You’ve likely heard the news that the Google DeepMind “AlphaGo” computer not only beat a human expert at the game of Go, defeating the European Go champion, Fan Hui in five straight games, but also beat the reigning world champion grandmaster, South Korea’s Lee Sedol, 4 games to 1.
Go is considered to be a significantly more difficult game for a computer to tackle than chess, if only because of the vastly greater number of possible moves over a much larger playing field. Chess has on the order of 1040 possible legal and realistic positions in a 40-move game; Go can have up to 10360, give or take a few tens of orders of magnitude (as a point of reference, there are approximately 1080 particles in the visible universe).
When Deep Blue beat world chess champion Gary Kasparov back in 1997, it did it with a brute force approach – a massively parallel computer that would typically search to a depth of between six and eight moves, and up to a maximum of about twenty moves in some situations. It was an Expert System (not AI), with separate programing modules/libraries for openings, end games, and middle game strategy and tactic evaluation. All the legal moves and rules had to be programmed into it, and it could not learn as it went (although its programmers made adjustments after each game).
AlphaGo, however, is a true AI machine, much like the one I highlighted a couple of weeks ago that taught itself how to play Atari Breakout like a pro in just a couple of hours with minimal initial input. Unlike Deep Blue’s brute force computational approach, AlphaGo essentially uses a variation of decision trees (tree search) and machine learning deployed in a deep neural network architecture.
So what’s a neural network?
Don’t let the terminology scare you - it’s really not as conceptually complex as it may sound.
The fundamental neural network structure, such as that currently utilized by SAS® Enterprise Miner, employs three layers, as illustrated: an Input layer, and Output or Target layer, and in between, what is commonly referred to as the Hidden layer.
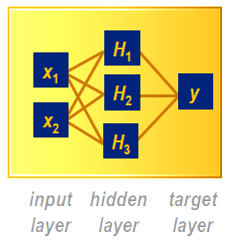 The input layer (X1, X2) consists of those typical independent variables you’d use in any decision process – all the factors that influence the outcome, such as demographic, transactional, experimental, social, operational or financial data. The output/target layer we’ll consider here (Y) is just a binary yes/no decision, a simple one or zero – is this a case of fraud or not, should we target this customer with a coupon or not, should I sell this stock at that price or hold?
The input layer (X1, X2) consists of those typical independent variables you’d use in any decision process – all the factors that influence the outcome, such as demographic, transactional, experimental, social, operational or financial data. The output/target layer we’ll consider here (Y) is just a binary yes/no decision, a simple one or zero – is this a case of fraud or not, should we target this customer with a coupon or not, should I sell this stock at that price or hold?
So what’s going on in that hidden layer? Math. Just math. Some pretty funky math, but just math all the same. The default function for neural networks in SAS Enterprise Miner is three nodes/units (out of a range from 1 to 64) of the hyperbolic tangent function, TANH for short, starting with random coefficients (weights) for each unit, which get tweaked as the system “learns” to make better decisions from the training data (H1, H2, H3).
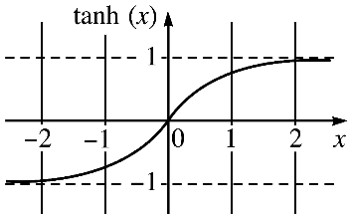 Why TANH? First, because it’s nonlinear. It can model more complex behavior patterns than a simpler linear function, where the output is always directly proportional to the input. And face it, the world is largely nonlinear – especially the people that tend to make up the all-important customer segment. Secondly, it produces a largely binary output – it’s an S-curve bounded by +1 and -1 on the vertical axis, which can easily be transformed into ones and zeros which become yes/no, go/no-go decisions.
Why TANH? First, because it’s nonlinear. It can model more complex behavior patterns than a simpler linear function, where the output is always directly proportional to the input. And face it, the world is largely nonlinear – especially the people that tend to make up the all-important customer segment. Secondly, it produces a largely binary output – it’s an S-curve bounded by +1 and -1 on the vertical axis, which can easily be transformed into ones and zeros which become yes/no, go/no-go decisions.
If the behavior you’re investigating isn’t necessarily binary, other options await you (or your data scientist), such as the SINE function for periodic behaviors, or the EXPONENTIAL function when the behaviors are unbounded.
That’s it folks, mystery solved - behind the “hidden” layer is just a nonlinear math function. Don’t be too disappointed, though – there is substantial complexity in the surrounding programming that iterates and trains the hidden layer to make not only better decisions than it made on its first iteration, but better decisions than other, simpler linear techniques.
Next question: If that’s a neural network, then what’s a “deep” neural network (the kind used by AlphaGo)?
More hidden layers. Again, that’s it. One input layer, one output layer, with multiple hidden layers in between.
