SAS Viyaがリニューアルされまして、ついにディープラーニングが登場しました!
SAS ViyaのディープラーニングではオーソドックスなDeep Neural Network(DNN)から、画像認識で使われるConvolutional Neural Network(CNN、畳込みニューラルネットワーク)、連続値や自然言語処理で使われるRecurrent Neural Network(RNN、再帰的ニューラルネットワーク)まで利用可能になります。
ディープラーニングを使うことのメリットは、従来の機械学習やニューラルネットワークが苦手としている画像や文章を認識し、高い精度で分類や推論することが可能になります。
高い精度というのは、ディープラーニングのモデルによっては人間の目よりも正確に画像を分類することができるということです。
例えばコモンドールという犬種がありますが、この犬はモップのような毛並みをしていて、人間ではモップと見間違えることがあります。
これは犬? それともモップ?

こういう人間だと見分けにくい画像に対しても、ディープラーニングであれば、人間よりも正確に犬かモップかを見分けることができるようになります。
というわけで、今回はSAS Viyaのディープラーニングを使って画像分類をしてみたいと思います。
ディープラーニングの仕組み
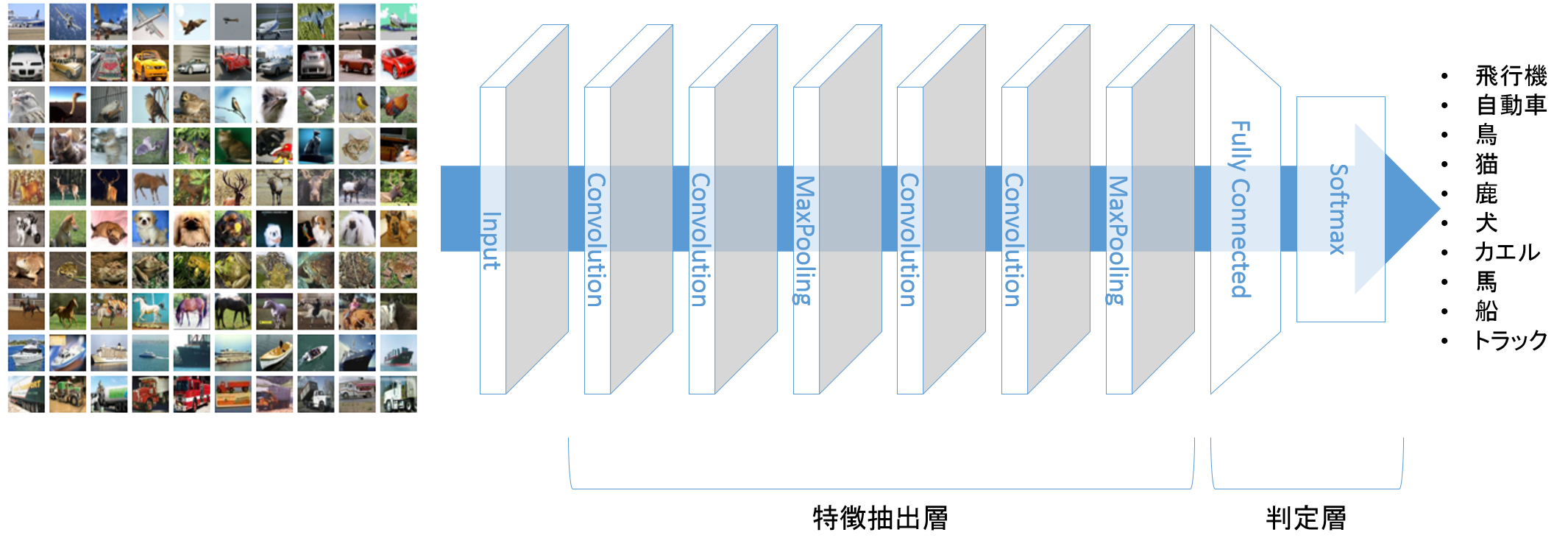
画像分類のディープラーニングではCNNを使います。
CNNは画像の特徴を探し出す特徴抽出層と特徴から画像を分類する判定層で構成されています。
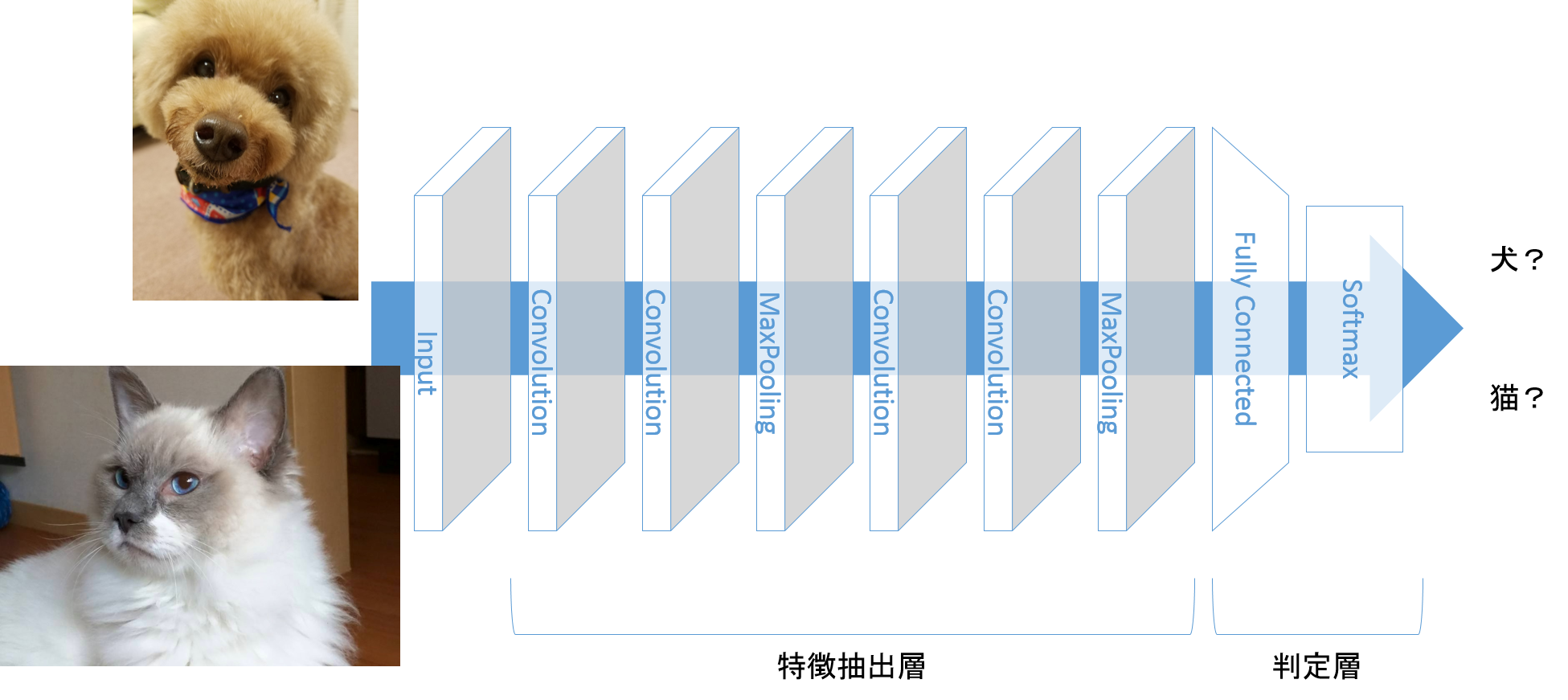
特徴抽出層は主に畳込み層とプーリング層で構成されています。
畳込み層で入力画像に対し、ピクセルの特徴(横線の有無とか斜め線とか)を探し出し、プーリング層で重要なピクセルを残す、という役割分担です。
