 With SAS Viya 3.3, a new data transfer mechanism “MultiNode Data Transfer” has been introduced to transfer data between the data source and the SAS’ Cloud Analytics Services (‘CAS’), in addition to Serial and Parallel data transfer modes. The new mechanism is an extension of the Serial Data Transfer mode. In MultiNode Data transfer mode each CAS Worker makes a simultaneous concurrent connection to read and write data from the source DBMS or Distributed data system.
With SAS Viya 3.3, a new data transfer mechanism “MultiNode Data Transfer” has been introduced to transfer data between the data source and the SAS’ Cloud Analytics Services (‘CAS’), in addition to Serial and Parallel data transfer modes. The new mechanism is an extension of the Serial Data Transfer mode. In MultiNode Data transfer mode each CAS Worker makes a simultaneous concurrent connection to read and write data from the source DBMS or Distributed data system.
In CAS, SAS Data connectors are used for Serial mode and SAS Data Connect Accelerators are used for Parallel mode data transfer between CAS and DBMS. The SAS Data connector can also be used for the MultiNode data transfer mechanism. In a multi-node CAS environment when the Data Connector is installed on all Nodes, the Data connector can take advantage of a multi-node CAS environment and make concurrent data access connections from each CAS worker to read and write data from the data source environment.
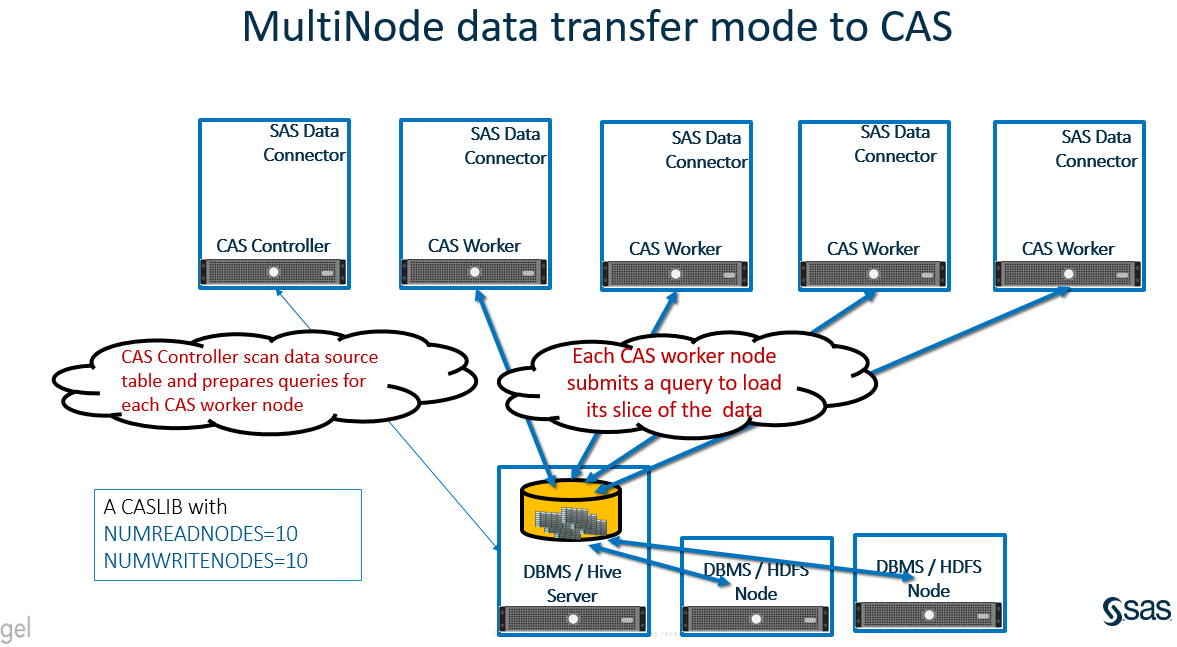
The CAS Controller controls the MultiNode Data transfer. It directs each CAS worker node on how to query the source data and obtain the needed data. The CAS Controller checks the source data table for the first numeric column and uses the values to divide the table into slices using a MOD function of the number of CAS nodes specified. The higher the Cardinality of the selected numeric column, the easier the data can be divided into slices. If CAS chooses a low cardinality column, you could end-up with poor data distribution on the CAS worker nodes. The CAS controller directs each CAS worker to submit a query to obtain the needed slice of data. During this process, each CAS worker makes an independent, concurrent request to the data source environment.
