“Phew! That tip alone was a life saver,” said a student in one of my SAS SQL classes. “Before, I would have to read about ten Google search results before I could find that content of the sort you shared in class.”
That student was referring to the tip I shared – the compare and contrast SAS data step with PROC SQL join slides. Since this captured the attention of the entire class as well, I thought it would be helpful to share with you as well, dear reader.

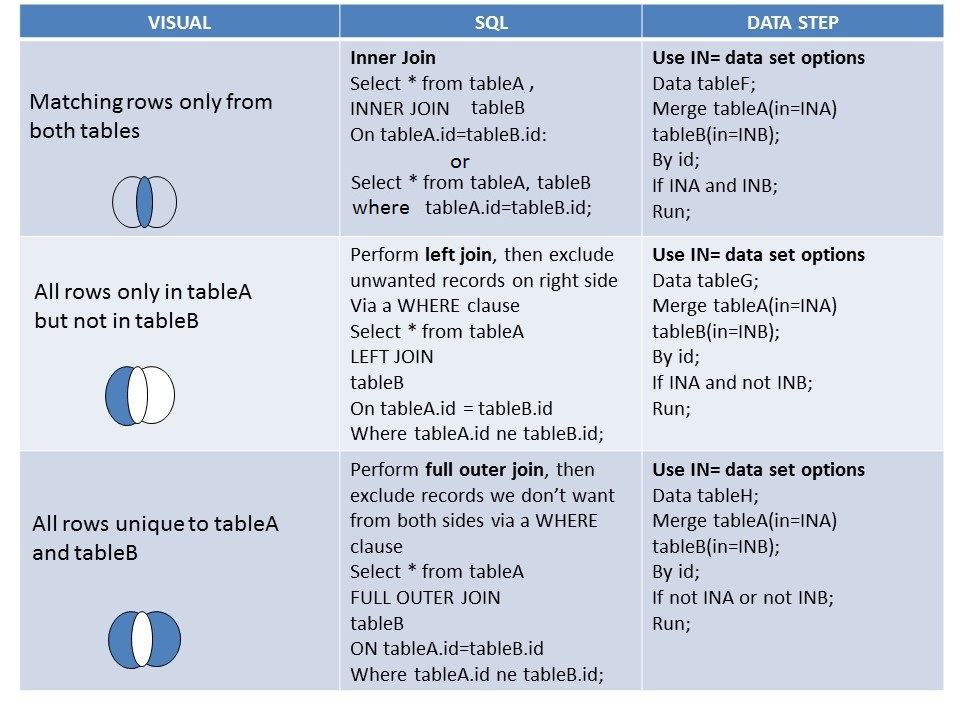
As a SAS instructor, I’m very fortunate to rub shoulders with some of the most brilliant minds in the world. You guessed right -- SAS programmers are a brilliant bunch. The sheer amount of work they do to streamline code and process so that business can become more efficient is bound to take anyone’s breath away. They need to be admired, put on a pedestal and worshiped for the value they bring businesses!
I love to see the value savvy customers get from taking a SAS training course. They poke around all kinds of resources to help manage their SAS jobs, whether online, peer-to-peer support or coming to take a class. That’s why they appreciate the top-notch content they receive in class. As instructors, it’s rewarding to see how customers benefit from our training. It’s totally worth the years of ongoing research we do. Especially breathtaking is to watch how customers light up with the knowledge that they can now apply at work.
We also have a video on this topic, check it out:
Did you find my PROC SQL join with data step comparison useful? Do you have any visuals that you go to time and again that you’d like to share? Have you taken a SAS training class yet? I’d love to hear from you, and hope to see you in class soon!




14 Comments
It's great to see the interest sparked by my comment. I especially like Chris Graffeuille's comment, "These diagrams are correct when the values of the key (ID) variables are not unique in *at most one* table." Very well stated and absolutely right. I also liked the statements by Anders Skollermo concerning many-to-one and many-to-many joins, which are also quite correct.
In my many years of working in IT, I have far too often seen SQL code that did not quite accomplish what was intended - records were unintentionally dropped due to incorrect coding of the where statement (note that the SQL where clause can be used to imply an inner join) or worse still, records were unintentionally duplicated due to improper key selection. I tend to prefer the merge construct over SQL, particularly when developing complex joins involving multiple tables with complex rules for inclusion/exclusion in the resultant file, simply for the reason that it is possible to consider all records and output the "exclusions" to a separate file such that they may be reviewed. I have received comments from some that such techniques are inefficient compared to SQL processing, however this is very rarely the case when all factors are considered.
That is not to say I don't use SQL. I have used it quite extensively as well. The moral here I suppose is that you must understand your data such that the result is what is expected!
