You most likely have used a Portable Document Format (PDF) file in one form or another. Now, what if you have a PDF file and want to extract the text from the file? What if the PDF file contains input fields that a user fills in and you want to create a structured table from the input? How can you do it with SAS Viya?
My scenario
To start, let's pretend I own a business named Peter and Mark's Jedi Solutions. We have our customers fill out a PDF form with a series of information. In this example, I have three simple PDF files from three separate customers. The PDF template looks like this:

In our company we get hundreds of these. Typically, we've manually entered the input field information into a structured table. That enables us to easily analyze the information. However, as our company grows this process has become time consuming and can be error prone. We've decided to automate this process with SAS Viya by extracting the text from the PDF files and creating a structured table.
SAS Viya files setup
To start, I have all of my files loaded on to the SAS Viya server. I've created a folder called Extract text from PDFs and create tables . Based on your environment, you might or might not have access to upload local files to the Viya server. If you don't have access you will need an administrator to upload the files for you.
To upload the files manually in SAS Studio, select the upload button and upload the files.
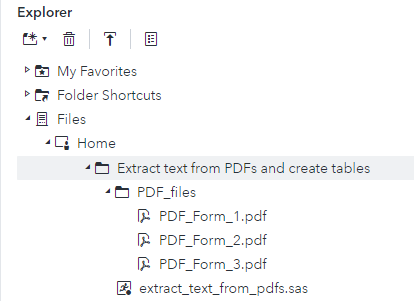
I've created the following folder structure in SAS Studio.
If you want to follow along you can download the PDF files and solution program zip file here: extract text from PDFs and create tables.
Create a CAS session and caslib
Once the files are on the Viya server, you first need to make CAS connection from the SAS Compute server to the CAS server.
cas conn; |
After making the CAS connection, create a library reference to the Casuser caslib. This enables you to access CAS tables with the CAS engine using traditional SAS code. For more information on caslibs check out the following video.
libname casuser cas caslib='casuser'; |
After the files are uploaded to the server, the CAS connection has been made, and the library reference to the Casuser caslib is set, you can easily extract the text from a PDF file (or multiple PDF files). In this example, I'll extract text from a series of PDF files in one step.
Extract text from PDF files
I'll start by creating a macro variable that points to my project folder Extract text from PDFs and create tables. Now, you can manually type in the folder path in the path macro variable. However, I chose to created dynamic code in my extract_text_from_pdfs.sas program that finds the location of the saved program. This assumes your program is saved in same folder structure as shown above.
%let fileName = /%scan(&_sasprogramfile,-1,'/'); %let path = %sysfunc(tranwrd(&_sasprogramfile, &fileName,)); %put &=path; /* and my results */ PATH=/viya/homes/user/Extract text from PDFs and create tables |
The results show the path macro variable contains the location of my project root folder Extract text from PDFs and create tables.
Next, use the path macro variable from above to create a caslib named my_pdfs to the /viya/homes/user/Extract text from PDFs and create tables/PDF_files folder. The SUBDIR option is required when using document file types.
caslib my_pdfs path="&path./PDF_files" subdirs; |
To confirm the caslib is set, run the CASUTIL procedure with the LIST FILES statement to view available files in the my_pdfs caslib.
proc casutil; list files incaslib='my_pdfs'; quit; |
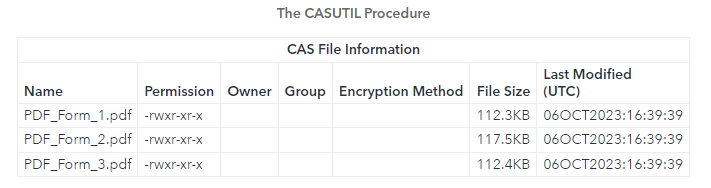
The results show three PDF files are available in the my_pdfs caslib.
Once the files are available, use the CASUTIL procedure with the LOAD statement (or you can use the native table.loadTable action) to create a CAS table with the extracted text from all of the PDF files in the my_pdfs caslib. I'll use the CASUTIL procedure since the syntax is more familiar to SAS programmers than the CAS action. The following arguments are used:
- the CASDATA= argument specifies the name of the file (or files) to load from the server-side data source that is associated with the INCASLIB= option. Here the argument is left blank. This will enable the procedure to read in all of the PDF files in the caslib instead of a single file. If you want to read in one PDF file, specify the file name and extension.
- the INCASLIB= argument specifies the caslib that is associated with the file or files to load. Here the my_pdfs caslib is used. This was created earlier with the CASLIB statement.
