This article is not a tutorial on Hadoop, Spark, or big data. At the same time, no prerequisite knowledge of these technologies is required for understanding. We’ll give you enough background prior to diving into the details. In simplest terms, the Hadoop framework maintains the data and Spark controls and directs data processing. As an analogy, think of Hadoop as a train, big data as the payload, and Spark as the crew driving the train and organizing and distributing the goods.
Big data
I recently read that data volumes are doubling each year. Not that long ago we talked in terms of gigabytes. This quickly turned into terabytes and we’re now in the age of petabytes. The type of data is also changing. Data used to fit neatly into rows and columns. Now, nearly eighty percent of data is unstructured. All these trends and facts have led us to deal with massive amounts of data, aka big data. Maintaining and processing big data required creating technical frameworks. Next, we’ll investigate a couple of these tools.
Hadoop
Hadoop is a technology stack utilizing parallel processing on a distributed filesystem. Hadoop is useful to companies when data sets become so large or complex that their current solutions cannot effectively process the information in a reasonable amount of time. As the data science field has matured over the past few years, so has the need for a different approach to processing data.
Apache Spark
Apache Spark is a cluster-computing framework utilizing both iterative algorithms and interactive/exploratory data analysis. The goal of Spark is to keep the benefits of Hadoop’s scalable, distributed, fault-tolerant processing framework, while making it more efficient and easier to use. Using in-memory distributed computing, Spark provides capabilities over and above the batch model of Hadoop MapReduce. As a result, this brings to the big data world new applications of data science that were previously too expensive or slow on massive data sets.
Now let’s explore how SAS integrates with these technologies to maximize capturing, managing, and analyzing big data.
SAS capabilities to leverage Spark
SAS provides Hadoop data processing and data scoring capabilities using SAS/ACCESS Interface to Hadoop and In-Database Technologies to Hadoop with MapReduce or Spark as the processing framework. This addresses some of the traditional data management batch processing, huge volumes of extract, transform, load (ETL) data as well as faster, interactive and in-memory processing for quicker response with Spark.
In SAS Viya, SAS/ACCESS Interface to Hadoop includes SAS Data Connector to Hadoop. All users with SAS/ACCESS Interface to Hadoop can use the serial. Likewise, SAS Data Connect Accelerator to Hadoop can load or save data in parallel between Hadoop and SAS using SAS Embedded Process, as a Hive/MapReduce or Spark job.
Connecting to Spark in a Hadoop Cluster
There are two ways to connect to a Hadoop cluster using SAS/ACCESS Interface to Hadoop, based on the SAS environment: LIBNAME and CASLIB statements.
LIBNAME statement to connect to Spark from MVA SAS
options set=SAS_HADOOP_JAR_PATH="/third_party/Hadoop/jars/lib:/third_party/Hadoop/jars/lib/spark"; options set=SAS_HADOOP_CONFIG_PATH="/third_party/Hadoop/conf"; libname hdplib hadoop server="hadoop.server.com" port=10000 user="hive" schema='default' properties="hive.execution.engine=SPARK"; |
Parameters
| SAS_HADOOP_JAR_PATH | Directory path for the Hadoop and Spark JAR files |
| SAS_HADOOP_CONFIG_PATH | Directory path for the Hadoop cluster configuration files |
| Libref | The hdplib libref specifies the location where SAS will find the data |
| SAS/ACCESS Engine Name | HADOOP option to connect Hadoop engine |
| SERVER | Hadoop Hive server to connect |
| PORT | Listening Hive server Port. 10000 is the default, so it is not required. It is included just in case |
| USER and PASSWORD | Are not always required |
