 With the release of SAS® 9.4 M3, you can now access SAS Scalable Performance Data Engine (SPD Engine) data using Hive. SAS provides a custom Hive SerDe for reading SAS SPD Engine data stored on HDFS, enabling users to access the SPD Engine table from other applications.
With the release of SAS® 9.4 M3, you can now access SAS Scalable Performance Data Engine (SPD Engine) data using Hive. SAS provides a custom Hive SerDe for reading SAS SPD Engine data stored on HDFS, enabling users to access the SPD Engine table from other applications.
The SPD Engine Hive SerDe is delivered in the form of two JAR files. Users need to deploy the SerDe JAR files under “../hadoop-mapreduce/lib” and “../hive/lib” on all nodes of a Hadoop cluster to enable the environment. To access the SPD Engine table from Hive, you need to register the SPD Engine table under Hive metadata using the metastore registration utility provided by SAS.
The Hive SerDe is read-only and cannot serialize data for storage in HDFS. The Hive SerDe does not support creating, altering, or updating SPD Engine data in HDFS using HiveQL or other languages. For those functions, you would use the SPD Engine with SAS applications.
Requirements
Before you can access an SPD Engine table using Hive SerDe you have to perform the following:
- Deploy the SAS Foundation software using SAS Deployment Wizard.
- Select the product name “SAS Hive SerDe for SPDE Data”
This will create a subfolder under $sashome with the SerDe JAR files
[root@sasserver01 9.4]# pwd
/opt/sas/sashome/SASHiveSerDeforSPDEData/9.4
[root@sasserver01 9.4]# ls -l
total 88
drwxr-xr-x. 3 sasinst sas 4096 Mar 8 15:52 installs
-r-xr-xr-x. 1 sasinst sas 8615 Apr 15 2015 sashiveserdespde-installjar.sh
-rw-r--r--. 1 sasinst sas 62254 Jun 24 2015 sas.HiveSerdeSPDE.jar
-rw-r--r--. 1 sasinst sas 6998 Jun 24 2015 sas.HiveSerdeSPDE.nls.jar
[root@sasserver01 9.4]#
- You must be running a supported Hadoop distribution that includes Hive 0.13 or later:
> Cloudera CDH 5.2 or later
> Hortonworks HDP 2.1 or later
> MapR 4.0.2 or later
- The SPD Engine table stored in HDFS must have been created using the SPD Engine.
- The Hive SerDe is delivered as two JAR files, which must be deployed to all nodes in the Hadoop cluster.
- The SPD Engine table must be registered in the Hive metastore using the metastore registration utility supplied by SAS. You cannot use any other method to register tables.
Deploying the Hive SerDe on the Hadoop cluster
Deploy the SAS Hive SerDe on the Hadoop cluster by executing the script “sashiveserdespde-installjar.sh”. This script is located in the SAS Hive SerDe software deployed folder. Follow the steps below, which describe the SAS Hive SerDe deployment on a Hadoop cluster.
- Copy the script file along with two JAR files to one of the nodes (NameNode server). For example, in my test environment, files were copied to the sascdh01 (NameNode) server with user ‘hadoop’.
[hadoop@sascdh01 SPDEHiveSerde]$ pwd
/home/hadoop/SPDEHiveSerde
[hadoop@sascdh01 SPDEHiveSerde]$ ls -l
total 84
-rwxr-xr-x 1 hadoop hadoop 8615 Mar 8 15:57 sashiveserdespde-installjar.sh
-rw-r--r-- 1 hadoop hadoop 62254 Mar 8 15:57 sas.HiveSerdeSPDE.jar
-rw-r--r-- 1 hadoop hadoop 6998 Mar 8 15:57 sas.HiveSerdeSPDE.nls.jar
[hadoop@sascdh01 SPDEHiveSerde]$
- The node server (NameNode) must be able to use SSH to access the other data nodes in cluster. It’s recommended to execute the deployment script as user ‘root’ or with sudo su command.
- Switch user to ‘root’ or user with ‘sudo su’ permission.
- Set the Hadoop CLASSPATH to include the MapReduce and Hive Library installation directory. Set the SERDE_HOSTLIST to include the server where JAR files will be deployed. For example, for my test environment the following statement is used.
export CLASSPATH=/usr/lib/hive/lib/*:/usr/lib/hadoop-mapreduce/lib/*
export HADOOP_CLASSPATH=$CLASSPATH
export SERDE_HOSTLIST="xxxxx..xxxx.com xxxxx..xxxx.com xxxxx..xxxx.com"
- Execute the script as user ‘root’ to deploy the JAR files on all nodes under “ ../hive/lib” and “../hadoop-mapreduce/lib” subfolder. While running the script, provide the location of MapReduce and the Hive library installation folder as parameters to script.