Data is transferred from the source environment to the CAS worker nodes directly using a single thread connection, bypassing the CAS Controller.
The following diagrams describe the data access from CAS to data source environment using MultiNode Data transfer Mode. CAS is hosted on a multi-node environment with SAS Data Connector installed on each node (CAS Controller and Workers). A CASLIB is defined with NUMREADNODES= and NUMWRITENODES= value other than 1. With each data table access request, the CAS controller scan through the source data table for the first numeric columns and use the value to prepare a query for each CAS worker to run. The CAS Worker node submits an individual query to get its slice of the data. Something like:
Select * from SourceTable where mod(NumericField, NUMREADNODES) = WorkerNodeNumber
The data moves from the DBMS gateway server to each CAS Worker Nodes directly using a single thread connection, bypassing the CAS Controller. It’s a kind of parallel load using the serial mechanism, but it’s not a massively parallel data load. You can notice the bottleneck at DBMS gateway server. The data transfers always passes through the DBMS gateway server to the CAS Worker nodes.
Prerequisites to enable MultiNode Data Transfer include:
- The CAS environment is a multi-node environment (multiple CAS Worker Nodes).
- The SAS Data Connector for the data source is installed on each CAS Worker, and Controller Node.
- The data source client connection components are installed on each CAS Worker, and Controller Node.
By default, SAS Data connector uses serial data transfer mode. To enable MultiNode Data Transfer mode you must use the NUMREADNODES= and NUMWRITENODES= parameters in CSLIB statement and specify value other than 1. If value is specified as 0, CAS will use all available CAS worker nodes. MultiNode Data Transfer Mode can use only number of available node, if you specify more than available nodes, the log prints a warning message.
The following code example describes the data load using “MultiNode” data transfer mode. It assigns a CASLIB using serial mode with NUMREADNODES=10 and NUMWRITENODES=10 and loads data from a Hive table to CAS. As NUMREADNODES= value is other than 1, it follows the MultiNode mechanism. You can notice in log, there is a warning message stating that the Number of Read node parameter exceeds the available Worker nodes. This is one way to verify whether CAS is using MultiNode data transfer mode, by specifying the higher number than available CAS worker nodes. If you specify value for NUMREADNODES =0, it will use all available nodes but no message or warning message in SAS log about multi node usage.
CAS mySession SESSOPTS=( CASLIB=casuser TIMEOUT=99 LOCALE="en_US" metrics=true); caslib HiveSrl datasource=(srctype="hadoop", server="xxxxxxx.xxx", username="hadoop", dataTransferMode="SERIAL", NUMREADNODES=10, NUMWRITENODES=10, hadoopconfigdir="/opt/MyHadoop/CDH/Config", hadoopjarpath="/opt/MyHadoop/CDH/Jars", schema="default"); proc casutil; load casdata="prdsal2_1G" casout="prdsal2_1G" outcaslib="HiveSrl" incaslib="HiveSrl" ; quit; |
SAS Log extract:
…. 77 proc casutil; 78 ! load casdata="prdsal2_1G" casout="prdsal2_1G" 79 outcaslib="HiveSrl" incaslib="HiveSrl" ; NOTE: Executing action 'table.loadTable'. NOTE: Performing serial LoadTable action using SAS Data Connector to Hadoop. WARNING: The value of numReadNodes(10) exceeds the number of available worker nodes(7). The load will proceed with numReadNodes=7. … .. |
On the Database side, in this case Hive, note the queries submitted by CAS Worker Nodes. Each include the MOD function WHERE clause as described above.