Concerning the comment by Aaron Dukes, which is a many-to-many join situation in SQL, what the merge construct does is a one-to-one join for each of the observations in the table having the "least" number of observations, and using the last observation in that table to join with the remaining unmatched observations in the other table. For example, if table A contains 3 observations and table B contains 5 observations, then obs 1 of table A is joined with obs 1 of table B, obs 2 of A with obs 2 of B, obs 3 of A with obs 3 of B, obs 3 of A with obs 4 of B, and obs 3 of A with obs 5 of B. It does not matter which table has the least number of observations. A one-to-one join is done on the first two observations, while a one to many is done on the last three observations in this case.
Happy SAS programming, one and all!
Hi love this page on joins. So nicely explained for those of us who are learning. II have been trying to do a full outer join but rows on the right table are coming out as null. I will try the proc sql statement with the where statement records in a not equal to b.
Many-to-Many: SQL produces cartesian joins, whereas the result from merge is not intuitive. Example:
data a;
byvar=1;
do a=1 to 5;
output;
end;
run;
data b;
byvar=1;
do b=1 to 2;
output;
end;
run;
proc sql noprint;
create table sqljoin as
select a.byvar as a_byvar, b.byvar as b_byvar, a.a, b.b
from a inner join b
on a.byvar = b.byvar
;
quit;
data merge_a_b;
merge a(in=in_a) b(in=in_b);
by byvar;
if in_a and in_b;
run;
Running this code on SAS 9.4 on my 64-bit Windows machine produces the following results:
The dataset SQLJOIN has the following 10 observations:
A B
= =
1 1
1 2
2 1
2 2
3 1
3 2
4 1
4 2
5 1
5 2
The dataset merge_a_b has the following 5 observations:
A B
= =
1 1
2 2
3 2
4 2
5 2
Due to this behavior, I try to ensure that no more than one dataset in a merge has multiple records with the same set of values for the BY variables. And since my attempts to ensure this are not always successful, I make a point of looking in my SAS Log for the following note:
"NOTE: MERGE statement has more than one data set with repeats of BY values."
I treat the appearance of such notes as a bug in my code that must be resolved.
These situations most often arise because the programmer forgot to include an additional key variable in his ON or BY list. While the SQL result makes more intuitive sense in response to the code submitted, it too would not have been what the programmer wanted - the computer is not a mind-reader.
Hoping this adds clarity.
Aaron Dukes, Principal Scientist,
IDeaS, a SAS Company
Hi! Some further comments:
If the ID is unique, then I think that SQL and Merge are of equal value.
If the ID is not unique, then You have two different situations:
many-to-one - which is handled in a good way by Merge. The IN= data set option can be used to control the behaviour further.
many-to-many - this can also be handled by Merge in a similar way.
It important to remembere that Merge with IN is only a tool to try to help the user to achieve what he/she wants. Merge and SQL are NOT the solution, they are only tools which may be useful, when used in the right way. It is up to the user to find out what is the right way.
The user MUST, at least after a while, have a god and gradually better and better knowledge and understanding of how he/she really wants the observations to be combined.
Perhaps the best solution is to restart. Add one or more variables to the ID-variable combination. Resort that tables. Check and verify in a data step that the new ID-variable combination is unique.
Then proceed as described above.
I hope that this comment has given some further insight.
/ Br Anders Sköllermo Ph.D., Actuary "Retired, but not tired!"
We can't emphasize enought Peter's point, though he is not quite right.
These diagrams are correct when the values of the key (ID) variables are not unique in *at most one* table. With 2 tables, one non-unique ID conserves the similarity to SQL.
The data step allows for fine-grained manipulation and reporting such as for eg:
- if this is the second row for the same ID, process differently and output to a different table
- process inner, outer, left, and right joins conditions at once by just testing IN variables
- report how many rows were read, added, merged, rejected etc
1) Peter Wall is QUITE right. Please note that with Merge the user can control, using the IN= data set option, how multiple sequential observations with the same BY-value shall be treated.
I do NOT know exactly what SQL will do. VERY good point!
2) Lex Jansen is correct in the sense that the SEUGI paper is available. Many Thanks for that !!
This paper was the starting point for a published paper in SAS Observations on line. I worked on this paper together with SAS Institute (and got 150 dollars - "about one dollar per hour").
I think that the Observations paper is better.
Moreover, I later found out that there is a (small) error in both versions. So the (hopefully) correct version is available from me.
This also shows the great difficulties is getting everything EXACTLY correct.
The paper Anders mentioned is still available:
http://www.sascommunity.org/seugi/SEUGI1995/The%20Importance%20of%20IN.pdf
(go to: http://www.lexjansen.com/cgi-bin/saspapers_query.php and search for "Skollermo"
A caveat should be provided: these demonstrations depend upon the values of the key (ID) variables being unique in both tables!
Hi! I agree with Charu. Both SQL and Merge have their plus and minus. My suggestion:
* If your problem is solved in a complete way by SQL, then you can use it.
