Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. In this post I'll discuss saving CAS tables to a caslib's data source as a file. This is similar to saving pandas DataFrames using to_ methods.
Load and preview the CAS table
First, I imported the necessary packages and connected my Python client to the distributed CAS server and named my connection conn. Second, I loaded the warranty_claims_0017.sashdat file from the Samples caslib into memory as a distributed CAS table. The Samples caslib should be available in your environment. Lastly, I referenced the CAS table in the variable castbl and preview the table.
For more information about loading server-side files into memory check out Part 5 - Loading Server-Side Files into Memory.
## Packages import swat import os import pandas as pd import numpy as np ## Options pd.set_option('display.max_columns', 50) ## Connect to CAS conn = swat.CAS() ## enter CAS connection information ## Load the data into CAS conn.loadTable(path='WARRANTY_CLAIMS_0117.sashdat', caslib='samples', casout={'name':'warranty_claims', 'caslib':'casuser', 'replace':True}) ## Reference the CAS table in a variable castbl = conn.CASTable('warranty_claims', caslib = 'casuser') ## Preview the CAS table df = castbl.head() ci = castbl.columnInfo() display (df, ci) # and the results NOTE: Cloud Analytic Services made the file WARRANTY_CLAIMS_0117.sashdat available as table WARRANTY_CLAIMS in caslib CASUSER(Peter). |
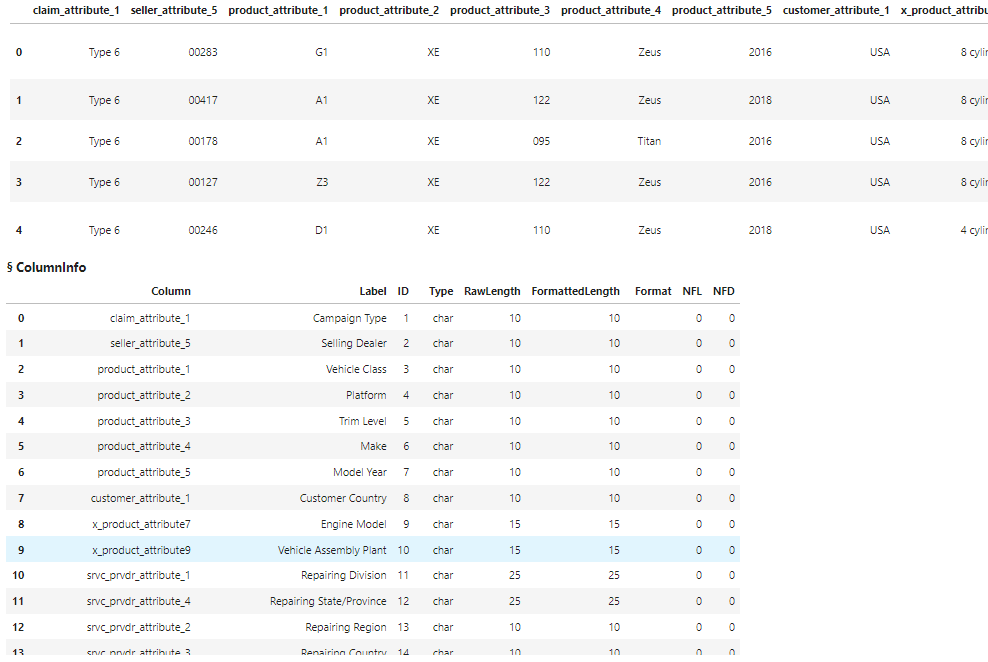
Results show five rows and the column metadata of the CAS table. Notice the column names are vague but the column labels are detailed.
Prepare the CAS table
After the table is loaded into memory, I'll prepare the CAS table by completing the following:
- Replace column names with the column labels all lower cased and spaces replaced with underscores.
- Drop unnecessary columns.
- Create a new column named car_id that concatenates the make, product_model and platform columns.
- Display the parameters of the CASTable object castbl, and preview five rows.
I won't go into detail of the code. I use a combination of familiar Python and SAS Viya techniques from Part 8 - Creating Calculated Columns and Part 11 - Rename Columns.