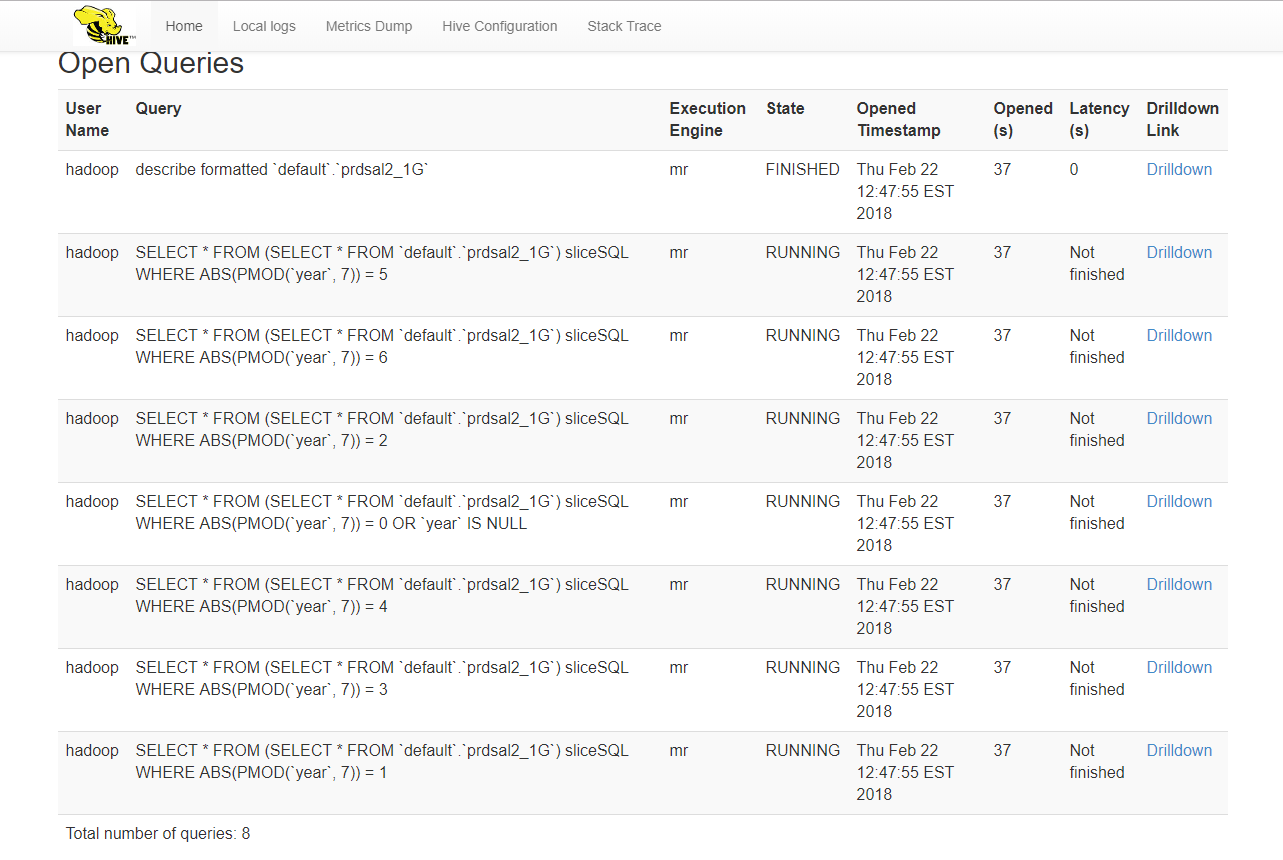 On Hadoop Resource Manager User Interface you can notice the corresponding job execution for each query submitted by CAS worker nodes.