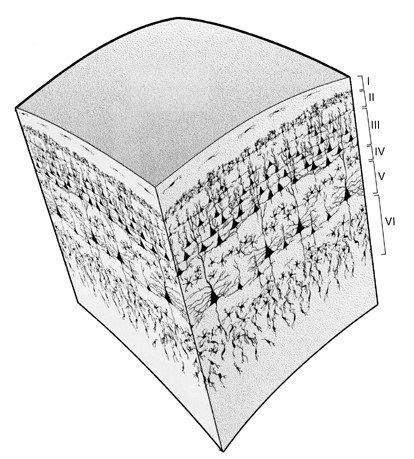 A prime example of multiple hidden layers would be the mammalian neocortex of the brain – comprised of six layers in total, essentially an input and an output layer with four hidden layers sandwiched in the middle. The processing is done from top to bottom, through the layers. That’s why the intricately folded nature of the primate neocortex is such a big deal – mental processing power is a function of the available surface area of the layers, not their volume. Rodents and other similar mammals have a smooth cortex, limiting the processing power to the surface area inside the skull; the folding found in primates fits many more times as much surface area into the same skull size. The mystery of the brain is that we don't know what "functions" it's using within its hidden layers (although I think we can safely rule out TANH).
A prime example of multiple hidden layers would be the mammalian neocortex of the brain – comprised of six layers in total, essentially an input and an output layer with four hidden layers sandwiched in the middle. The processing is done from top to bottom, through the layers. That’s why the intricately folded nature of the primate neocortex is such a big deal – mental processing power is a function of the available surface area of the layers, not their volume. Rodents and other similar mammals have a smooth cortex, limiting the processing power to the surface area inside the skull; the folding found in primates fits many more times as much surface area into the same skull size. The mystery of the brain is that we don't know what "functions" it's using within its hidden layers (although I think we can safely rule out TANH).
 How these extra layers help can best be explained with this illustration of how stereo vision might work. From one perspective all you see is a circle, from which you might derive the 3D object ‘sphere’. From the other perspective you perceive a square, from which you might deduce a cube. That’s about the best you can do with just one layer, resulting in an indeterminate output: we’re not sure what this thing is. But with the additional of one more layer that combines both the sphere and the cube, the output “cylinder” becomes a no brainer.
How these extra layers help can best be explained with this illustration of how stereo vision might work. From one perspective all you see is a circle, from which you might derive the 3D object ‘sphere’. From the other perspective you perceive a square, from which you might deduce a cube. That’s about the best you can do with just one layer, resulting in an indeterminate output: we’re not sure what this thing is. But with the additional of one more layer that combines both the sphere and the cube, the output “cylinder” becomes a no brainer.
To sum up, the "network" part of "neural network" obviously comes from arrangement depicted in the diagram at the top. The "neural" part represents the parallel to how neurons fire in the brain: it may take just one strong input in order for the neuron/hidden unit to reach its "firing" threshold, or it might require a combination of three or more simultaneous inputs to achieve that same threshold depending on the values of the coefficients/weights, which have been adjusted during the training period, just as the neurons in the brain "learn" a task or a concept via repetitive real life experiences. If you want more detail about the workings of this hidden layer, see this post from my colleague George Fernandez: "The black box of Neural Net model weights".
Here are just a few of the fields where neural networks are being applied to improve the decision process:
- Credit card and Medicare fraud detection
- The Traveling Salesman Problem – optimization of logistics / transportation networks
- Character and voice recognition; natural language processing
- Medical / disease diagnosis
- Targeted marketing
- Stock price, currency, options, futures, bankruptcy, bond rating prediction
- Robotic control systems
- Electrical load and energy demand forecasting
- Process and quality control
- Chemical compound identification
- Ecosystem evaluation
Can it really be that simple? It’s just ones and zeroes. Nothing more complex than your brain neurons either firing or not firing. And there’s nothing complex about the human brain is there? Piece of cake, right? So I confess: Yes, it is complex – the whole system that is, taking into account its recursive feedback and machine learning mechanisms. But the hidden layer (in this example) is just a math function that puts out a one or a zero depending on the nature and strength of its inputs. Put enough of those together along with a little training and you’ve got a neural network that can augment and improve many decision processes. Put enough together along with 600 million years of evolution, and you get a blogger who wonders about such things.

1 Comment
Some readers might wonder where that hyberbolic tangent function came from. The hyperbolic tangent is merely a rescaled version of the more familiar logistic function. The logistic function has the range [0,1], whereas sometimes it is more convenient to have a function (TANH) with range [-1,1]. If L(x) is the logistic function, then tanh(x) = 2 L(2x) - 1.