- the IMPORTOPTIONS= argument specifies the file format and specific options. The FILETYPE= option sets the DOCUMENT parameter. The DOCUMENT parameter enables specific document options. The FILEEXTLIST= option specifies the file extensions for subsetting the document files to import. The TIKACONV= parameter specifies to convert the documents with the Apache Tika document conversion library.
- the CASOUT= argument specifies the name to use for the in-memory CAS table. Here the CAS table will be named PDF_DATA.
- the OUTCASLIB= argument specifies the CAS table output location. Here the PDF_DATA CAS table will be placed in the Casuser caslib.
- the REPLACE argument specifies to replace the CAS table if it already exists.
proc casutil; load casdata='' /* To read in all files use an empty string. For a single file specify the file name */ incaslib='my_pdfs' /* The location of the files to load */ importoptions=(fileType="document" fileExtList = 'PDF' tikaConv=True) /* Specify document import options */ casout='pdf_data' outcaslib='casuser' replace; /* Specify the output cas table info */ quit; /* and the log */ NOTE: Cloud Analytic Services made documents available as table PDF_DATA in caslib CASUSER(Peter). NOTE: The Cloud Analytic Services server processed the request in 0.765683 seconds. 85 quit; NOTE: PROCEDURE CASUTIL used (Total process time): real time 0.77 seconds cpu time 0.02 seconds |
The results show that a CAS table named PDF_DATA was created in the Casuser caslib.
Preview the PDF_DATA CAS table using the PRINT procedure to view the extracted text.
proc print data=casuser.pdf_data(obs=10); run; |

The results show that the text from each PDF has been written as a row of data in the content column. There is also other information for each PDF file like the fileName, fileType, fileSize and fileDate.
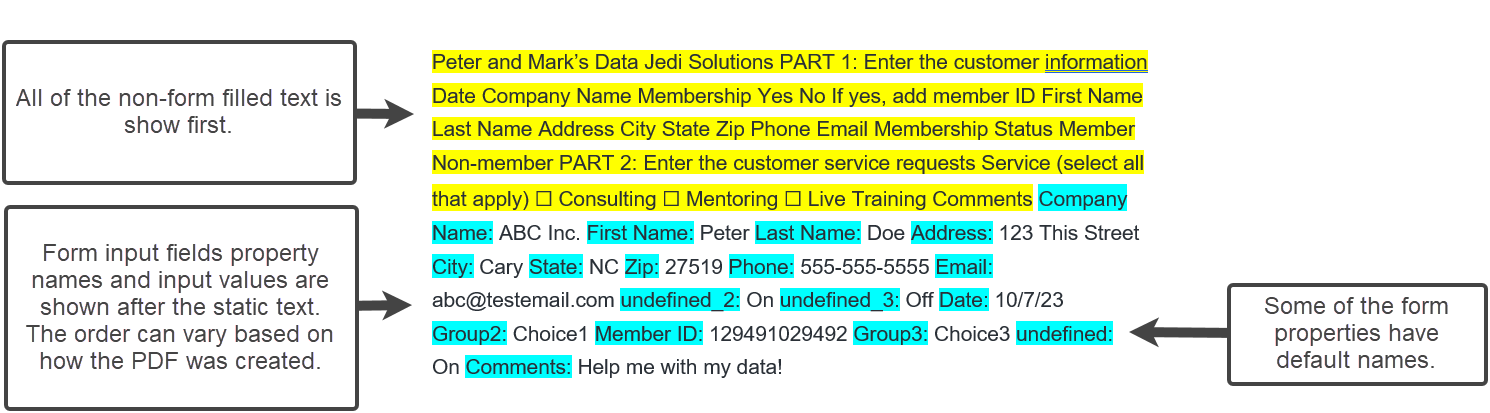
Let's take a look at the extracted text of the first PDF. What I found when viewing the extracted text:
- All of the static text in the PDF is shown in the first part of the text (yellow).
- All of the form input field property names and input values are shown after the static text (blue). I've noticed the order of the property fields can vary based on how the PDF was created. The default names of the input fields can be difficult to decipher since the names can be vague. In this example, some of the fields are named are others use the default names.
The most time consuming part of this process is part is figuring out which input field name from the PDF matches the user input text. Once you do that the code to create the structured table can be done using traditional SAS DATA step.