On Hadoop Resource Manager User Interface you can notice the corresponding job execution for each query submitted by CAS worker nodes.
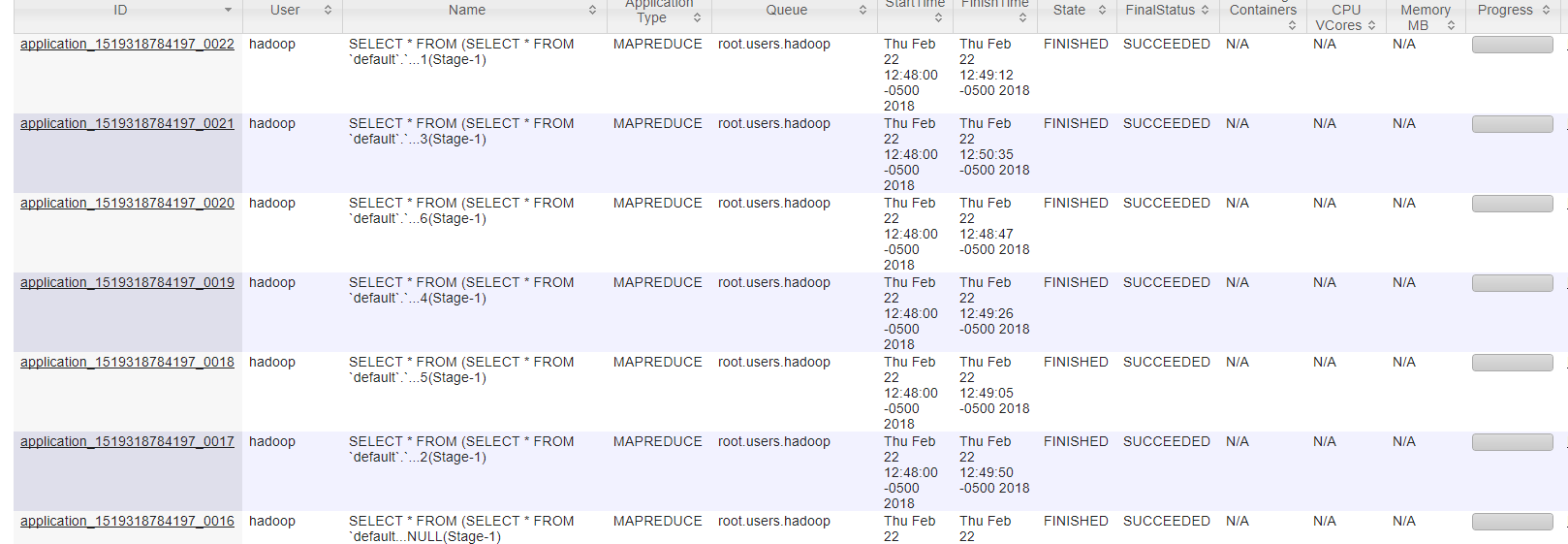
When using MultiNode mode to load data to CAS, data distribution is dependent on the cardinality of the numeric column selected by CAS during MOD function operation. You can notice the CAS data distribution for the above loaded table is not ideal, since it selected a column (‘year’) which is not ideal (in this case) for data distribution across CAS worker nodes. There is no option with MultiNode mechanism to specify a column name to be use for query preparation and eventually for data distribution.

If CAS cannot find suitable columns for MultiNode data transfer mode, it will use standard Serial mode to transfer data as shown in the following log:
…….. 74 74 ! load casdata="prdsal2_char" casout="prdsal2_char" 75 outcaslib="HiveSrl" incaslib="HiveSrl" ; NOTE: Executing action 'table.loadTable'. NOTE: Performing serial LoadTable action using SAS Data Connector to Hadoop. WARNING: The value of numReadNodes(10) exceeds the number of available worker nodes(7). The load will proceed with numReadNodes=7. WARNING: Unable to find an acceptable column for multi-node reads. Load will proceed with numReadNodes = 1. NOTE: Cloud Analytic Services made the external data from prdsal2_char available as table PRDSAL2_CHAR in caslib HiveSrl. ……. |
List of data platform supported with MultiNode Data Transfer using Data Connector:
- Hadoop
- Impala
- Oracle
- PostgreSQL
- Teradata
- Amazon Redshift
- DB2
- MS SQL Server
- SAP HANA
The order of data types that SAS uses to divide data into slices for MultiNode Data Read.
