Machine learning applications for NBA coaches and players might seem like an odd choice for me to write about. Let us get something out of the way: I don’t know much about basketball. Or baseball. Or even soccer, much to the chagrin of my friends back home in Europe. However, one of the perks of working in data science and machine learning is that I can still say somewhat insightful things about sports, as long as I have data. In other words, instant expertise! So with that expertise I’ll weigh in to offer some machine learning applications for basketball.
During a conversation with my good colleague Ray Wright, who does know quite a bit about basketball and had been looking at historical data from NBA games, we suddenly realized something about player shooting. There are dozens of shot types, ranges and zones… and no player ever tries them all. What if we could automatically suggest new shot combinations appropriate for each individual player? Who knew there could be machine learning applications for the NBA?
Such a system that suggests actions or items to users is called a recommender system. Large companies in retail and media regularly use recommender systems to suggest movies, songs and other items to users based on their behavior history, as well as that of other similar users, so you’ve liked used such a system from Amazon, Netflix, etc.In basketball terms, the users are the players, and the items are shot types. As with the other domains mentioned above, available data does not even come close to covering all possible combinations, in this case for players and shots. When the available data matches this scenario it is called sparse. And fortunately, SAS has a new offering, SAS® Viya™ Data Mining and Machine Learning, that includes a new method specifically designed for sparse predictive modeling: PROC FACTMAC, for Factorization Machines.
Let me quickly introduce you to factorization machines. Originally proposed by Steffen (Rendle, 2010), they are a generalization of matrix factorization that allows multiple features with high cardinality (lots of unique values) and sparse observations. The parameters of this flexible model can be estimated quickly, even in the presence of massive amounts of data, through stochastic gradient descent, which is is the same type of optimization solver behind the recent successes of deep learning.
Factorization Machines return bias parameters and latent factors, which in this case can be used to characterize players and shot combinations. You can think of a player’s bias as the overall propensity to successfully score, whereas the latent factors are more fine-grained characteristics that can be related to play style, demographics and other information.
Armed with this thinking, our trusty machine learning software from SAS, and some data science tricks up our sleeves, we decided to try our hand at machine learning applications in the form of automated basketball coaching (sideline yelling optional!). Before going into our findings, let’s take a look at the data. We have information about shots taken during the 2015-2016 NBA basketball season through March 2016. A total of 174,190 shots were recorded during this period. Information recorded for each shot includes the player, shot range, zone, and style (“action type”), and whether the shot was successful. After preprocessing we retained 359 players, 4 ranges, 5 zones, and 36 action types.
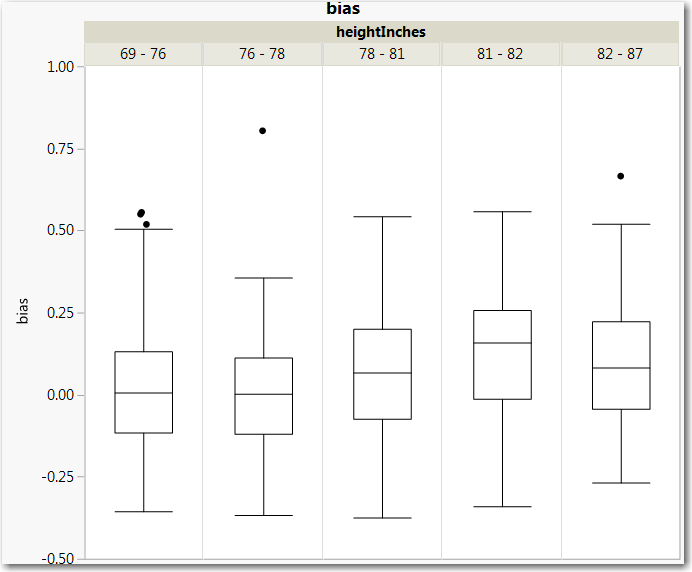
And here is what we found after fitting a factorization machine model. First, let’s examine some established wisdom- does height matter much for shot success? As the box and whisker plot below shows, the answer is yes, somewhat, but not quite as much as one would think. The figure depicts the distribution of bias values for players, grouped by their height. There is a bump for the 81-82 inch group, but it is not overwhelming. And it decays slightly for the 82-87 inch group.