Let's match up the PDF input fields to the unstructured text. This takes some manual intervention.
| PDF Document | Unstructured Text Field Name |
| Date | Date: |
| Company Name | Company Name: |
| Membership – Yes | No | Group2: Choice 1(Yes) | Choice 2 (No) |
| If yes, add member ID | Member ID |
| First Name | First Name: |
| Last Name | Last Name: |
| Address | Address: |
| City | City: |
| State | State: |
| Zip | Zip: |
| Phone | Phone: |
| Email: | |
| Membership Status – Member | Non-member | Group3: Choice 3 (Member) | Choice 4 (Non-member) |
| Service (select all that apply) - Consulting | undefined: On | Off |
| Service (select all that apply) - Mentoring | undefined_2: On | Off |
| Service (select all that apply) – Live Training | undefined_3: On | Off |
| Comments | Comments: |
Preparing the unstructured data
Once you figure out the names of the input fields that hold the value you need in the unstructured text, you can then clean the text and create a structured table. In this example, the CAS table is not big, so I don't need the power of the distributed CAS server for processing. Instead, I'll use the traditional SAS Compute server in SAS Viya. This enables the use of traditional SAS programming.
To make my code easier to write and maintain, I first figured out the logic I needed to clean the data and then used that to create a SAS user defined function (UDF) using PROC FCMP. This avoids having to write the same repetitive logic to create the table.
/***********************/ /* STEP 1 - CREATE UDF */ /***********************/ proc fcmp outlib=work.funcs.trial; function find_pdf_value(formFieldsData $, field_to_find $, next_field $) $; /* This function will obtain the text input field between two input objects and return the value as a character - formFieldsData - The string that contains the text from the PDF - field_to_find - The name of the first input field object (includes the :) - next_field - The field to parse the input field to (includes the :) */ /* Find position of the text to obtain */ find_first_form_position = find(FormFieldsData, field_to_find) + length(field_to_find); find_second_form_position = find(FormFieldsData, next_field); find_length_of_value = find_second_form_position - find_first_form_position; /* Get the PDF input field value */ length pdf_values $1000; pdf_values = substr(FormFieldsData, find_first_form_position, find_length_of_value); return(pdf_values); endsub; run; |
After I created my UDF, I used the SAS DATA step to clean the data. I won't go into detail on the DATA step code. The one thing I'll mention is that the unstructured text from the PDF contains tabs and carriage returns. Those are difficult to see in the HTML results. At first I didn't notice those and it took me some time to figure that out. Once I removed those from the unstructured text I used my UDF and DATA step to create a SAS table.