判定層は、特徴抽出層が見つけた特徴をもとに、画像の種類を分類します。
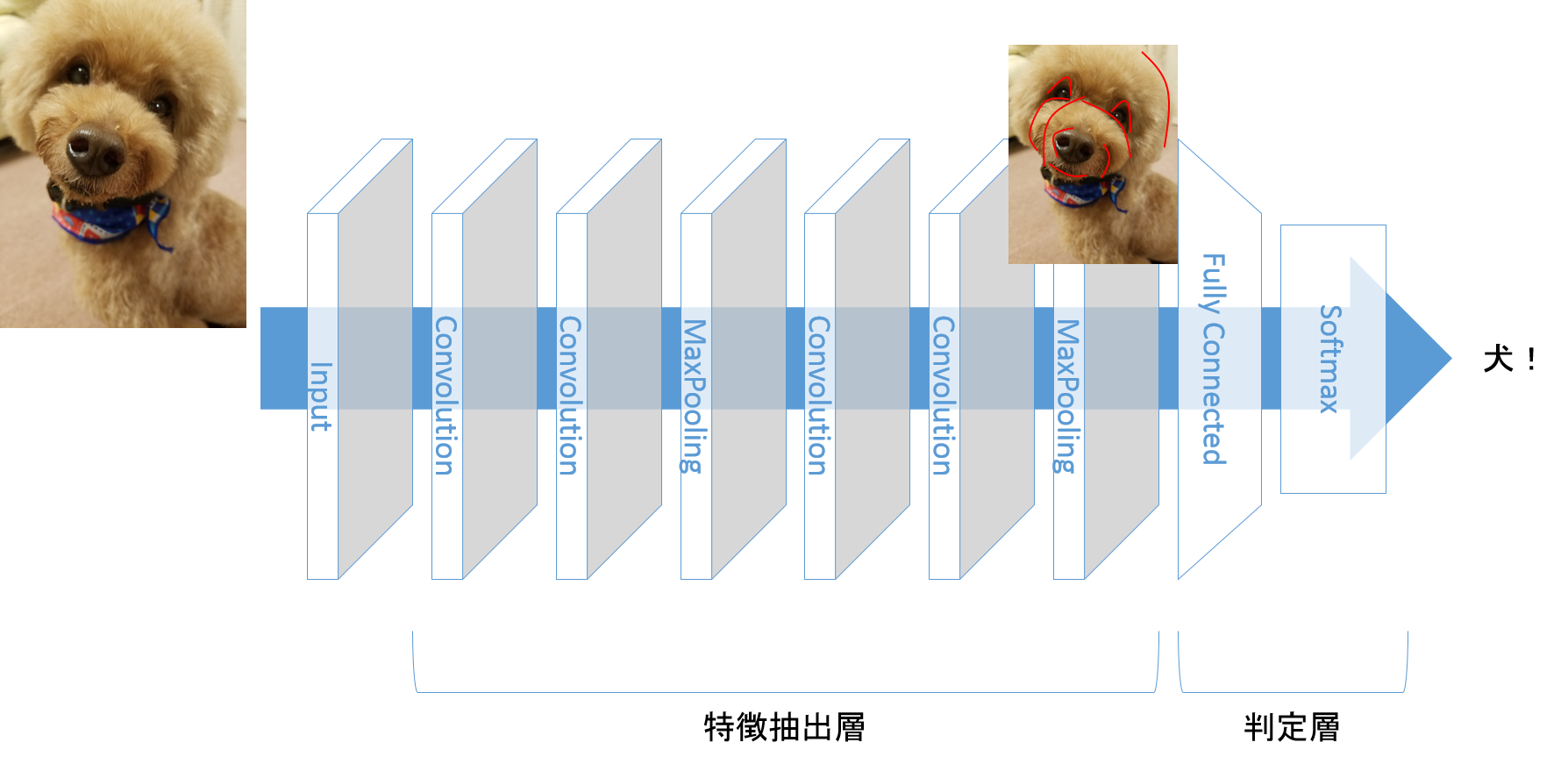
例えば犬と猫の分類であれば、特徴抽出層が入力画像から、面長で大きな鼻の特徴を見つけだし、犬と分類します。
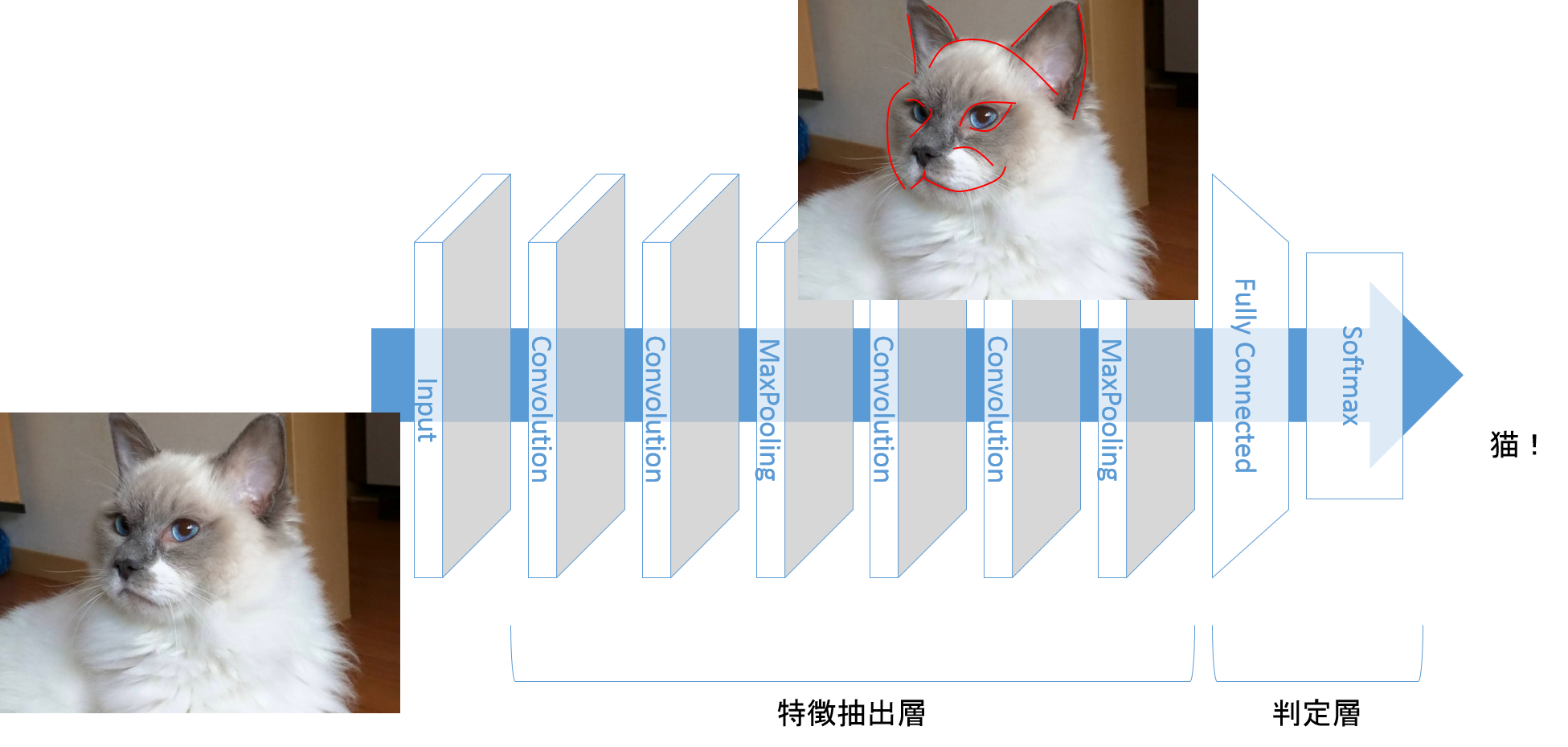
または、丸っこい顔立ちと立った耳の特徴を見つけだし、猫と分類します。
SAS Viyaで画像を扱う
SAS ViyaディープラーニングでCifar10をネタに画像分類をしてみたいと思います。
Cifar10は無償で公開されている画像分類のデータセットで、10種類の色付き画像60,000枚で構成されています。
各画像サイズは32×32で、色はRGBです。
10種類というのは飛行機(airplane)、自動車(automobile)、鳥(bird)、猫(cat)、鹿(deer)、犬(dog)、蛙(frog)、馬(horse)、船(ship)、トラック(truck)で、それぞれ6,000枚ずつ用意されています。
画像は総数60,000枚のうち、50,000枚がトレーニング用、10,000枚がテスト用です。

画像データは以下から入手することができます。
https://www.cs.toronto.edu/~kriz/cifar.html
さて、Cifar10を使って画像分類をしてみます。言語はPython3を使います。
SAS Viyaで画像分類をする場合、まずは入手したデータをCASにアップロードする必要があります。
CASはCloud Analytics Servicesの略称で、インメモリの分散分析基盤であり、SAS Viyaの脳みそにあたる部分です。
SAS Viyaの分析は、ディープラーニング含めてすべてCASで処理されます。
CASではImage型のデータを扱うことができます。
