In part 1 of this post, we looked at setting up Spark jobs from Cloud Analytics Services (CAS) to load and save data to and from Hadoop. Now we are moving on to the next step in the analytic cycle, scoring data in Hadoop and executing SAS code as a Spark job. The Spark scoring jobs execute using SAS In-Database Technologies for Hadoop.
The integration of the SAS Embedded Process and Hadoop allows scoring code to run directly on Hadoop. As a result, publishing and scoring of both DS2 and Data step models occur inside Hadoop. Furthermore, access to Spark data exists through the SAS Workspace Server or the SAS Compute Server using SAS/ACCESS to Hadoop, or from the CAS server using SAS Data Connectors.
Scoring Data from CAS using Spark
SAS PROC SCOREACCEL provides an interface to the CAS server for DS2 and DATA step model publishing and scoring. Model code is published from CAS to Spark and then executed via the SAS Embedded Process.
PROC SCOREACCEL supports a file interface for passing the model components (model program, format XML, and analytic stores). The procedure reads the specified files and passes their contents on to the model-publishing CAS action. In this case, the files must be visible from the SAS client.
CAS publishModel and runModel actions publish and execute score data in Spark:
%let CLUSTER="/opt/sas/viya/config/data/hadoop/lib: /opt/sas/viya/config/data/hadoop/lib/spark:/opt/sas/viya/config/data/hadoop/conf"; proc scoreaccel sessref=mysess1; publishmodel target=hadoop modelname="simple01" modeltype=DS2 /* filelocation=local */ programfile="/demo/code/simple.ds2" username="cas" modeldir="/user/cas" classpath=&CLUSTER. ; runmodel target=hadoop modelname="simple01" username="cas" modeldir="/user/cas" server=hadoop.server.com' intable="simple01_scoredata" outtable="simple01_outdata" forceoverwrite=yes classpath=&CLUSTER. platform=SPARK ; quit; |
In the PROC SCOREACCEL example above, a DS2 model is published to Hadoop and executed with the Spark processing engine. The CLASSPATH statement specifies a link to the Hadoop cluster. The input and output tables, simple01_scoredata and simple01_outdata, already exist on the Hadoop cluster.
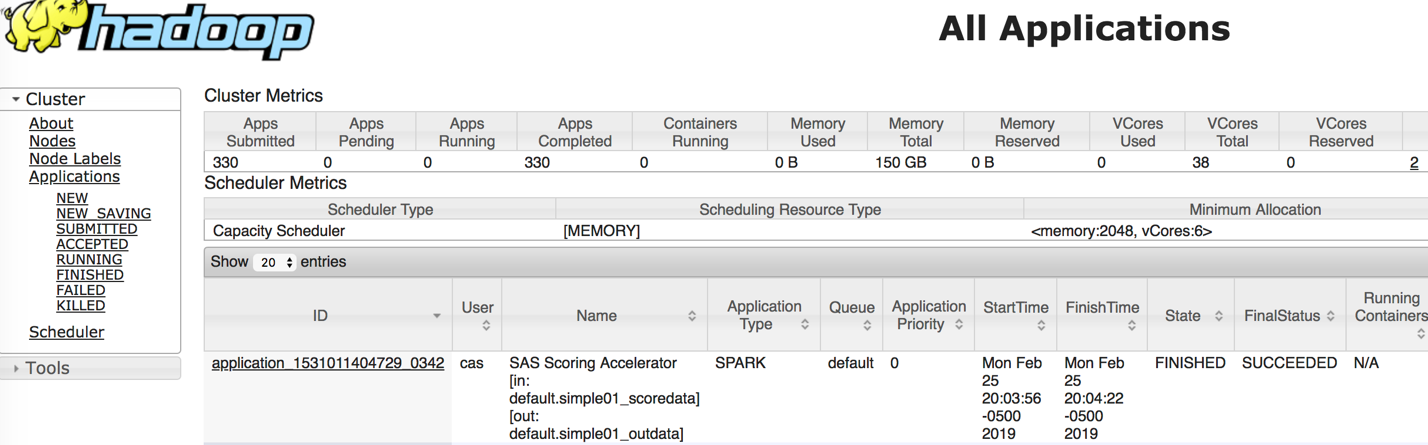
As you can see in the image above, the model is scored in Spark using the SAS Scoring Accelerator. The Spark job name reflects the input and output tables.
Scoring Data from MVA SAS using Spark
Steps to run a scoring model in Hadoop:
- Create a traditional scoring model using SAS Enterprise Miner or an analytic store scoring model, generated using SAS Factory Miner HPFOREST or HPSVM components.
- Specify the Hadoop connection attributes: %let indconn= user=myuserid;
- Use the INDCONN macro variable to provide credentials to connect to the Hadoop HDFS and Spark. Assign the INDCONN macro before running the %INDHD_PUBLISH_MODEL and the %INDHD_RUN_MODEL macros.
- Run the %INDHD_PUBLISH_MODEL macro.
- translates the scoring model into the sasscore_modelname.ds2 file, runs scoring inside the SAS Embedded Process
- takes the format catalog, if available, and produces the sasscore_modelname.xml file. This file contains user-defined formats for the published scoring model.
- uses SAS/ACCESS Interface to Hadoop to copy the sasscore_modelname.ds2 and sasscore_modelname.xml scoring files to HDFS
- Run the %INDHD_RUN_MODEL macro.
