With big data, data governance challenges escalate in many ways:
- The diversity of data sources means that there are minimal standards for data structure, definition, semantics and content.
- The lack of control over data production means that you can’t enforce data quality at the source as you can do with your internal operational applications.
- Because the problem is not about accessing and storing the data, the issue moves to the question of relevance and meaningfulness.
- Privacy and regulations is also an important challenge for data governance bodies to address, by setting up retention policies to comply with privacy regulations.
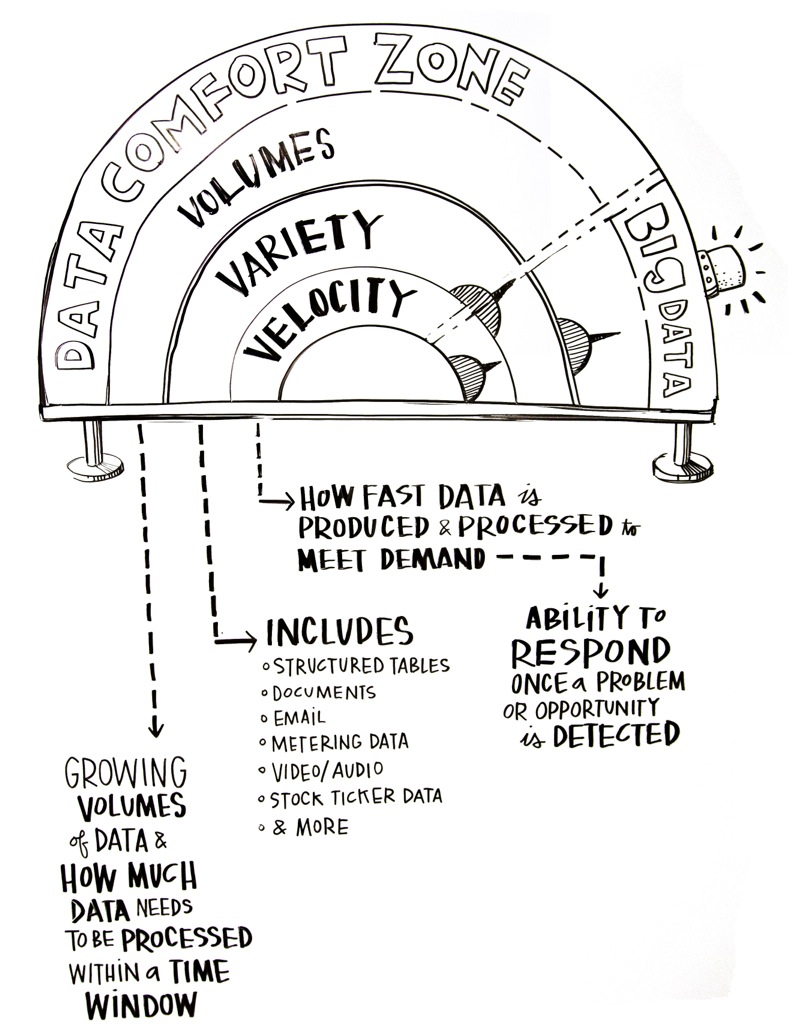
- Finally, there is a real risk of “fast trash” raised with the promises of real time analytics, meaning you get results fast but they might not be good results.
From the experience of big data early adopters, we can already draw some lessons learned and form some recommendations for those who are joining the party.
1. Entrench data governance from the start
As discussed in my previous data governance and big data blog post, failing to incorporate a strong data governance framework from the start is likely to transform your data lake in a data swamp.
The most important questions to be considered in those early days are:
- What insight do we need to increase the bottom line?
- How do we reconcile the two worlds of traditional data warehouses and data lakes?
- What are our privacy and regulatory constraints?
- How do we ensure that lack of data quality does not annihilate the benefits of quantity?
2. Appoint new data stewards
Typically, big data projects are initiated in two very different ways:
- By an isolated department who is looking to find new gold nuggets while keeping IT in the dark.
- By technical geeks within the IT department, experimenting with new and cheap technologies with no clear business outcome in mind.
Both scenarios are equally bad, and this is where data governance can help.
For most organizations, data governance is a nascent practice that is not yet fully established as a business function, and already, they need to rethink their approach in order to cope with the specific requirements of big data initiatives.
My recommendation is to expand the existing data governance framework, reusing existing practices whenever possible, but without assuming that the same recipe will work for big data. Appointing new data stewards specifically focused on big data might be a good idea considering that big data requires a fundamental shift in culture and approach to data management.
3. Focus on metadata management
Sometimes, metadata is as valuable as the content itself. If you can’t apply the same level of rigor to the governance of big data without jeopardizing its benefits, it is still crucial to get a grasp on big metadata.
Traditional metadata management includes the development of a logical data model and a description of how databases interact between each other. But a good big data model describes how servers map to internal and external data sources and reduce gushing streams of data to useful and relevant information.
4. Find the balance between control and velocity
More data doesn’t necessarily mean better decisions. At the end of the day, a decision made on petabytes of bad data is no better than a decision based on a small set of inaccurate information.
Enforcing some level of data quality control on new data sources will therefore ensure that expected benefits are achieved. At the same time, it is necessary to protect one of the most valuable aspect of big data which is its velocity and the ability to bring together vast amount of disparate data from various sources in a timely fashion and to process this data stream as it flows.
In some cases, it is preferable to manage data quality at the point of use, as opposed to during the consolidation process. To this end, it is useful to provide individual users with easy DQ assessment methods and data profiling services so that they can assess the suitability of data sets to their specific purposes.
5. Start with existing data before bringing new data sources
The final recommendation here is to start leveraging the vast amount of data already available before trying to leverage external data sources. This could include historical data that is too expensive to manage in traditional EDW, unstructured data such as emails, call recordings, web logs, etc.
It is estimated that financial institutions only use one percent of the data they have for analytical purposes. The rest is sometimes called "dark data" and represent a gold mine that you can start exploring and harvesting without the complication and cost of bringing in new data streams.
Adopting those simple guidelines when embarking on your big data journey will help reducing the risks and maximising the value, as well as streamlining the adoption of the new technologies and usage scenarios involved. With the soaring number of organizations currently experimenting with big data, we can fully expect a rapid learning curve across industries about what it takes to successfully harvest the value of big data.
Sign up now for an upcoming big data webinar, or learn more about SAS vision for data governance and big data.