For example:
sh sashiveserdespde-installjar.sh -mr /usr/lib/hadoop-mapreduce/lib -hive /usr/lib/hive/lib
[root@sascdh01 SPDEHiveSerde]# sh sashiveserdespde-installjar.sh -mr /usr/lib/hadoop-mapreduce/lib -hive /usr/lib/hive/lib
scp -q -o StrictHostKeyChecking=no -o PasswordAuthentication=no -o UserKnownHostsFile=/dev/null /root/Downloads/SPDEHiveSerde/sas.HiveSerdeSPDE.jar root@sascdh01:/usr/lib/hive/lib
....
.........
scp -q -o StrictHostKeyChecking=no -o PasswordAuthentication=no -o UserKnownHostsFile=/dev/null /root/Downloads/SPDEHiveSerde/sas.HiveSerdeSPDE.nls.jar root@sascdh03:/usr/lib/hadoop-mapreduce/lib
[root@sascdh01 SPDEHiveSerde]#
- Restart YARN/MapReduce and Hive services on the Hadoop cluster.
Registering the SAS Scalable Performance Data Engine table in Hive metadata
The SPD Engine table that you are planning to access from Hive must be registered to Hive metadata using the SAS provided metadata registration utility. You cannot use any other method to register tables. The utility reads an SPD Engine table’s metadata file (.mdf) in HDFS and creates Hive metadata in the Hive metastore as table properties. Registering the SPD Engine table projects a schema-like structure onto the table and creates Hive metadata about the location and structure of the data in HDFS.
Because the utility reads the SPD Engine table’s metadata file that is stored in HDFS, if the metadata is changed by the SPD Engine, you must re-register the table.
The metadata registration utility can be executed from one of the Hadoop cluster node server, preferably NameNode server. The code examples mentioned here are all from NameNode server.
The following steps describe the SPD Engine table registration to Hive metadata.
- Set the Hadoop CLASSPATH to include a directory with the client Hadoop configuration files and SerDe JAR files.
The following example is from my test environment where two SerDe JAR files are copied under the “/home/hadoop/SPDEHiveSerde/” subfolder. This subfolder is owned by OS user ‘hadoop’, i.e., the user who will execute the table registration utility. While exporting CLASSPATH, you must also include ../hive/lib folder as part of classpath. For the Hadoop configuration XML file, here we are using /etc/hive/conf folder. If you have a separate folder for storing Hadoop configuration files, you can plug in that folder.
export CLASSPATH=/home/hadoop/SPDEHiveSerde/*:/usr/lib/hive/lib/*
export SAS_HADOOP_CONFIG_PATH=/etc/hive/conf/
export HADOOP_CLASSPATH=$SAS_HADOOP_CONFIG_PATH:$CLASSPATH
As a result of exporting Hadoop CLASSPATH, the output from ‘hadoop classpath’ statement should look like as follows. Notice the value that you included in your previous export statement.
[hadoop@sascdh01 ~]$ hadoop classpath
/etc/hadoop/conf:/usr/lib/hadoop/lib/*:/usr/lib/hadoop/.//*:/usr/lib/hadoop-hdfs/./:/usr/lib/hadoop-hdfs/lib/*:/usr/lib/hadoop-hdfs/.//*:/usr/lib/hadoop-yarn/lib/*:/usr/lib/hadoop-yarn/.//*:/usr/lib/hadoop-mapreduce/lib/*:/usr/lib/hadoop-mapreduce/.//*:/etc/hive/conf/:/home/hadoop/SPDEHiveSerde/*:/usr/lib/hive/lib/*
[hadoop@sascdh01 ~]$
- Run the SerDe JAR command with appropriate command parameters and options to register the SPD Engine table. For example, the following command executes the SerDe JAR files and registers an SPD Engine table named stocks. It specifies the HDFS directory location (/user/lasradm/SPDEData) that contains the .mdf file of that SPD Engine table. The –table and –mdflocation parameters are required.
hadoop jar /home/hadoop/SPDEHiveSerde/sas.HiveSerdeSPDE.jar com.sas.hadoop.serde.spde.hive.MetastoreRegistration -table stocks -mdflocation /user/lasradm/SPDEData
[hadoop@sascdh01 ~]$ hadoop jar /home/hadoop/SPDEHiveSerde/sas.HiveSerdeSPDE.jar com.sas.hadoop.serde.spde.hive.MetastoreRegistration -table stocks -mdflocation /user/lasradm/SPDEData
16/03/09 16:46:35 INFO hive.metastore: Trying to connect to metastore with URI thrift://xxxxxxx.xxxx.xxx.com:9083
16/03/09 16:46:35 INFO hive.metastore: Opened a connection to metastore, current connections: 1
16/03/09 16:46:36 INFO hive.metastore: Connected to metastore.
