Weighed down by what has gone before, and what is needed to keep the lights on, the CIOs at many organizations I have worked with have turned to Hadoop with the hope of utilizing it as a major component of an IT infrastructure and as part of their modernization and migration program for analytics and BI.
In my previous posts, I explored the world of traditional IT as it relates to Hadoop for those CIOs. We have looked at how Hadoop can be deployed without throwing away your warehouse and put forward some approaches people are taking around the data lake concept. All of these are generally focused on finding economically more viable approaches to what we expect to come in the future. If you like, these organizations are focused on improving what they do today while driving down costs.
In parallel to this, two questions have come up time and time again as I have worked with established organizations, of all sizes, over the past 6-12 months. Those questions are:
- “How can we, with all their legacy technology constraints, hard to change processes and need to focus on cost control, possibly enable all our business units to compete with nimble competitors that are starting to cast a shadow over many parts of our business?”
- “How can we challenge the age old perceptions and approaches of IT, in order to support the business in getting answers to their questions?”
How do these questions relate to Hadoop?
These questions are arising, in my opinion, as farsighted organizations have realized that the dramatic move to digital is threatening their very existence. The barriers to creating, marketing and selling new, innovative digital services have evaporated, and start-ups disrupting traditional business models is now the new norm. Digital services can travel globally attacking your customer base in minutes, and there is no longer a need for the up-front investment in things like distribution channels that kept companies protected in the past. In addition, an aging IT organization is sometimes so focused on optimizing what they have, and keeping it under control, that they are missing the opportunity to deliver a service that could fundamentally alter the organization.
We have worked with some progressive companies to deploy a “big data innovation lab” and to establish it as a service to the business, based around Hadoop and commodity hardware. The lab provides a collaborative place for experimentation to take place around the organization. Components of big data innovation include a broad set of discovery centric capabilities along with the technologies and skills that allows organizations to offer a service that empowers business units to come try things out without needing to build business cases or have specialized staff, so innovation can proceed as fast as the lab's service can execute.
Experimentation has to happen if you want to drive innovation. Nothing was ever created without experimenting and some of the best inventions are by-products of an experiment that resulted in an unexpected and useful outcome. In this new digital world there is a broad array of constant innovation and discovery happening. While it remains the case that some breakthroughs will take years to discover and market, it is also true that sometimes all it takes is an accidental discovery of something you were not looking for. That is why a big data innovation lab is critical.
Five key points related to a big data innovation lab
If you're considering a big data innovation lab, keep these points in mind:
- In a big data innovation lab the more data (both in volume and detail) you have, the better. The more you constrain volume or detail, the more you limit the breadth and depth of experimentation. However, as you do not know the value yet it needs to be stored and analysed in a low cost manner which is where Hadoop plays predominant role given its economic model.
- To enable experimentation in the big data innovation lab you need data from within (across departments and systems) AND from outside (social media data, location data, weather data, dark data, machine data, etc.). Of course, any environment has to respect privacy and data use regulations, but outside of that there should be nothing off limits. To enable the broadest experimentation, data silos should be smashed together with external data, which can be counter to some previous opinions. The flexibility of Hadoop plays a major role in enabling this with its schema-on-read approach to bring together whatever data is needed for each experiment, not to mention the cost angle again that lets you bring data sources that were previously separated for many good reasons together in this lab environment for a specific purpose.
- Given the expected data volumes you will have in a big data innovation lab, having access to a large amount of processing power is also vital. This is where a Hadoop cluster delivers with cheap disks, many fast processors at your disposal and commodity hardware. Essentially Hadoop provides cheap access to speed the processing of that data.
- Your big data innovation lab needs to be established with the right technology to expose the required capabilities for all phases of an experiment, from ingesting the data, looking at the data to see what is there, transforming it if needed, and then to go on a discovery journey in many dimensions.
- Just as importantly, the lab needs to have people that support it with the right skills to grab the right data, manipulate it and visualize it and interpret the results working collaboratively alongside the business client. In essence, the service provides the technology platform, the tools and the people to support those consuming the service as they experiment.
The below graphic shows some of the considerations of a big data innovation lab, which have to be in place before you can offer this innovative service to the business. Most of them are pretty self-describing given we want this lab to operate at the lowest cost possible and you can join this webinar to hear more.
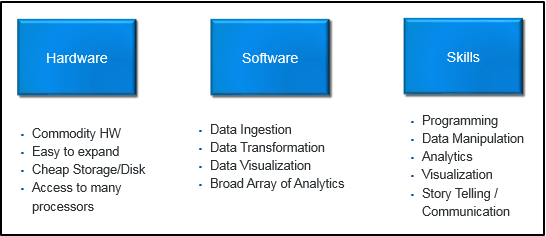
It is important to note that from a skills perspective, the lab needs people who are comfortable operating most things in the lab without broader IT involvement including data ingestion and manipulation but also analytics. This is the place where we hear a lot about the data scientist, who I see as a person who can cross a number of domains to drive the innovative use of data, working collaboratively with those in the business consuming the service.
