_deepRNN', textParms=dict(initInputEmbeddings='word_embeddings'), copyvars=['id','title','review','positive'], casOut=dict(name='scoringResult_deepRNN', replace=True)) print(r['ScoreInfo']) #6. See predicted scores for the new reviews sess.fetch('scoringResult_deepRNN', to=6, fetchVars=('id','title','review','positive','_DL_predP_')) #sess.close() |
Analysis of Results
Recall the nature of RNN and running in a MPP environment. These reasons why we would expect to get different results each time we run the RNN in CAS. In fact, I ran both programs several times and got different percentages for Misclassification Error and for Loss Error. I remembered that “tiny differences for initial computations will manifest as significant differences in later computations when we do the training.”
We expect that the larger the data the closer the results will be. Below are the photos with similar results in for multiple runs of the same RNN, one executed via CASL and one via Python. I would consider this something of a “one off” and not something that we should expect “regularly”.
From CASL
From Python
Predicted Scores for New Reviews
It is interesting to compare the column "positive" to "_DL_PredP_"
Concluding Throughts
Take advantage of massively parallel processing (MPP) architecture to execute Deep Recurrent Neural Networks (RNN) on massive amounts of data quickly. Sentiment analysis is an ideal application to use Deep RNNs. It is important to understand how multi-threaded processing works in a distributed environment so that the results can be understood and properly analyzed. It is also a developer advantage that calling CAS actions from either CASL or Python are so very similar. For several procedures and actions, CASL and Python codes are very similar.