Image型とは読んで字のごとくで、画像を画像フォーマットそのままのバイナリで扱えるということです。
プログラムで画像を扱うために、ピクセル単位の配列に変換する必要はありません。
CASでは画像を画像そのままに使うことができます。
トレーニングデータと検証データ、テストデータをCASにアップロードしました。
アップロードしたデータを以下のように表示することができます。
元画像が32×32なため、あまり解像度が良いとは言えませんが、人間の目でも飛行機や自動車と判別することができると思います。
SAS Viyaディープラーニングで画像分類
ディープラーニングをプログラミングするときは、ニューラルネットワークの層(レイヤー)を1層1層定義していきます。
今回はCNNで画像分類を行うので、入力層、畳込み層、プーリング層、全結合像、ソフトマックス層を定義します。
CNNの構造としては、わかりやすくVGGの簡易版を作ります。
VGGは2014年に登場したCNNの一種で、ImageNet ILSVRC2014で1位を獲得したものです。
https://arxiv.org/abs/1409.1556
VGGは16層版と19層版があるのですが、簡易的に9層に短縮したものを以下に示します。
conn.loadactionset("deepLearn") mname="cifar10" mweights="cifarweights" bweights="bestweights" conn.deepLearn.buildModel(modelTable={"name":mname,"replace":True}, type="CNN") conn.deepLearn.addLayer(model=mname, name="input1", layer=dict(type="input",nchannels=3, width=32, height=32), replace=True) conn.deepLearn.addLayer(model=mname, name="conv1", layer=dict(type="convolution", act="relu", width=3, height=3, stride=1, nFilters=32), srcLayers=["input1"], replace=True) conn.deepLearn.addLayer(model=mname, name="conv2", layer=dict(type="convolution", act="relu", width=3, height=3, stride=1, nFilters=32), srcLayers=["conv1"], replace=True) conn.deepLearn.addLayer(model=mname, name="pool1", layer=dict(type="pooling", width=2, height=2, pool="max", stride=2, dropout=0.25), srcLayers=["conv2"], replace=True) conn.deepLearn.addLayer(model=mname, name="conv3", layer=dict(type="convolution", act="relu", width=3, height=3, stride=1, nFilters=64), srcLayers=["pool1"], replace=True) conn.deepLearn.addLayer(model=mname, name="conv4", layer=dict(type="convolution", act="relu", width=3, height=3, stride=1, nFilters=64), srcLayers=["conv3"], replace=True) conn.deepLearn.addLayer(model=mname, name="pool2", layer=dict(type="pooling", width=2, height=2, pool="max", stride=2, dropout=0.25), srcLayers=["conv4"], replace=True) conn.deepLearn.addLayer(model=mname, name="fc1", layer=dict(type="fullconnect",n=512, act="relu", dropout=0.5), srcLayers=["pool2"], replace=True) conn.deepLearn.addLayer(model=mname, name="output", layer=dict(type="output",act="softmax", n=10), srcLayers=["fc1"], replace=True) |
SAS Viyaディープラーニングでは上記のように、1層1層を定義していきます。
各層の役割やパラメータを`layer=dict(type="convolution", act="relu", width=3, height=3, stride=1, nFilters=64)`のように定義する記法になっています。
各層の入力元の層は`srcLayers=["input1"]`のように書きます。
どの層がどういう役割で、ニューラルネットワーク全体としてどうつながっているのか、わかりやすい書き方になっていると思います。
これでニューラルネットワークの各層を定義できました。
最後に最適化関数を定義します。