The mandate for those utilizing the big data innovation lab service is to use it to try out ideas that could lead to transformative disruptive change, not just incremental improvements, although they are always welcome. Sometimes, the results will be answers to questions around a specific idea and sometimes it might result in something you want to operationalize.
How to get your big data innovation lab started?
The big data innovation lab should be something you can quickly setup and offer as a service to the business. Technically speaking, you can start it out with a few nodes and enough storage to handle your initial data set, and then quickly scale it up from there. Assuming the hardware is in place, alongside Hadoop, then you can follow these steps:
Step 1 - Establish the Big Data Lab
In this step we ensure we have the right technology in place for the initial aims of the big data innovation lab service. Generally you see people either take a big bang approach or they look to phase it in.
Phase 1 – Provide the capability to ingest and manipulate data as well as to understand what data is there, allowing discovery, exploration and approachable analytics.
The first thing you will need to provide is the capability to ingest new data, or manipulate that which already exists, so that the big data innovation lab environment can be setup with the right data to ensure the service is effective. This should be possible without IT engagement, using specialist skills that support the big data innovation lab. Since you do not need to design any specific data model, adhere to any specific standards or worry too much about data quality and security, it should be relatively quick to set up.
From there you need the capability to explore, visualize and perform some level of approachable analytics, possibly by another member of the big data innovation lab team. Here, you can start to come up with some ideas about what the data might be able to tell you and get early answers to questions by working together with the business. Effectively, in this phase you would be providing the skills and the technology to help someone consuming the service to understand and explore the data. When the service is consumed normally, it is a combination of a business user, who understands the data being looked at, working collaboratively alongside those offering services as part of the lab, who drive the tools but leave the interpretation open to the business user.
Phase 2 – Provide the capability to apply analytics, and torture the data to confess.
Once you have the capabilities to get the data needed into the lab and to support data exploration and approachable analytics, you may be required to provide more advanced capabilities that can help to extract more answers than phase 1 capabilities could provide. Generally, in this phase you might need capabilities to support things like machine learning, unstructured data analysis, etc. Of course as you add those capabilities you need to add the relevant skilled people who can use those capabilities alongside the business user and who can communicate effectively so that the business user can interpret the results and ask the next question.
The core point in step one is to ensure you get the right people in place to support the big data innovation lab service and ensure that the big data innovation lab staff have the tools they need to be able to support the service you want to offer.
Step 2 – Build out the service offering
With the big data innovation lab capabilities, and people with relevant skills, in place you need to then offer the service to all parts of the business. This involves setting up a system to request use of the lab and its resources, scheduling the work and then of course executing it together. The big data innovation lab will then be the driver for a period of continuous innovation from throughout the organisation.
Step 3 – Establish a service transition group
The final step might be to have a group who are specialized in helping to take approaches and ideas incubated in the big data innovation lab into the production world. Ideally your big data innovation lab will provide you with a simple transition between the experimental innovative world and the highly governed and regulated operational world where you might like to deploy and execute your findings. Ensuring you have a clear bridge between the big data innovation lab and your operational worlds is critical as is having the right skills to transition things as part of the service when the business case is clear.
Conclusion
People who utilize the big data innovation lab always get value from it. Trying something, and quickly dismissing it, means that failing fast can become the mantra of any organization helping the speed of innovation and breading a new attitude of “can try” that is always present at a nimble start-up even in the most traditional of organizations by removing the burden of building complex business cases to try out even the most simple of ideas.
Hadoop provides a scalable and cheap platform for storage and processing that is rapidly evolving and maturing into the mainstream. Together with technologies from SAS, which help lower the entry level skillset needed as well as providing deep capabilities, they provide the foundation we believe companies need to establish a big data innovation lab that can enable any company to innovate like a start-up. Don’t be constrained by your past. It is time to setup an environment alongside what you have, or are modernizing, to let you break free and reduce the risk of you being out-competed.
Thinking about where to start your Hadoop journey? Why not start here! To learn more about the big data innovation lab concept, watch our upcoming webinar.

7 Comments
Pingback: Will fluid and flowing big data be more important than stationary and at rest big data? - SAS Voices
Pingback: Why the Internet of Things will change organizational interaction with customers
Pingback: Will fluid and flowing big data be more important than stationary and at rest big data? | Mark Torr
Pingback: The future of analytics within the enterprise architecture | Mark Torr
Pingback: Why the Internet of Things will change how you interact with customers | Mark Torr
Pingback: Want to profit from Hadoop? Consider these 4 reasons for developing a big data innovation lab | Mark Torr
Pingback: How you can use Hadoop to be as agile and innovative as a start-up! - Mark Torr