Hash tables are a very powerful and flexible data structure. Most SAS applications of hash tables focus on just one of their many powerful facilities: table lookup. Hash tables are a fantastic table lookup tool and their use for that should never be diminished. However, hash tables can do so much more and that is why we decided to write the SAS Press book, Data Management Solutions Using SAS® Hash Table Operations: A Business Intelligence Case Study.
Here are five things you (probably) don’t know about hash tables:
1. Includes many of the features of an in-memory data base
Among the core capabilities of a data base is the ability to Create, Read, Update, and Delete, quite often described using the acronym CRUD. In this respect a SAS hash table is no different: the hash object facilitates all the basic operations on it. In addition, it supports a number of useful operations: one related to the table as a whole, and the other to the individual table items. The table below shows how the operations are classified.
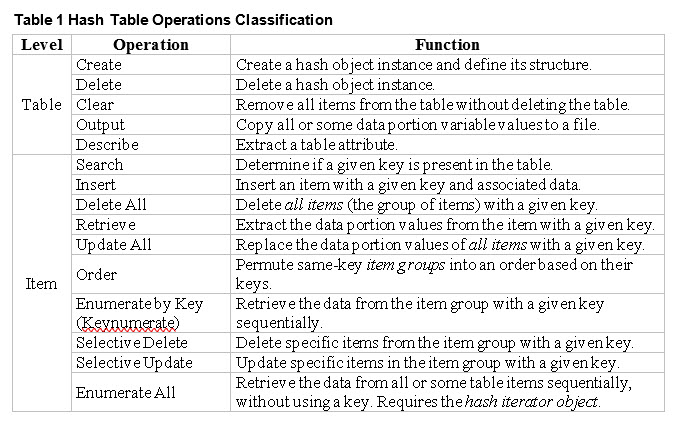
2. Can be used for data aggregation at multiple levels
SAS includes a range of facilities for data aggregation, including hash tables. Given that breadth of alternatives, it is surprising that hash tables are not used more broadly for data aggregation tasks. The SAS hash object can perform a number of data aggregation tasks, including calculating the number of distinct values in one pass of the input data where other facilities would require multiple passes/steps. It can be as simple as creating another hash object with different defined keys.
3. Easily parameterized
The SAS macro language is an obvious choice for parameterizing our programs, as is the use of data-driven techniques using parameter files. Both of these approaches are fully compatible with the use of hash tables. Hash object items can store pointers to other hash objects as data. These data values can then be used to loop through the hash objects they identify.
4. Memory constraints are not a deal breaker
One of the common concerns about the use of hash tables in SAS is that they are memory intensive. That is certainly true. What is also true is that there are any number of relatively straightforward SAS programming techniques that can be used to deal with memory management issues (e.g., too many key values to process). SAS functions (e.g., the CAT series of functions), along with MD5, can be used to partition your data into subsets that can be processed independently - either sequentially or in parallel.
5. Can often be more efficient than standard SAS approaches to data management
Efficiency is a double-edged sword, and it is also a value judgment. While our book does not specifically include many comparisons, upon running the examples yourself we suspect you will agree that the SAS hash object can be very efficient.
We hope you found these tips useful. More detail and the code can be found in our book, Data Management Solutions Using SAS® Hash Table Operations: A Business Intelligence Case Study.
Do you do anything interesting with hash tables that you would like to share?





1 Comment
Hi Don
I purchased your book, "Data Management Solutions Using SAS® Hash Table Operations: A Business Intelligence Case Study".
Do I have to sign into the SAS site to get the Bizarro Ball data, I would rather not.
Thanks in Advance