| SCHEMA | Hive schema to access. It is optional; by default, it connects to the “default” schema |
| PROPERTIES | Hadoop properties. Choosing SPARK for the property hive.execution.engine enables SAS Viya to use Spark as the execution platform |
CASLIB statement to connect from CAS
caslib splib sessref=mysession datasource=(srctype="hadoop", dataTransferMode="auto",username="hive", server="hadoop.server.com", hadoopjarpath="/opt/sas/viya/config/data/hadoop/lib:/opt/sas/viya/conf ig/data/hadoop/lib/spark", hadoopconfigdir="/opt/sas/viya/config/data/hadoop/conf", schema="default" platform="spark" dfdebug="EPALL" properties="hive.execution.engine=SPARK"); |
Parameters
| CASLIB | Space holder for the specified data access. The splib CAS library specifies the Hadoop data source |
| sessref | Holds the CAS library in a specific CAS session. mysession is the current active CAS session |
| SRCTYPE | Type of data source |
| DATATRANSFERMODE | Type of data movement between CAS and Hadoop. Accepts one of three values – serial, parallel, auto. When AUTO is specified, CAS choose the type of data transfer based on available license in the system. If Data Connect Accelerator to Hadoop has been licensed, parallel data transfer will be used, otherwise serial mode of transfer is used |
| HADOOPJARPATH | Hadoop and Spark JAR files location path on the CAS cluster |
| HADOOPCONFIGDIR | Hadoop configuration files location path on the CAS cluster |
| PLATFORM | Type of Hadoop platform to execute the job or transfer data using SAS Embedded Process. Default value is “mapred” for Hive MapReduce. When using “Spark”, data transfer and job executes as a Spark job |
| DFDEBUG | Used to receive additional information back from SAS Embedded Process transfers data in the SAS log |
| PROPERTIES | Hadoop properties. Choosing SPARK for the property hive.execution.engine enables SAS Viya to use Spark as the execution platform |
Data Access using Spark
SAS Data Connect Accelerator for Hadoop with the Spark platform option uses Hive as the query engine to access Spark data. Data movement happens between Spark and CAS through SAS generated Scala code. This approach is useful when data already exists in Spark and either needs to be used for SAS analytics processing or moved to CAS for massively parallel data and analytics processing.
Loading Data from Hadoop to CAS using Spark
Processing data in CAS offers advanced data preparation, visualization, modeling and model pipelines, and finally model deployment. Model deployment can be performed using available CAS modules or pushed back to Spark if the data is already in Hadoop.
Load data from Hadoop to CAS using Spark
proc casutil incaslib=splib outcaslib=casuser; load casdata="gas" casout="gas" replace; run; |
Parameters
| PROC CASUTIL | Used to process CAS action routines to process data |
| INCASLIB | Input CAS library to read data |
| OUTCASLIB | Output CAS library to write data |
| CASDATA | Table to load to the CAS in-memory server |
| CASOUT | Output CAS table name |
We can look at the status of the data load job using Hadoop' resource management and job scheduling application, YARN. YARN is responsible for allocating system resources to the various applications running in a Hadoop cluster and scheduling tasks to be executed on different cluster nodes.
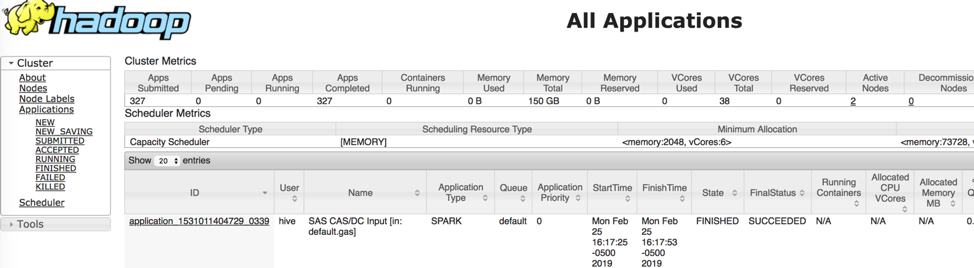
In the figure above, the YARN application executed the data load as a Spark job. This was possible because the CASLIB statement had Platform= Spark option specified. The data movement direction, in this case Hadoop to CAS uses the Spark job name, “SAS CAS/DC Input,” where “Input” is data loaded into CAS.
Saving Data from CAS to Hadoop using Spark
You can save data back to Hadoop from CAS at many stages of the analytic life cycle. For example, use data in CAS to prepare, blend, visualize, and model. Once the data meets the business use case, data can be saved in parallel to Hadoop using Spark jobs to share with other parts of the organization.