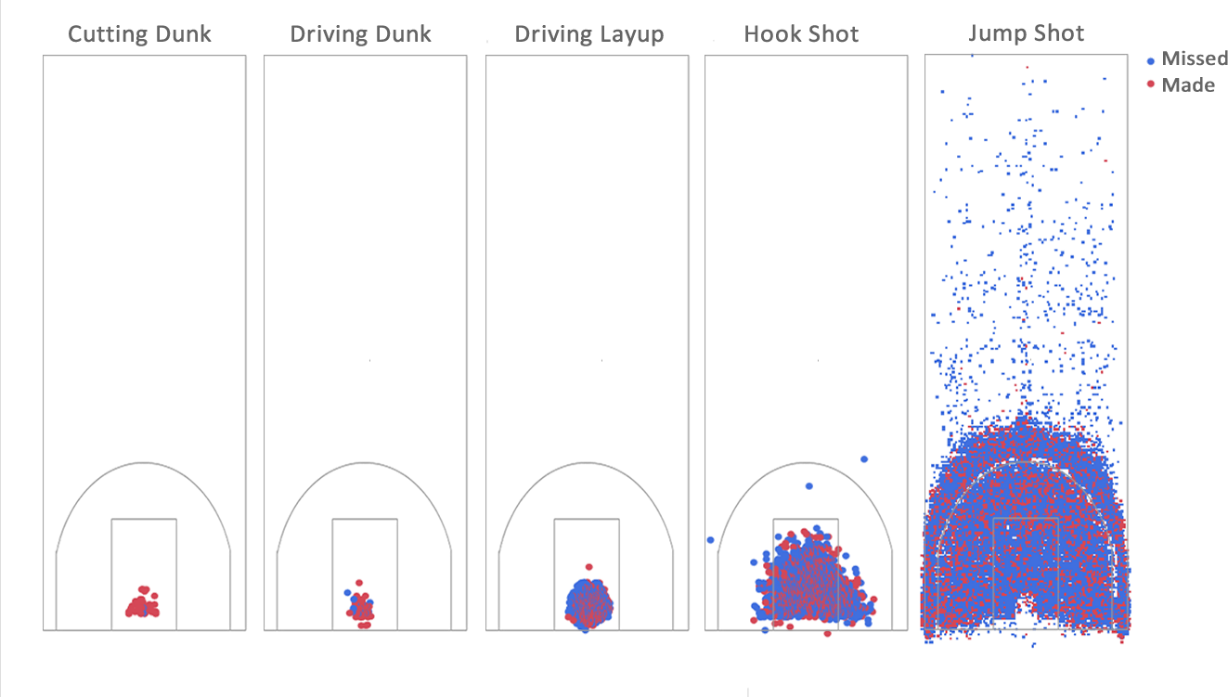
Now look at the following figure, which shows made shots (red) vs missed (blue), by location in the court and by action type. There is definitely a very significant dependency! Now if only someone explained to me again what a “driving layup” is…
Let us investigate the biases again, now by action type. The following figure shows the bias values in a horizontal bar plot. It is clear that all actions involving “dunk” lead to larger bars, corresponding to greater probability of success.

What about other actions? What should we recommend to the typical player? That is what the following two tables show.
