
Most of us have experienced the annoyance of finding an important email in the spam folder of our inbox.
If you check the spam folder regularly, you might get annoyed by the incorrect filtering, but at least you’ve probably avoided significant harm. But if you didn’t know to check spam, you may have missed important information. Maybe it was that meeting invite from your manager, a job offer or even a legal notice. In these cases, the error would have caused more than frustration. In our digital society, we expect our emails to operate reliably.

Similarly, we trust our cars to operate reliably – whether we drive an autonomous or traditional vehicle. We would be horrified if our cars randomly turned off while driving 80 miles an hour on a freeway. An error in the system of that proportion would likely cause significant harm to the driver, passenger and other drivers on the road.
These examples relate to the concept of robustness in technology. Just as we expect our emails to operate accurately and our cars to drive reliably, we expect our AI models to operate reliably and safely. An AI system that changes outputs depending on the day and the phase of the moon is useless to most organizations. And if issues occur, we need to have mechanisms that help us assess and manage potential risks. Below, we describe a few strategies for organizations to make sure their AI models are robust.
The importance of human oversight and monitoring
Organizations should consider employing a human-in-the-loop approach to create a solid foundation for robust AI systems. This approach involves humans actively participating in developing and monitoring model effectiveness and accuracy. In simpler terms, data scientists use special tools to combine their knowledge with technological capabilities. Also, workflow management tools can help organizations establish automated guardrails when creating AI models. The workflows are crucial in ensuring that the right subject matter experts are involved in creating the model.
Once the AI model is created and deployed, continuous monitoring of its performance becomes important. Monitoring involves regularly collecting data on the model's performance based on its intended goals. Monitoring checkpoints are vital to flag errors or unexpected outcomes before deviations in performance occur. If deviations do occur, data scientists within the organization can assess what changes need to be made – whether retraining the model or discontinuing its use.
Workflow management can also ensure that all future changes are made with consultation or approval from the subject matter experts. This human oversight adds an extra layer of reliability to the process. Additionally, workflow management can support future auditing needs by tracking comments and history of changes.
Validating and auditing against a range of inputs
Robust data systems are tested against diverse inputs and real-world scenarios to ensure they can accommodate change while avoiding model decay or drift. Testing reduces unforeseen harm, ensures consistency of performance, and helps produce accurate results.
One of the ways users can test their model is by creating multiple model pipelines. Model pipelines allow users to run the model under different ranges of inputs and compare the performances under differing conditions. The comparison enables the users to select the most effective model, often called the champion model.
Once the champion model has been selected, organizations can regularly validate the model to identify when the model begins drifting from the ideal state. Organizations actively observe shifts in input variable distributions (data drift) and output variable distributions (concept drift) to prevent model drift. This approach is fortified by creating performance reports that help deployed models remain accurate and relevant over time.
Using fail safes for out-of-bound unexpected behaviors
If conditions do not support accurate and consistent output, robust systems have built-in safeguards to minimize the harm. Alerts can be put in place to monitor model performance and indicate model decay. For instance, organizations can define KPI value sets for each model during deployment – such as an expected rate for misclassification. If the model misclassification rate eventually falls outside the KPI value set, it notifies the user that an intervention is needed.
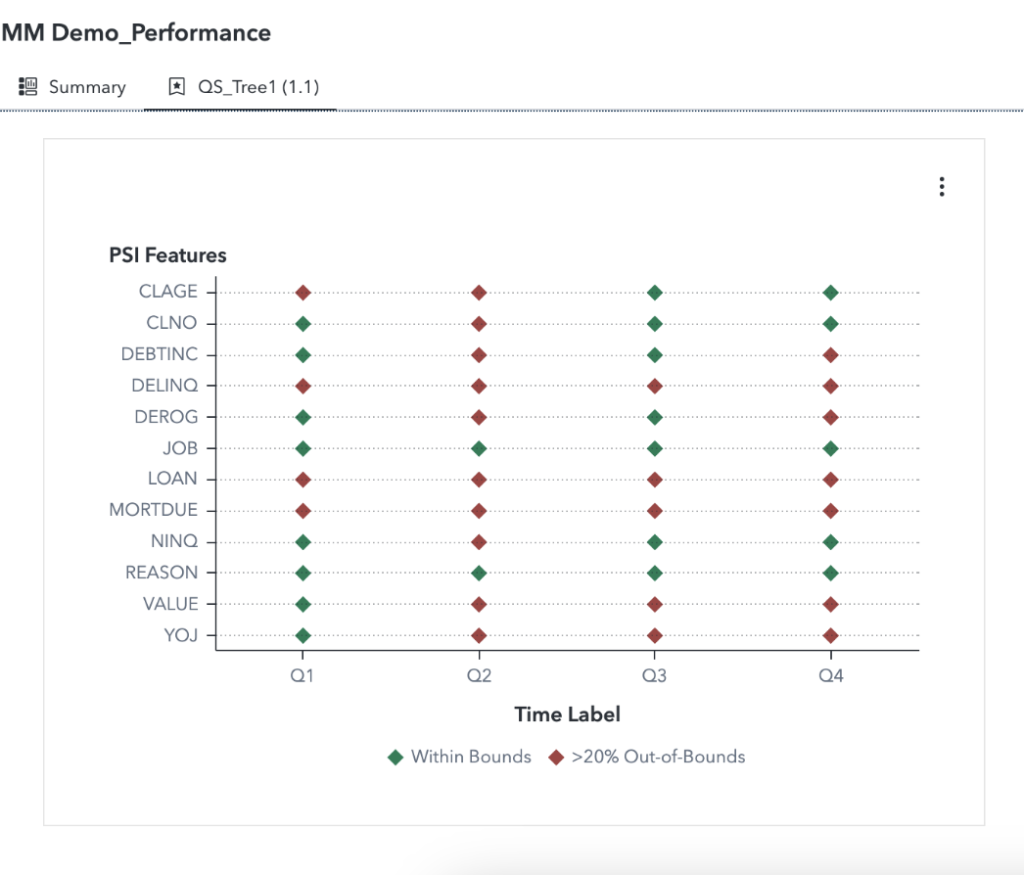
Alerts can also help indicate when a model is experiencing adversarial attacks, a common concern around model robustness. Adversarial attacks are designed to fool AI systems by making small, imperceptible input changes. One way to mitigate the impact of these attacks is by adversarial training, which involves training the AI system on misleading inputs or inputs intentionally modified to fool the system. This intentional training helps the system learn to identify and resist adversarial attacks, building system robustness.
Adaptable AI systems for real-world demands
Systems that only function under ideal conditions are not useful for some organizations that need AI models that can scale with and adapt to changes. A system's robustness depends on an organization’s ability to validate and audit the outcomes on various inputs, fail safe for any unexpected behaviors and human-in-the-loop design. By taking these steps, we can ensure that our data-driven systems operate reliably and safely and minimize potential risks, thus reducing the potential of hazards such as vehicular glitches or essential emails being misclassified as spam.
Check out this ebook and get steps to a comprehensive approach to trustworthy AI governance.
Kristi Boyd and Vrushali Sawant contributed to this article