## ## RENAME AND DROP COLUMNS ## Use the current column labels as the column names ## ## Store the current column names and labels in a dataframe df_col_names = castbl.columnInfo()['ColumnInfo'].loc[:,['Column','Label']] ## Create a list of dictionaries of how to rename each column using the column labels renameColumns = [] for row in df_col_names.iterrows(): ## Store current column name colName = row[1].values[0] ## Store current column label and clean up labelName = row[1].values[1].replace(' ','_').lower() ## Create a dictionary of the column to rename, and how to rename it columnDict = dict(name = colName, rename = labelName) ## Add a date format to columns if the column name contains the word date if columnDict['rename'].find('date') > 0: columnDict['format'] = 'DATE9.' ## Create a list of dictionaries, one dictionary for each column renameColumns.append(columnDict) ## List of columns to drop using the updated columns names dropColumns = ['defect_code','repairing_division','usage_value','campaign_type','customer_country','ship_year', 'product_unit_assembly_date','primary_replaced_material_group_code','primary_labor_group_code', 'selling_dealer','vehicle_class','ship_date', 'total_claim_count', 'primary_labor_code', 'defect_key', 'primary_replaced__material_id'] ## Apply new column names and drop columns to the CAS table castbl.alterTable(columns = renameColumns, drop = dropColumns) ## ## CREATE A NEW COLUMN ## ## Create a new column in the table by combining make, model and platform castbl.eval("car_id = strip(make)|| '-' || strip(product_model) || '-' || strip(platform)") ## ## PREVIEW THE CHANGES ## ## View the CASTable object parameters and 5 rows display(castbl, castbl.head()) |
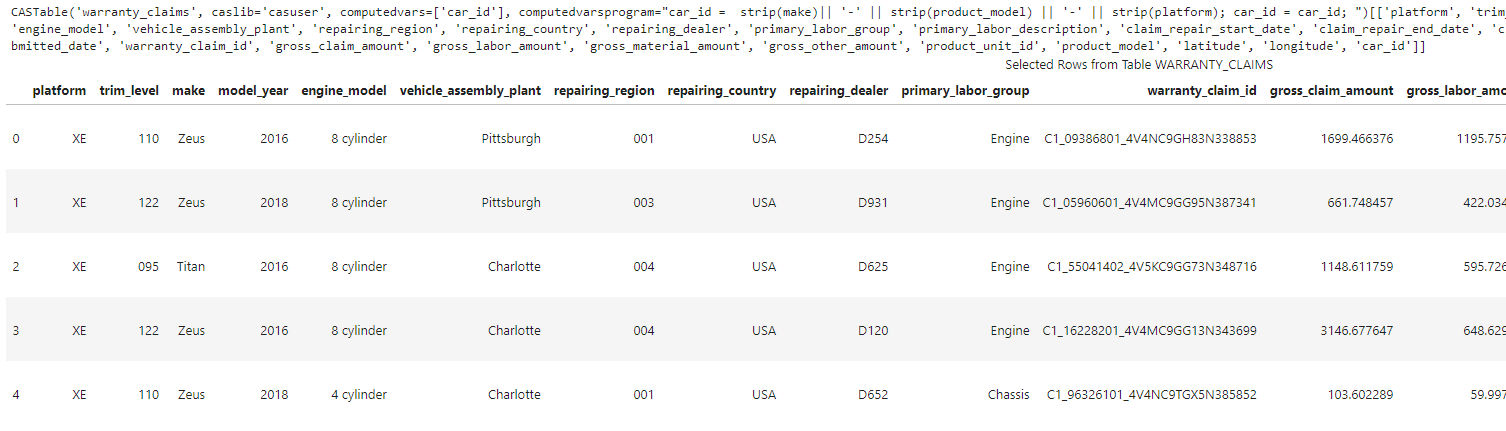
The CASTable object stores parameters on how to create the new CAS table and the table preview shows the updated column names.
Create a new CAS table
Once the castbl CASTable object is ready, I'll create a new CAS table named warranty_final in the Casuser caslib using the copyTable action (in Viya 3.5 use partition instead).