Using the SAVE CAS action to move data to Hadoop using Spark
proc cas; session mysession; table.save / caslib="splib" table={caslib="casuser", name="gas"}, name="gas.sashdat" replace=True; quit; |
Parameters
| PROC CAS | Used to execute CAS actionsets and actions to process data. “table” is the actionset and “save” is the action |
| TABLE | Location and name of the source table |
| NAME | Name of the target table saved to the Hadoop library using Spark |
We can verify the status of saving data from CAS to Hadoop using YARN application. Data from CAS saves as a Hadoop table using, Spark as the execution platform. Furthermore, as SAS Data Connect Accelerator for Hadoop transfers data in parallel, individual Spark executors in each of the Spark executor nodes handles data execution for that specific Hadoop cluster node.
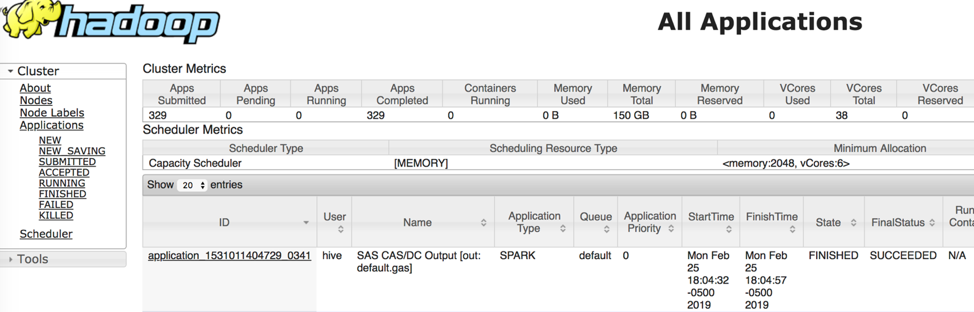
Finally, the SAVE data executed as a Spark job. As we can see from YARN, the Spark job named “SAS CAS/DC Output” specifies that the data moves from CAS to Hadoop.
Where we are; where we're going
We have so far traveled across the Spark pond to setup SAS libraries for Spark, Load and Save data from and to Hadoop using Spark. In the next section we’ll look at ways to Score data and execute SAS code inside Hadoop using Spark.

3 Comments
Hi Kumar,
Thank you for good information. I am looking forward your next blog.
When we use "Spark" to download the queried data from Hadoop using FedSQL procedure, do we add only properties options("hive.execution.engine=SPARK") to libname statement?
e.g.
libname test hadoop server="HADOOP" AUTHDOMAIN="XXXXX" schema="TEST"
cfg="/opt/sas/hadoopfiles/confs/sitexmls/merged-site.xml" properties="hive.execution.engine=SPARK";
The execution time (269 sec) was longer than when not added (119 sec) in my environment. Do you expect what is wrong?
Katsunari
Hi
I am prof Babiker Osman from Sudan Phd genetics breeding and statistical genetics I have used SAS for more than 35 years on unix and windows
For various areas
My interest now focus on big data using SAS Hadoop and spark
I wonder if I can have the three of them as one platform standalone computing
Yours
Babiker
Hi Babiker,
"Three of them as one platform standalone computing" - by three I believe you are thinking, SAS, Hadoop and Spark. YES, you can have one platform with all three in it.
1. On SAS Viya architecture: YES, you can have all three in one Hadoop cluster (consider that Hadoop cluster as one platform, which can also have SAS Viya CAS deployed), if SAS Viya and Hadoop cluster is collocated. Check this like additional info: https://documentation.sas.com/?docsetId=dplyml0phy0lax&docsetTarget=p11kijnm0v2dacn1pz4udp570rj9.htm&docsetVersion=3.4&locale=en#n18ljy4lrskdldn1a1li7hlkr5dj
2. On SAS 9.4 traditional platform: You would need SAS Grid Manager with Hadoop. Similar to SAS Viya, SAS Grid can be collocated with Hadoop cluster with SAS installed. More info here: https://blogs.sas.com/content/datamanagement/2016/01/13/sas-grid-manager-for-hadoop-nicely-tied-into-yarn/
feel free to reach out if you have more questions.