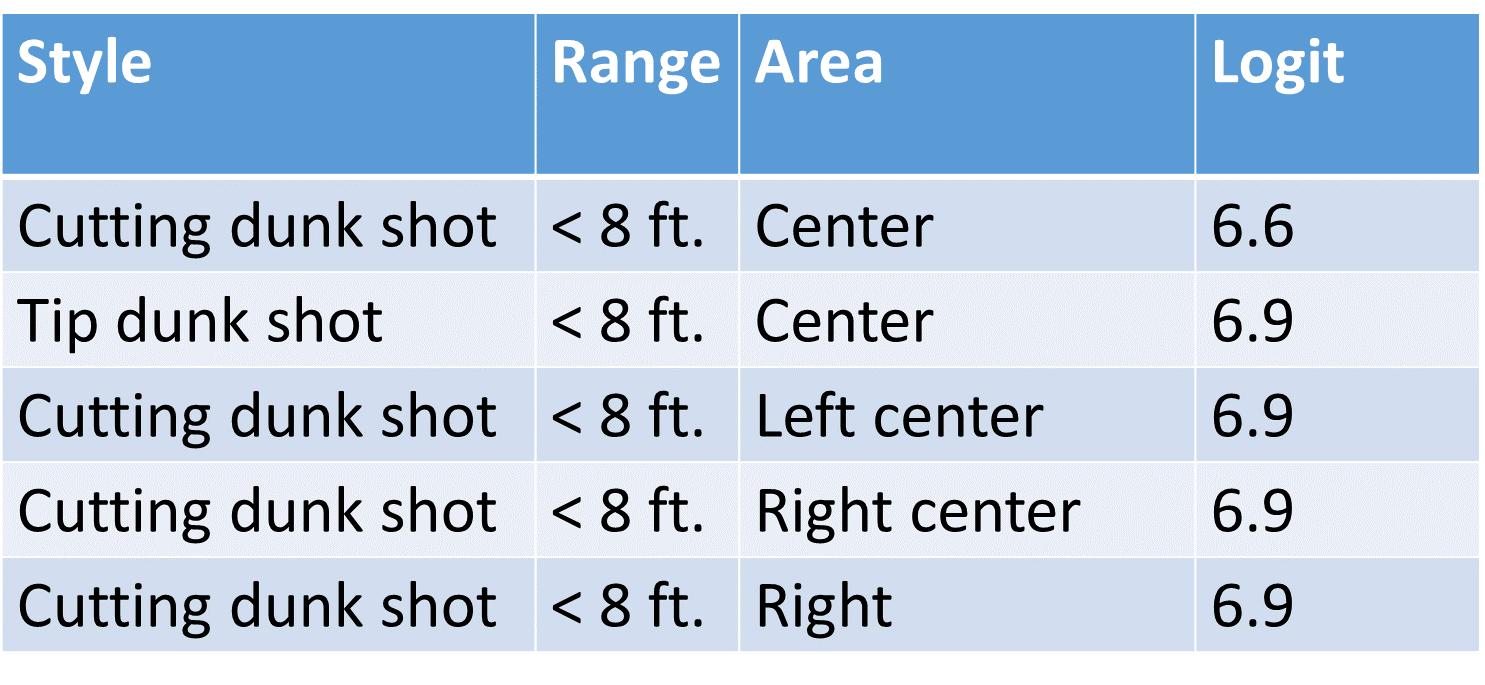
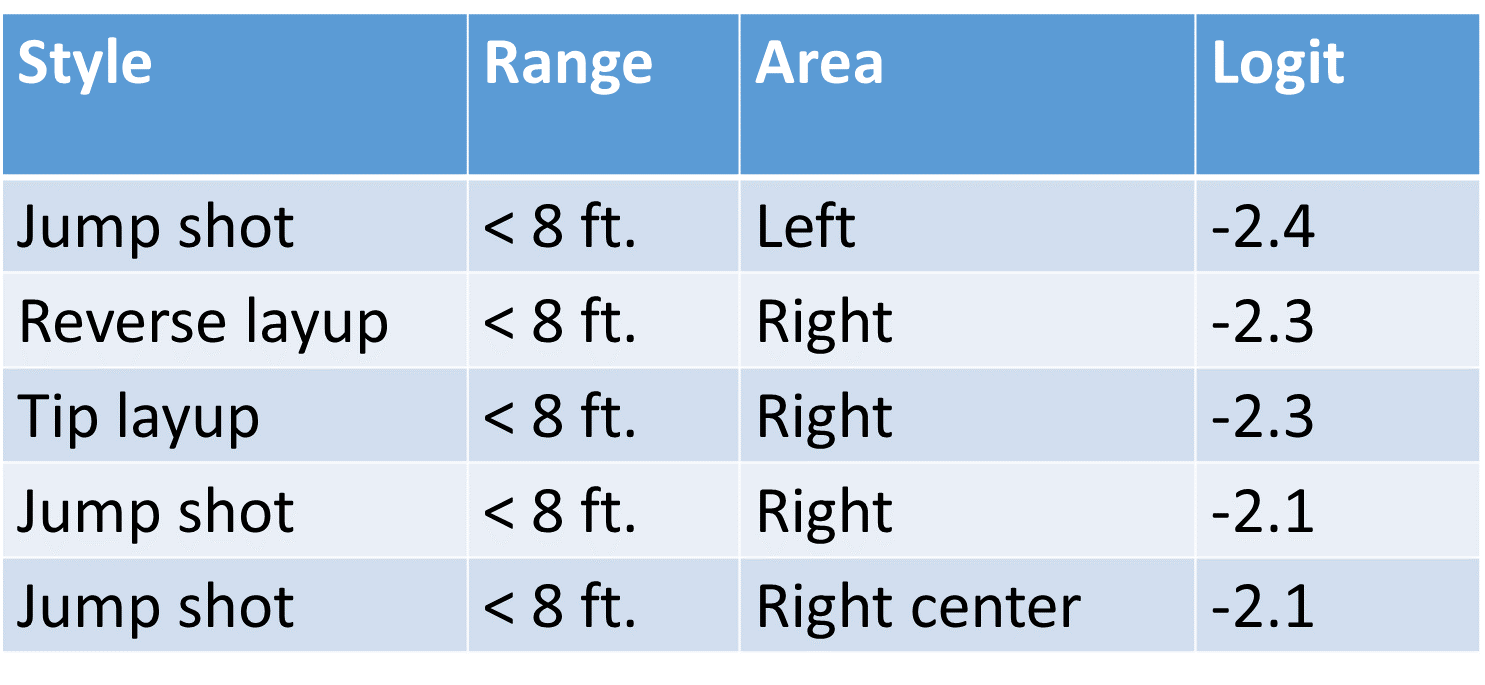
Based on the predicted log-odds, the typical player should strive for dunk shots and avoid highly acrobatic and complicated actions, or highly contested ones such as jump shots. Now, of course not all players are “”typical.” The following figure shows a 2D embedding of the fitted factors for players (red) and actions (blue). There is significant affinity between Manu Giobili and driving floating layups. Players Ricky Rubio and Derrick Rose exhibit similar characteristics based on their shot profiles, as do Russell Westbrook and Kobe Bryant, and others. Also, dunk shot action types form a grouping of their own!

Overall, our 25-factor factorization machine model is successful in predicting log-odds of shot success with high accuracy: RMSE=0.929, which outperforms other models such as SVMs. Recommendations can be tailored to specific players, and many different insights can be extracted. So if any NBA coaches or players want to call about our applications of machine learning for basketball we are available for consultation!
We are delighted that this analysis has been accepted for presentation at the 2016 KDD Large-Scale Sports Analytics workshop this Sunday, August 14, where Ray will be representing our work with this paper: "Shot Recommender System for NBA Coaches." And my other colleague (and basketball fan), Brett Wujek, will be giving a demo theater presentation on “Improving NBA Shot Selection: A Matrix Factorization Approach” at the SAS Analytics Experience Conference September 12-14, 2016 in Las Vegas.
Surely, many basketball experts will be able to give us good tips to augment our applications of machine learning for the NBA. One thing is certain, though when in doubt, always dunk!
Reference
Rendle, S. (2010). Factorization Machines. Proceedings of the 10th IEEE International Conference on Data Mining (ICDM).