## Create a new CAS table for the final table castbl.copyTable(casout = {'name':'warranty_final', 'caslib':'casuser', 'replace':True}) |
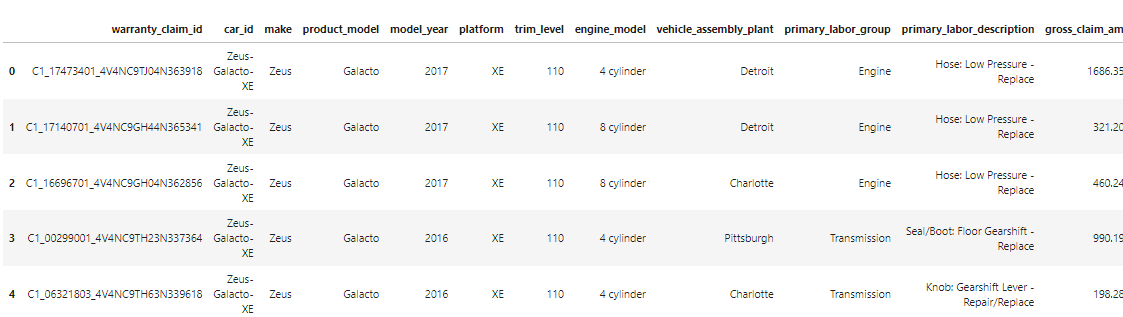
Since this will be the final table, I'll reorganize the columns to make it easier to work with. I'll reference the warranty_final CAS table in the variable finalTbl, then rearrange the columns and preview the table.
## Reference the new CAS table and reorganize columns finalTbl = conn.CASTable('warranty_final', caslib = 'casuser') ## Specify the order of the columns newColumnOrder = ['warranty_claim_id', 'car_id', 'make', 'product_model', 'model_year', 'platform', 'trim_level', 'engine_model','vehicle_assembly_plant', 'primary_labor_group', 'primary_labor_description', 'gross_claim_amount', 'gross_labor_amount', 'gross_material_amount', 'gross_other_amount', 'product_unit_id', 'repairing_state_province', 'repairing_region', 'repairing_country', 'repairing_dealer', 'latitude', 'longitude', 'claim_repair_start_date', 'claim_repair_end_date', 'claim_processed_date', 'claim_submitted_date','service_year_date'] finalTbl.alterTable(columnOrder = newColumnOrder) ## Preview the CAS table finalTbl.head() |
Save the CAS table as a file
Just like pandas DataFrames, CAS tables are in-memory. There are times you will want to save them back to disk. In CAS use the table.save CAS action to save the in-memory CAS table back to disk as a file (or back to a database). The save action is similar to saving a DataFrame using pandas to_ methods. For example, I'll save the warranty_final CAS table as a CSV file named warranty_final.csv in the Casuser caslib.
finalTbl.save(name = 'warranty_final.csv', caslib = 'casuser') # and the results NOTE: Cloud Analytic Services saved the file warranty_final.csv in caslib CASUSER(Peter). |
The save action enables you to easily save the CAS table as other file formats. Here I'll save it as a PARQUET file.
finalTbl.save(name = 'warranty_final.parquet', caslib = 'casuser') # and the results NOTE: Cloud Analytic Services saved the file warranty_final.parquet in caslib CASUSER(Peter). |
You can also save them as a SASHDAT file. A SASHDAT file is an the in-memory copy of a distributed CAS table on disk. They also store additional SAS information like column labels and formats.
finalTbl.save(name = 'warranty_final.sashdat', caslib = 'casuser') # and the results NOTE: Cloud Analytic Services saved the file warranty_final.sashdat in caslib CASUSER(Peter). |
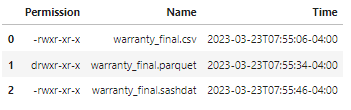
I'll run the fileInfo action to view available files in the Casuser caslib. I'll use the % wildcard character to find all files that begin with warranty_final. Then manipulate the CASResults object to access the SASDataFrame and select the Permission, Name and Time columns. For more information working with results from CAS actions check out Part 2 - Working with CAS Actions and CASResults Objects.
(conn.fileInfo(caslib = 'casuser', path='warranty_final%')['FileInfo'] .loc[:,['Permission','Name', 'Time']]) |
Summary
The SWAT package blends the world of pandas and CAS to process your distributed data in SAS Viya. In this example you learned how to save in-memory CAS tables back to disk using the save CAS action. The save action provides additional parameters that you can use to modify how you save your tables. Using the save CAS Action is similar to using a to_ method in pandas to save a DataFrame as a file.
Additional and related resources
- Getting Started with Python Integration to SAS® Viya® - Index
- SWAT API Reference
- table.save CAS action
- SAS® Cloud Analytic Services: Fundamentals
- CAS Action Documentation
- CAS Action! - a series on fundamentals
- SAS Course - SAS® Viya® and Python Integration Fundamentals