/***********************/ /* STEP 2 - CLEAN DATA */ /***********************/ /* Point to the FCMP function */ options cmplib=work.funcs; /* Clean the data */ data final_pdf_data; set casuser.pdf_data; /* Sent length of extract text column */ length FormFieldsData $10000; /* Drop unncessary columns */ drop path fileType fileSize firstFormField formStartPosition; /* Create a column with just the form entries */ firstFormField = 'Company Name:'; formStartPosition = find(content, firstFormField); /* Get form field input only */ FormFieldsData = strip(substr(content,formStartPosition)); /* Remove random special characters and whitespace from form entries*/ FormFieldsData = strip(FormFieldsData); FormFieldsData = tranwrd(FormFieldsData,'09'x,''); /* Remove tabs */ FormFieldsData = tranwrd(FormFieldsData,'0A'x,''); /* Remove carriage return line feed */ /* Extract values */ Date = find_pdf_value(FormFieldsData, 'Date:','Group2:'); Company_Name = find_pdf_value(FormFieldsData, 'Company Name:', 'First Name:'); /* Group2: */ Membership = find_pdf_value(FormFieldsData,'Group2:','Member ID:'); Member_ID = find_pdf_value(FormFieldsData, 'Member ID:','Group3:'); First_Name = find_pdf_value(FormFieldsData, 'First Name:', 'Last Name:'); Last_Name = find_pdf_value(FormFieldsData, 'Last Name:', 'Address:'); Address = find_pdf_value(FormFieldsData, 'Address:', 'City:'); City = find_pdf_value(FormFieldsData, 'City:','State:'); State = find_pdf_value(FormFieldsData, 'State:', 'Zip:'); Zip = find_pdf_value(FormFieldsData, 'Zip:', 'Phone:'); Phone = find_pdf_value(FormFieldsData, 'Phone:', 'Email:'); Email = find_pdf_value(FormFieldsData, ' Email:', 'undefined_2:'); /* Group3: */ Membership_Status = find_pdf_value(FormFieldsData, 'Group3:','undefined:'); /* undefined: */ Service_Consulting = find_pdf_value(FormFieldsData, 'undefined:', 'Comments:'); /* undefined_2: */ Service_Mentoring = find_pdf_value(FormFieldsData, 'undefined_2:', 'undefined_3:'); /* undefined_3: */ Service_Live_Training = find_pdf_value(FormFieldsData, 'undefined_3:', 'Date:'); /* Comments is the last value. Find Comments: then read the rest of the text */ Comments = substr(FormFieldsData,find(FormFieldsData,'Comments:')+length('Comments:')); run; /* Preview the final data */ proc print data=work.final_pdf_data; run; |
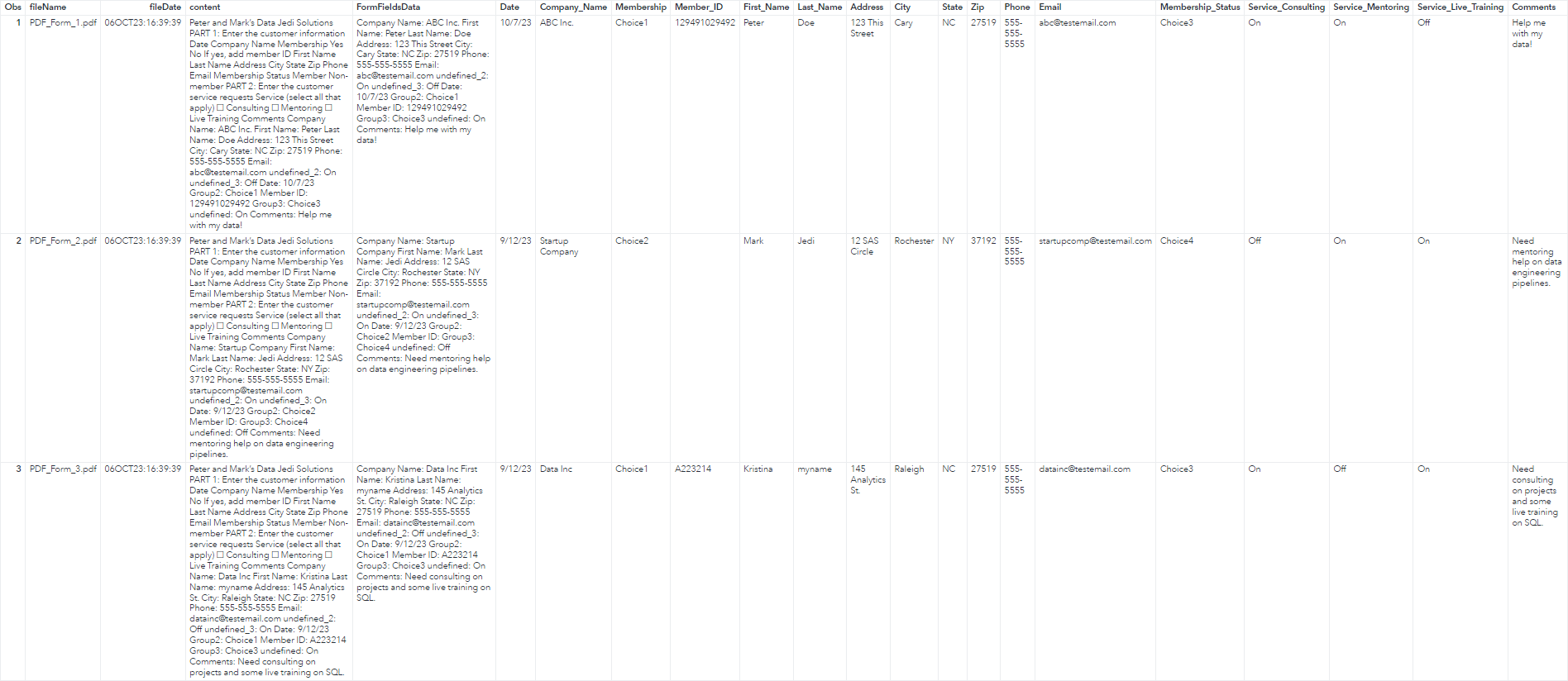
The results show the unstructured text was cleaned and a structured table was created! Now what can I do with this data? Off the top of my head maybe I'll create a dashboard to analyze this information using SAS Visual Analytics.
Summary
The SAS Viya platform provides a variety of benefits to users. From running traditional SAS code on the Compute server, using the CAS server's massively parallel processing capabilities, running new algorithms, using point and click applications, and even coding in open source languages like Python and R. In this post I focused on using the CAS server to easily extract text from PDF files, and then used the traditional SAS DATA step to clean the unstructured text and create a table. Instead of solving this with SAS code, you could of also used Python integration to SAS Viya. Maybe I'll show you how to do that next!
