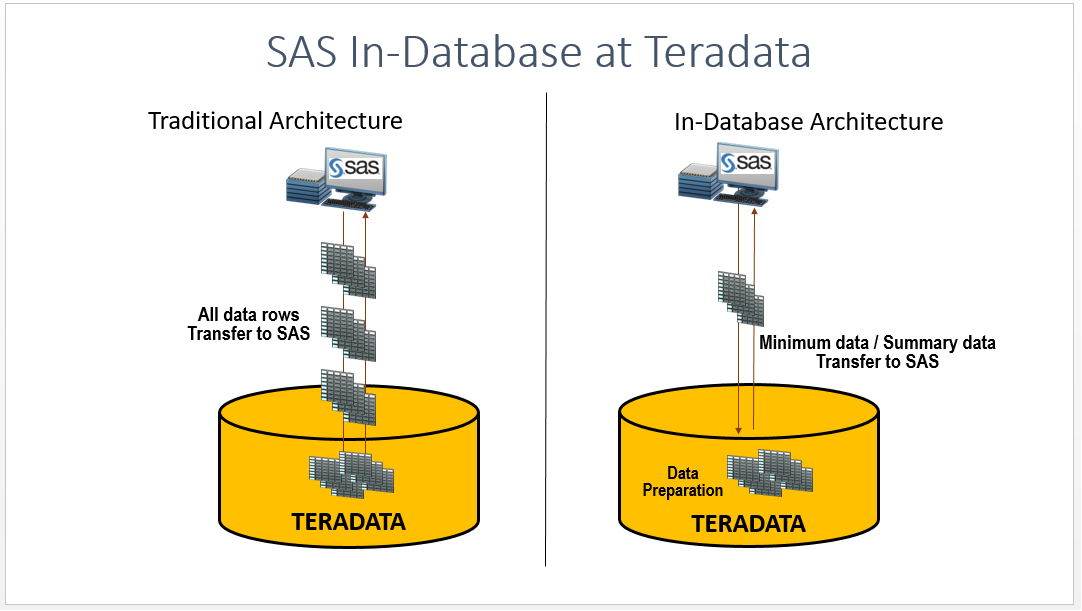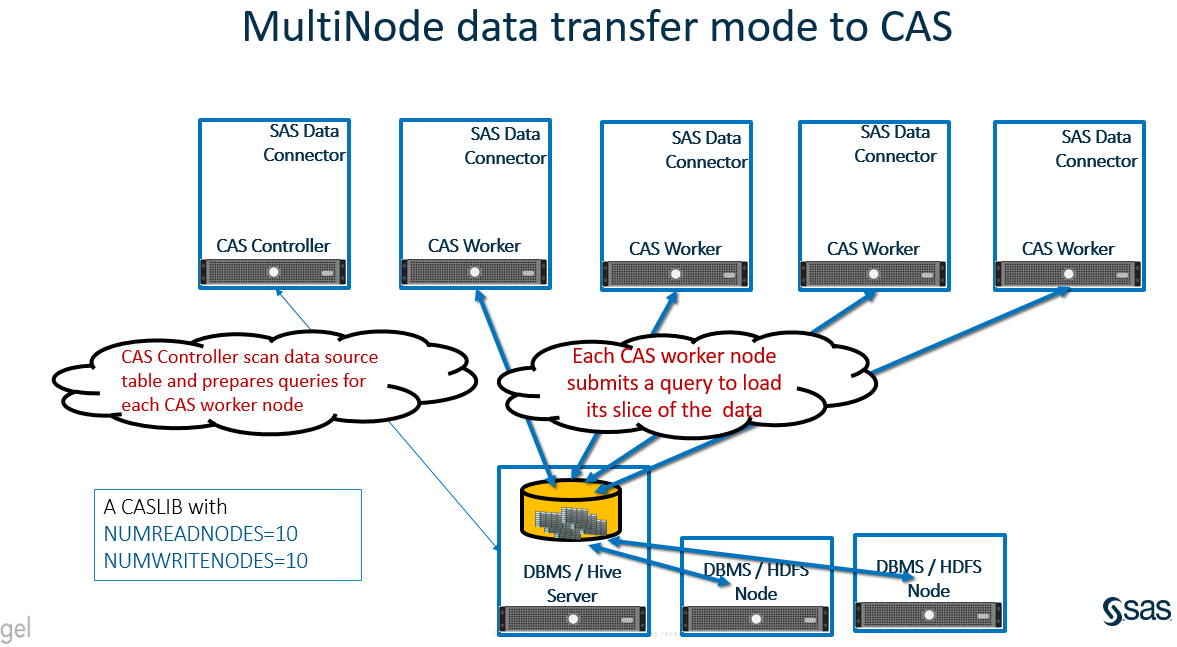
Multi Node Data Transfer to CAS

With SAS Viya 3.3, a new data transfer mechanism Multi Node Data Transfer has been introduced to transfer data between the data source and the SAS’ Cloud Analytics Services. Learn more about this feature.