Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. In this post I'll discuss how to remove duplicate rows from a distributed CAS table using the both the Pandas API in the SWAT package and the native CAS action. The Pandas API drop_duplicates method was introduced to the SWAT package in version 1.13.1.
Load and prepare data in the CAS server
For this example, I'll use the same data from the pandas drop_duplicate method documentation. I'll use the small table for training purposes. Remember, the distributed CAS server is typically reserved for larger data.
To create the CAS table for this post, run the code found in the block below. It creates a client-side DataFrame and uses the upload_frame SWAT method to load the DataFrame to the CAS server as a distributed table named DUP_TBL and places it in the Casuser caslib. The upload_frame method returns a client-side reference to the CAS table and stores it in the variable castbl. Make sure to add your CAS connection information in the CAS method.
## Packages import swat import pandas as pd ## Connect to the CAS server conn = swat.CAS(/*Enter your connection information */) ## Create the local DataFrame df = pd.DataFrame({ 'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'], 'style': ['cup', 'cup', 'cup', 'pack', 'pack'], 'rating': [4, 4, 3.5, 15, 5] }) # Load the DataFrame to CAS as a distributed CASTable castbl = conn.upload_frame(df, casout = {'name':'dup_tbl', 'caslib':'casuser', 'replace':True}) ## View the value of castbl and view rows from the CAS table display(type(castbl), castbl.head()) ## and the results NOTE: Cloud Analytic Services made the uploaded file available as table DUP_TBL in caslib CASUSER(Peter). NOTE: The table DUP_TBL has been created in caslib CASUSER(Peter) from binary data uploaded to Cloud Analytic Services. swat.cas.table.CASTable |
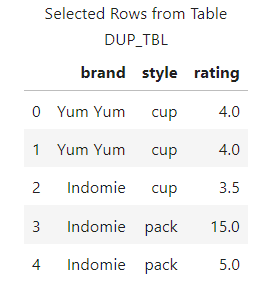
The results show the DataFrame was uploaded to the distributed CAS server successfully, and a client-side reference has been made to the CAS table in the variable castbl.
Using the drop_duplicates method in the SWAT package
Starting in SWAT 1.13.1 you can use the drop_duplicates method on a CAS table. The method works similarly to the pandas drop_duplicates method. However, there is a new parameter when using the SWAT method.
Remove duplicate rows based on all columns
For example, what if you want to remove all duplicate rows based on all columns and create a new CAS table with the results? All you need to do is specify the CAS table, then the drop_duplicates method. The biggest change in the SWAT drop_duplicates method is that you need to add the casout parameter to specify output CAS table information. Lastly, I'll add the tableInfo action to view available in-memory tables in the Casuser caslib.
no_dup_castbl = castbl.drop_duplicates(casout = {'name':'drop_dups', 'caslib':'casuser'}) conn.tableInfo(caslib = 'casuser') |
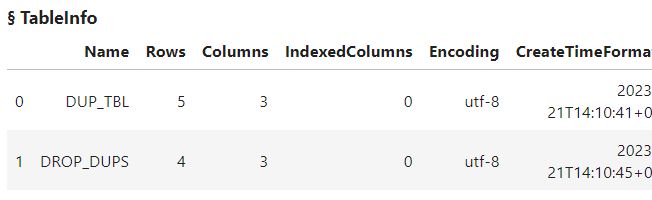
The results show that the drop_duplicates method created a new CAS table named DROP_DUPS in the Casuser caslib. The new table has four rows, removing the one entirely duplicated row from the original table.
The drop_duplicates method returns a client-side reference to the new CAS table. To work with the new CAS table, execute methods on the no_dup_castbl CASTable object. Here I'll execute the SWAT head method to preview the CAS table.
no_dup_castbl.head() |
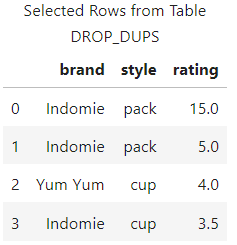
The results show that the duplicate row was removed.
Remove duplicate rows based on specific columns
The SWAT drop_duplicates method also enables you to drop duplicate rows based on specific columns like its pandas counterpart. Simply add a column (or list of columns) to the subset parameter. Then use the casout parameter to create a new CAS table named DROP_DUPS_SUBSET in the Casuser caslib. Finally, run the head method to preview the new CAS table.
no_dup_subset = castbl.drop_duplicates(subset=['brand','style'], casout={'name':'drop_dups_subset', 'caslib':'casuser'}) no_dup_subset.head() |
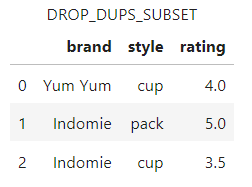
The results show that duplicate rows based on the columns brand and subset were removed. As of SWAT version 1.13.1 you cannot specify which rows to output using the keep parameter.
Using the native CAS action to remove duplicate rows
You can also use the native deduplication.deduplicate CAS action to remove duplicate rows. To use the action you first have to load the deduplication action set.
conn.loadActionSet('deduplication') |
Next, use the deduplicate action within the action set to remove duplicate rows. In the deduplicate action you must specify which columns to use to determine duplicate rows. This is done by adding the columns in the groupby parameter of the CASTable object. In this example, I'll create a list of all the columns in the CAS table and add that to the groupby parameter. Then, in the action you specify the noDupKeys parameter to eliminate rows that have duplicate group-by variable values. Only one row per group is retained. Further, add the casout parameter to specify the name and location of the new distributed CAS table.
colNames = castbl.columns.to_list() castbl.groupby = colNames castbl.deduplicate(noDupkeys = True, casout = {'name':'no_dup_rows_action', 'caslib':'casuser'}) ## and the results NOTE: There were 5 rows read from the table DUP_TBL. NOTE: The table no_dup_rows_action has 4 rows and 3 columns. |
Lastly, I'll run the tableInfo action to view available CAS tables.
conn.tableInfo(caslib = 'casuser') |
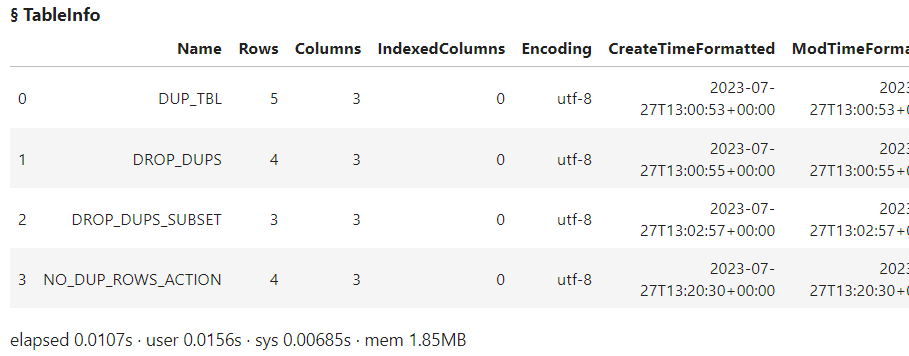
The results show that the new CAS table NO_DUP_ROWS_ACTION was created and removed the single duplicate row. To use the new table simply create a client-side reference to it using the swat.CASTable method.
Summary
The SWAT package blends the world of pandas and CAS to process your distributed data. In this example, I focused on showing both the Pandas API drop_duplicate method and the deduplicate CAS action from the SWAT package to remove duplicate rows.
