St. Louis Union Station welcomed its first passenger train on Sept. 2, 1894 at 1:45 pm and became one of the largest and busiest passenger rail terminals in the world. Back in those days, the North American railroads widely used a system called Timetable and Train Order Operation to establish schedules and run smoothly. Today we have many ways to predict, analyze and share information, making this system obsolete. But how can we effectively predict when and where passengers are going?
Yes, one of the most difficult tasks researchers have is to find which important variables really affect responses. There are many cool statistical methods available in JMP that can help with this task. Our new class, JMP Software: Finding Important Predictors, will teach you the theory behind these methods and how to apply them. (This course will be taught as training associated with the JMP Discovery Summit conference, Oct. 17-20, 2017.)
Suitable for anyone who uses statistical models to understand the factors that affect their process, this two-day course will cover techniques in JMP on the first day, and techniques in JMP Pro the second day. As with all of our courses, there are lecture sections interspersed with demonstrations and plenty of exercises for you to practice the techniques.
We’ll discuss some simple methods for determining important predictors using the Profiler and the Effect Summary report in Fit Least Squares and how to validate a model and the differences among model selection criteria. You will then learn about classic methods of variable selection: various methods using visualizations, stepwise regression, and all subsets regression. We will also use non-traditional methods to select variables, such as variable clustering, and even predictive model techniques like decision trees and partial least squares regression.
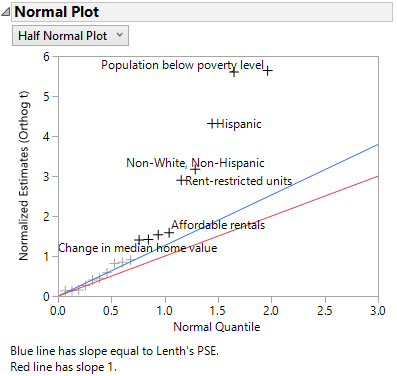
Additionally, we will cover cutting edge penalized regression for model selection, including the lasso and elastic net models. Ridge regression is discussed, but as it is not a variable selection technique, we don’t use it in the demonstrations. We will look at variations of these models, such as adaptive methods, the double lasso, and two-stage forward regression. One of the benefits of penalized regression is the ability to model non-normal data, so the final chapter of the course introduces several case studies of count data and zero-inflated data.
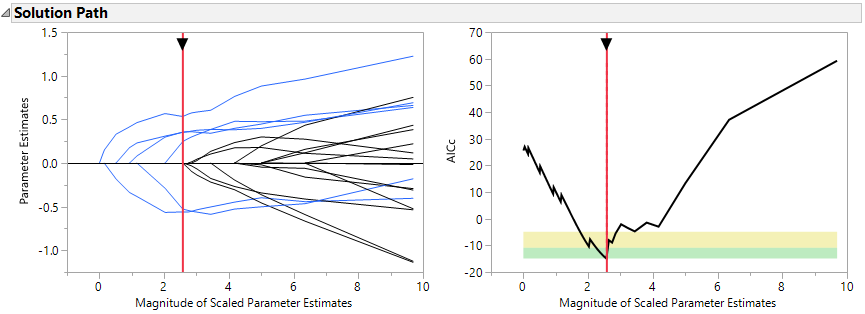
You will simulate data from designed experiments as well as examine observational data. Variable and model selection techniques for both small and large data sets are covered.
Just over 123 years later, St. Louis Union Station will welcome the first public offering of JMP® Software: Finding Important Predictors. Join me Oct 16-17 just before the JMP Discovery Summit conference rolls into the station, and be among the first to learn how to find important predictors for your process!
Conference attendees will save 25% off pre-conference training. Register today!