nloOpts= dict(miniBatchSize=32, maxEpochs=100, algorithm=dict(method='adam', learningRate=0.001, beta1=0.9, beta2=0.999), logLevel=2, stagnation=2, seed=13456) |
ここでミニバッチサイズやエポック数を書きます。
また、stagnationやlogLevelも定義可能です。
stagnationは所謂early stoppingで、ニューラルネットワークの改善が進まなくなったらエポックが終了しないうちに学習を終了するというものです。
これを設定することで、学習が進まないニューラルネットワークを早めに終了させ、見切りを付けることができます。
また、トレーニングデータのみ改善が進んで検証データの改善が進まないような過学習の防止にもなります。
学習と評価
ここまででCNNの定義ができました。
さっそく学習してみましょう。
cnn = conn.deepLearn.dltrain(model=mname, table={"name":"shfcifar10train"}, validTable={"name":"cifar10valid"}, inputs = '_image_', target='_label_', modelWeights=dict(name=mweights, replace=True), bestWeights=dict(name=bweights, replace=True), optimizer=nloOpts, gpu=dict(devices=[0,1,2]), nThreads=3 ) |
SAS ViyaのCNNではGPUでの演算をサポートしています。
Nvidia社のGPUにCUDAを使って、ディープラーニングの計算を実行させるということが可能です。
GPUはCPUと違い、単純な計算をたくさん高速に実行することが可能なアーキテクチャをしています。