- INT (includes BIGINT, INTEGER, SMALLINT, TINYINT)
- DECIMAL
- NUMERIC
- DOUBLE
Multi-Node Write:
While this post focused on loading data from a data source into CAS, multi-node data transfer also works when saving from CAS back to the data source. The important parameter when saving is NUMWRITENODES instead of NUMREADNODES. The behavior of multi-node saving is similar to that of multi-node loading.
Summary:
The SAS Data Connector can be used for MultiNode data transfer by installing Data Connector and DBMS client components on all CAS Worker nodes without additional license fees. The source data is transferred directly from DBMS gateway server to CAS Worker Nodes being divided up by a simple MOD function. By using this mechanism, the optimum data distribution in CAS Nodes are not guaranteed. It’s suggested to use all CAS Worker Nodes by specifying NUMREADNODES=0 when loading data to CAS using MultiNode mode.

3 Comments
Hi Fabrice,
It seems the viya3.5 deployment process did not install the CAS as multi-node environment. You can check the ~/playbook/sas_viya_playbook/vars.yml file and see if it has 'mpp' listed under CAS_CONFIGURATION section as follows. If you have 4 cas worker server entry in inventory.ini, you also need to turn-on the 'mpp' mode in vars.yaml file to get MPP CAS environment.
varls.yml
-----------------------
......
...........
CAS_CONFIGURATION:
env:
CAS_DISK_CACHE: /mnt/cascache/cache01
#CAS_DISK_CACHE: /opt/sas/cas/cache01
#CAS_VIRTUAL_HOST: 'loadbalancer.company.com'
#CAS_VIRTUAL_PROTO: 'https'
#CAS_VIRTUAL_PORT: 443
cfg:
mode: 'mpp'
#gcport: 0
#httpport: 8777
#port: 5570
#colocation: 'none'
#SERVICESBASEURL: 'https://loadbalancer.company.com'
Regards,
-Uttam
Hello Uttam
Thanks for your useful article.
Can you just explain me "In a multi-node CAS environment when the Data Connector is installed on all Nodes"?
We deploy several cas servers in our environement :
[sas_casserver_worker]
CASWorker1
CASWorker2
CASWorker3
CASWorker4
We also deployed Impala odbc client on all servers, we configure odbc.ini on all servers and also modify our cas_usermods.settings on all server.
But we still obtain in the log :
NOTE: Performing serial LoadTable action using SAS Data Connector to Impala.
WARNING: The value of numReadNodes(9) exceeds the number of available worker nodes(1). The load will proceed with numReadNodes=1.
Maybe we miss something but we cant' find what.
Regards
Fabrice
Hi Fabrice,
Can you run CAS session statement as follows and see if the log says session using 4 worker nodes or 1 worker node !
Code:
-----
CAS mySession SESSOPTS=(CASLIB=casuser TIMEOUT=99 LOCALE="en_US" metrics=true);
-----
log:
--------------
1 %studio_hide_wrapper;
82 CAS mySession SESSOPTS=(CASLIB=casuser TIMEOUT=99 LOCALE="en_US" metrics=true);
NOTE: The session MYSESSION connected successfully to Cloud Analytic Services intcas01.race.sas.com using port 5570. The UUID is
f1acc4e2-5805-0945-ac62-9bceb01ca608. The user is gatedemo001 and the active caslib is CASUSERHDFS(gatedemo001).
....
.......
NOTE: The session is using 4 workers.
....
................
-------------------
Regards,
-Uttam