16/03/09 16:46:36 INFO hive.MetastoreRegistration: Table is registered in the Hive metastore as default.stocks
[hadoop@sascdh01 ~]$
Reading SAS Scalable Performance Data Engine table data from Hive
Once the SPD Engine table is registered in Hive metadata, you can query the SPD Engine table data via Hive. If you describe the table with the formatted option, you will see that the data file locations are the SPD Engine locations. The Storage section provides information about SerDe library, which is ‘com.sas.hadoop.serde.spde.hive.SpdeSerDe’.
hive> show tables;
OK
…..
…….
stocks
Time taken: 0.025 seconds, Fetched: 15 row(s)
hive>
hive> select count(*) from stocks;
Query ID = hadoop_20160309171515_9db3aed5-0ba4-40cc-acc4-56acee10a275
Total jobs = 1
…..
……..
………………
Total MapReduce CPU Time Spent: 2 seconds 860 msec
OK
699
Time taken: 38.734 seconds, Fetched: 1 row(s)
hive>
hive> describe formatted stocks;
OK
# col_name data_type comment
stock varchar(9) from deserializer
date date from deserializer
open double from deserializer
high double from deserializer
low double from deserializer
close double from deserializer
volume double from deserializer
adjclose double from deserializer
# Detailed Table Information
Database: default
Owner: anonymous
CreateTime: Wed Mar 09 16:46:36 EST 2016
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://xxxxxxxxx.xxxx.xxx.com:8020/user/lasradm/SPDEData/stocks_spde
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE false
EXTERNAL TRUE
adjclose.length 8
adjclose.offset 48
close.length 8
close.offset 32
date.length 8
date.offset 0
high.length 8
high.offset 16
low.length 8
low.offset 24
numFiles 0
numRows -1
open.length 8
open.offset 8
rawDataSize -1
spd.byte.order LITTLE_ENDIAN
spd.column.count 8
spd.encoding ISO-8859-1
spd.mdf.location hdfs://xxxxxxxxx.xxxx.xxx.com:8020/user/lasradm/SPDEData/stocks.mdf.0.0.0.spds9
spd.record.length 72
spde.serde.version.number 9.43
stock.offset 56
totalSize 0
transient_lastDdlTime 1457559996
volume.length 8
volume.offset 40
# Storage Information
SerDe Library: com.sas.hadoop.serde.spde.hive.SpdeSerDe
InputFormat: com.sas.hadoop.serde.spde.hive.SPDInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.166 seconds, Fetched: 60 row(s)
hive>
How SAS Scalable Performance Data Engine SerDE reads data
The SerDe reads the data using the encoding of the SPD Engine table. Make sure that the SPD Engine table name is appropriate for the encoding associated with the cluster.
Current SerDe Implementation of Data Conversion from SAS to Hive
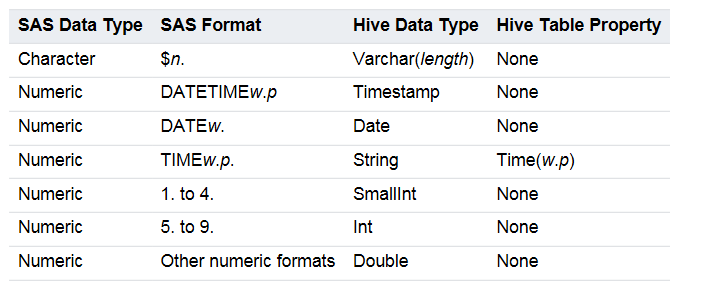
Limitations
If the SPD Engine table in HDFS has any of the following features, it cannot be registered in Hive or use the SerDe. You must access it by going through SAS and the SPD Engine. The following table features are not supported:
- Compressed or encrypted tables
- Tables with SAS informats
- Tables that have user-defined formats
- Password-protected tables
- Tables owned by the SAS Scalable Performance Data Server
Reference documents
SAS(R) 9.4 SPD Engine: Storing Data in the Hadoop Distributed File System, Third Edition