ディープラーニングのような、膨大な数の掛け算と足し算で構成されている演算であれば、GPUのほうがCPUよりも断然はやく計算することが可能です。
今回はNvidia Tesla P100のGPUが3台登載されたサーバを使いますので、GPU3台で分散してディープラーニングの学習を実行します。
1エポックで50,000枚の画像を処理するのですが、それが4秒強で済むくらい、すごく速く計算できています。
お茶を飲みながら学習完了を待ちまして・・・・・・学習曲線は以下のようになりました。
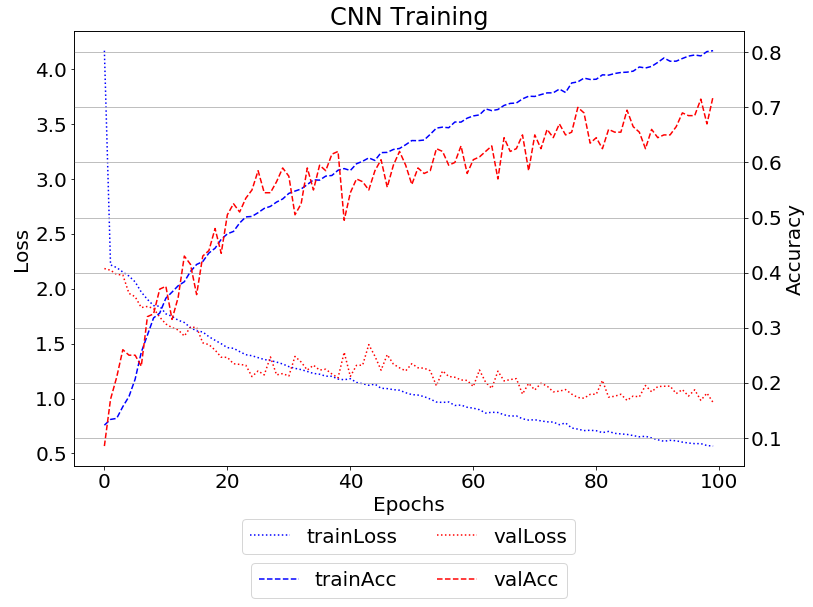
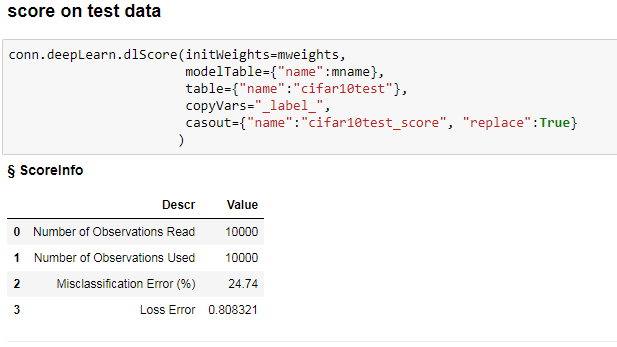
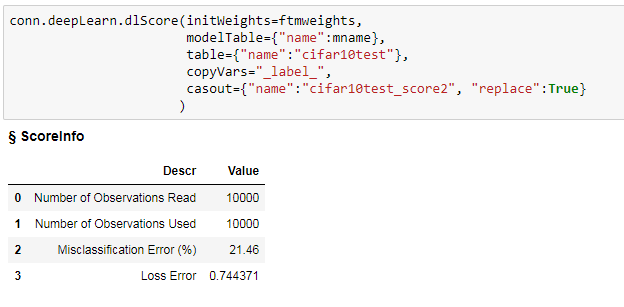
作ったモデルをテストデータ10,000枚を使って評価してみます。
誤分類率が24.74%でした。
画像を水増しして再学習
作ったモデルを改良し、精度を向上させたいと思います。
ディープラーニングの精度を向上させる方法はいくつかありますが、今回は画像を水増しして再学習します。
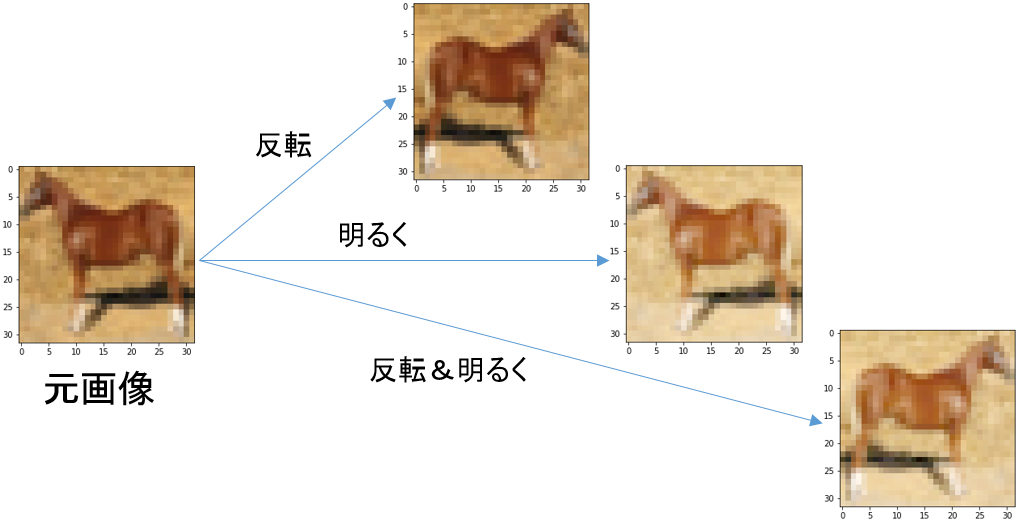
画像を水増しするとは、すでにトレーニングに使った画像を反転させたり明度を変えたりして、バリエーションを増やすことです。
バリエーションを増やすことで、同じ画像でも見た目が変わり、ディープラーニングが学習できる画像の幅が広がります。
人間もたくさんの絵画を見たほうが目が肥えるのと同じように、ディープラーニングもより多くの画像を学習したほうが精度が向上します。
今回はトレーニングデータについて、画像の左右反転と色を明るくしたもの、そしてその組み合わせを生成しました。
つまり、画像数は4倍に水増しされています。
通常画像、左右反転画像、明るい画像、左右反転&明るい画像