* As an alternative - If your problem is solved in a complete way by Merge as descibed above then you can use that instead.
Please note that SQL views and Data step views can be used to give the variables the names that you like, and also put them in the wanted order. The computation cost of using a view is very small, also for large sets of data.
If you have more difficult problems in combining two tables, I suggest that you use Merge with the IN= data set option.
I wrote a paper documenting the IN= option many years ago together with SAS Institute: "The Importance of the IN= Data Set Option in Merging Data Sets".
I am planning to write a new paper, describing Very complex combinations of SAS tables. Please send me an email to anders.skollermo@one.se, if you have any such problem.
Very useful. Thanks for sharing.
Yes, very useful steps.
Which one is more efficient(SQL Join or MERGE)?
In Backend how its work?
Hi Srinivas, thanks for your comment. Both have different advantages. I like SQL joins as PROC SQL affords more flexibility with column names.. etc. I like Data step merges for the extensive data step manipulation that only the data step offers, things like hash objects, arrays etc. are all possible within the datastep. Ultimately efficiency is a it-depends question. Benchmarking both techniques in your unique environment is the only way to determine which one is more efficient for your needs. There isn't a one size fits all when it comes to prescribing the best SAS technique. hope this helps.
Srinivas, MERGE is more efficient, but you should be careful. Here is some tips to avoid the potent risks
Tips to avoid the potential risks when using DATA STEP MERGE?
1), before merging, standardize their sort keys with same lengths or formats
As a SAS developer, we must often see the following words:
WARNING: Multiple lengths were specified for the BY variable Name by input data sets. This might cause unexpected results.
How to handle multiple lengths is very important now.
Way1, it is very popularly suggested online and papers by many SAS programmers. But it has potential risks. For example, if we use PROC IMPORT to read in xlsx or csv files, we cannot simply use length statement such as length Name $ 11. Gender $ 6.; to change these sorted keys’ lengths. This way causes potent truncations. I have not test other data types. So my suggestion is that we’d better not use this way to merge .sas7bdat data files.
%let path = /sas/model/model_dev/enterprise_reports/models/aggregation_sas/test_merge;
proc import out=boy_class_xlsx datafile="&path./boy_class.xlsx" dbms=xlsx replace;
getnames=YES; /*here the length of Name is $ 10. , Gender is $ 4. */
run;
/*bad codes to cause truncations*/
data boy_class_xlsx_relength;
length Name $ 11. Gender $ 6.; /*reset the length of the sorted keys here*/
set boy_class_xlsx;
run;
proc sort data=boy_class_xlsx_relength out=boy_class_xlsx_relength_srt; by Name; run;
proc sort data=kids_class out=kids_class_srt; by Name; run;
data merged_class_xlsx_relength;
/*length Name $ 11. Gender $ 6.; */ /* or reset the length of the sorted keys here*/
merge boy_class_xlsx_relength_srt(in=a) kids_class_srt(in=b);
by Name;
if a^=1 and b=1;
run;
Way2, using format to standardize the sorted keys’ lengths or formats
At this moment, format statement with format Name $ 11. Gender $ 6.; is the best way to fix the problem of multiple lengths and avoid truncations.
/*good codes using format method*/
data boy_class_xlsx_format;
format Name $ 11. Gender $ 6.; /*reformat the sorted keys here*/
set boy_class_xlsx;
run;
proc sort data=boy_class_xlsx_format out=boy_class_xlsx_format_srt; by Name; run;
proc sort data=kids_class out=kids_class_srt; by Name; run;
data merged_class_xlsx_format; format Name $ 11. Gender $ 6.;
/*format Name $ 11. Gender $ 6.; */ /* or reformat the sorted keys here*/
merge boy_class_xlsx_format_srt(in=a) kids_class_srt(in=b);
by Name;
if a^=1 and b=1;
run;
Way3, create new variables using old sorted keys, then drop the sorted keys, rename these new variables as the names of sorted keys.
To create new variables with standard lengths from old sorted keys is a good way to standardize multiple lengths and avoid truncations.
/*good codes using new variables creation method*/
data boy_class_xlsx_revar(rename=(Name_new=Name Gender_new=Gender));
set boy_class_xlsx;
length Name_new $ 11. Gender_new $ 6.;
Name_new = left(strip(Name));
Gender_new = strip(Gender);
drop Name Gender;
run;
proc sort data=boy_class_xlsx_revar out=boy_class_xlsx_revar_srt; by Name; run;
proc sort data=kids_class out=kids_class_srt; by Name; run;
data merged_class_xlsx_revar;
merge boy_class_xlsx_revar_srt(in=a) kids_class_srt(in=b);
by Name;
if a^=1 and b=1;
run;
Compared with the above three methods, format is the simplest one; New variables creation is a good choice; and resetting the lengths using length statement is not recommended.