With traditional model scoring, the %INDHD_PUBLISH_MODEL performs multiple tasks using some of the files created by the SAS Enterprise Miner Score Code Export node. Using the scoring model program (score.sas file), the properties file (score.xml file), and (if the training data includes SAS user-defined formats) a format catalog, this model performs the following tasks:
The %INDHD_RUN_MODEL macro initiates a Spark job that uses the files generated by the %INDHD_PUBLISH_MODEL to execute the DS2 program. The Spark job stores the DS2 program output in the HDFS location specified by either the OUTPUTDATADIR= argument or by the element in the HDMD file.
Here is an example:
option set=SAS_HADOOP_CONFIG_PATH="/opt/sas9.4/Config/Lev1/HadoopServer/conf"; option set=SAS_HADOOP_JAR_PATH="/opt/sas9.4/Config/Lev1/HadoopServer/lib:/opt/sas9.4/Config/Lev1/HadoopServer/lib/spark"; %let scorename=m6sccode; %let scoredir=/opt/code/score; option sastrace=',,,d' sastraceloc=saslog; option set=HADOOPPLATFORM=SPARK; %let indconn = %str(USER=hive HIVE_SERVER=’hadoop.server.com'); %put &indconn; %INDHD_PUBLISH_MODEL( dir=&scoredir., datastep=&scorename..sas, xml=&scorename..xml, modeldir=/sasmodels, modelname=m6score, action=replace); %INDHD_RUN_MODEL(inputtable=sampledata, outputtable=sampledata9score, scorepgm=/sasmodels/m6score/m6score.ds2, trace=yes, platform=spark); |
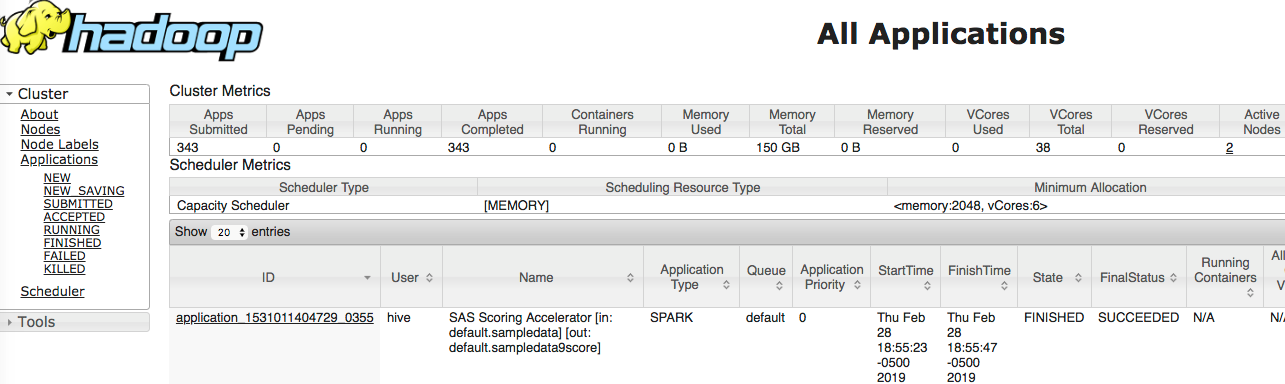
To execute the job in Spark, either set the HADOOPPLATFORM= option to SPARK or set PLATFORM= to SPARK inside the INDHD_RUN_MODEL macro. The SAS Scoring Accelerator uses SAS Embedded Process to execute the Spark job with the job name containing the input table and output table.
Executing user-written DS2 code using Spark
User-written DS2 programs can be complex. When running inside a database, a code accelerator execution plan might require multiple phases. Because of Scala program generation that integrates with the SAS Embedded Process program interface to Spark, the many phases of a Code Accelerator job reduces to one single Spark job.
In-Database Code Accelerator
The SAS In-Database Code Accelerator on Spark is a combination of generated Scala programs, Spark SQL statements, HDFS files access, and DS2 programs. The SAS In-Database Code Accelerator for Hadoop enables the publishing of user-written DS2 thread or data programs to Spark, executes in parallel, and exploits Spark’s massively parallel processing. Examples of DS2 thread programs include large transpositions, computationally complex programs, scoring models, and BY-group processing.
Below is a table of required DS2 options to execute as a Spark job.
| DS2ACCEL | Set to YES |
| HADOOPPLATFORM | Set to SPARK |
There are six different ways to run the code accelerator inside Spark, called CASES. The generation of the Scala program by the SAS Embedded Process Client Interface depends on how the DS2 program is written. In the following example, we are looking at Case 2, which is a thread and a data program, neither of them with a BY statement:
proc ds2 ds2accel=yes; thread work.workthread / overwrite=yes; method run(); set hdplib.cars; output; end; endthread; run; data hdplib.carsout (overwrite=yes); dcl thread work.workthread m; dcl double count; keep count make model; method run(); set from m; count+1; output; end; enddata; run; quit; |
The entire DS2 program runs in two phases. The DS2 thread program runs during Phase One, and its tasks execute in parallel. The DS2 data program runs during Phase Two using a single task.
Finally
With SAS Scoring Accelerator and Spark integration, users have the power and flexibility to process and score modeled data in Spark. SAS Code Accelerator and Spark integration takes the flexibility further to process any Spark data using DS2 code. Furthermore it is now possible for business to respond to use cases immediately and with higher reliability in the big data space.