SAS Viyaでは画像処理の機能を用意しており、こういう画像を変更することも得意としています。
既に水増し前の画像でトレーニングしたCNNのモデルを使い、水増しした画像を用いて再学習します。
トレーニング用の画像数は50,000×4=200,000枚になっています。
以前の学習よりも時間がかかりますが、気長に待ちましょう。
20エポックで学習しました。以下のとおり、当初のモデルよりも精度が向上していることがわかります。
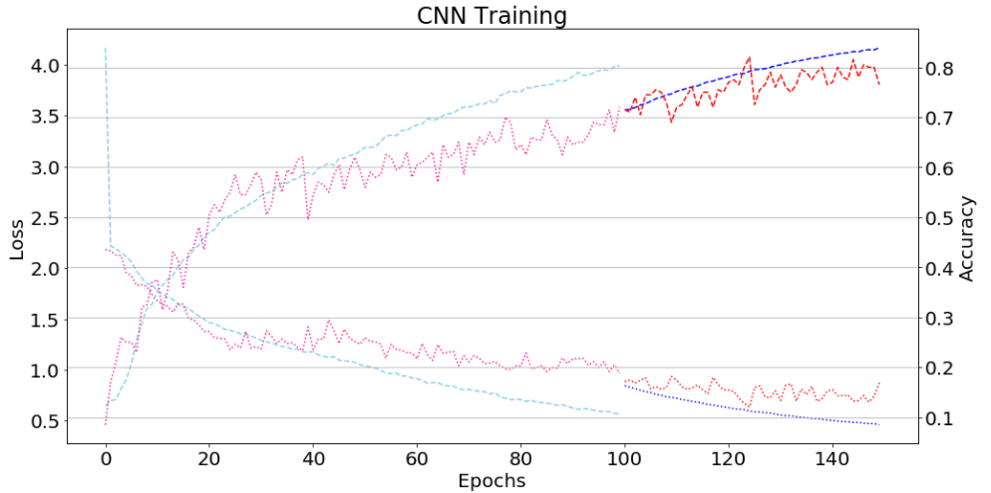
最初の学習と水増し画像による学習の学習曲線は以下のようになっています。
水増し画像による学習では、学習済みのモデルを使うことができたので、最初から高い精度で学習し洗練させることができました。
テストデータでの誤分類率も21.46%程度にまで減少しています。
最後に
こちら(viyaCNN_3.3.zip)にすべてのコードを記述したJupyter Notebookがありますので、ご活用ください。
SAS Viyaのディープラーニングをもちいて画像分類をしてみました。
Cifar10という既存の画像データを使いましたが、同様の方法で実ビジネスで使われる画像を使って画像分類のモデルを作ることも可能です。
分類したい画像が足りなくてディープラーニングの精度を向上できていない場合も、今回紹介したように画像を水増しすることで改善させることもできます。
これらをすべてをSAS Viyaのライブラリで用意し、同じ基盤、同じインターフェイスで実行し管理することが可能になっています。
トライアルも提供していますので、ぜひ一度お試しください!!
https://www.sas.com/ja_jp/insights/articles/analytics/viya.html
(おまけ)ユーザの声
「複雑なディープラーニングのモデルの実装が簡単なコードで書けて、パッと見てわかりやすいです。」(東北地方在住)
