All hail the data lake, destroyer of enterprise data warehouses and the solution to all our enterprise data access problems! Ok – well, maybe not. In part four of this series I want to talk about the confusion in the market I am seeing around the data lake phrase, including a look at how the term seems to be evolving within organizations based on my recent interactions.
In my previous post, I discussed three common use cases for deploying Hadoop alongside existing enterprise data warehouse infrastructures, along with some of the benefits and reasons for doing so. All three cases either required no change to existing approaches, or they required only small changes in where the data should be flowing when Hadoop was introduced. Effectively, they are less disruptive approaches.
Over the past six months, however, I've started hearing more questions around something that many refer to as the data lake (you might also hear it called the enterprise data hub or other derivatives of that term). As you'll commonly find during emerging phases of a popular new technology, there's great confusion about the meaning of this term, and I think it is evolving.
The original data lake view
The wiktionary definition for a data lake is perhaps a good starting point:
A massive, easily accessible data repository built on (relatively) inexpensive computer hardware for storing "big data." Unlike data marts, which are optimized for data analysis by storing only some attributes and dropping data below the level aggregation, a data lake is designed to retain all attributes, especially so when you do not yet know what the scope of data or its use will.
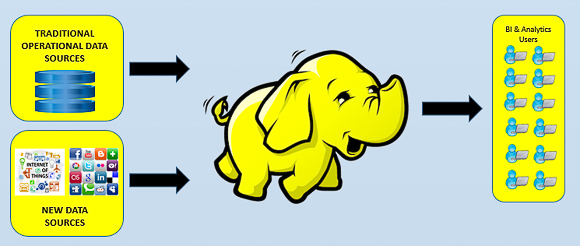
If you develop that idea further the aim of deploying a data lake, based on Hadoop, is to move the majority of an organization's data into Hadoop, with a long-term goal of Hadoop becoming the predominant and only data store over time, removing the need for the enterprise data warehouse (EDW) and data marts. While the practicalities, from both a security and ecosystem maturity standpoint, are still open to debate, the concept is worth contemplation.
When I think about the idea of a data lake, I am not convinced that the dream of doing everything in Hadoop ONLY is going to become a reality anytime soon, especially given the amount of re-engineering that would be required for most organizations. Even if we negate the re-engineering issues, we still have to consider whether Hadoop is ready to support all the applications that the EDW is supporting today, with appropriate service level agreements and regulatory requirements. Who knows if this will be the case in three to five years time.
Most organizations I have worked with have also reached the same conclusion, and hence I have noticed a distinct shift in what people perceive as the data lake.
The evolving data lake view
On some of my visits with larger organizations, I have started to see a new definition of the data lake emerging. In this new definition, organizations are redefining the data lake to represent the complete new data ecosystem they want to build. At the heart of this, Hadoop still retains a role as the predominant data store to collect everything up front, but the thinking does not stop there.
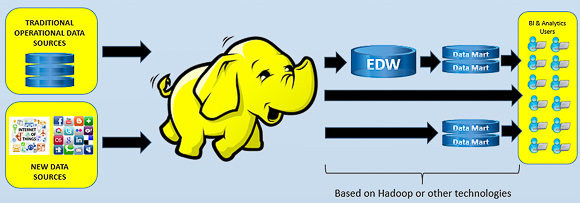
In these new style data lakes, previous investments made in RDBMS technologies and data appliances still play a role in storing data (along with emerging structured stores in Hadoop such as Hive, Cloudera Impala and Pivotal Hawq) and providing structure for certain applications downstream. If you like, Hadoop is the single source for all downstream applications and it is the place most of the "transformation" of data is intended to take place so that the end result can mostly just be copied into the downstream store. In this picture, event detection, real-time analytics and much more is linked to that initial Hadoop store and the amount of data that is stored and accessed downstream is likely to decrease greatly.
To make things more confusing, some people use the term data reservoir to describe this process of going from raw data, to Hadoop, and then out to structured stores. In this approach, the idea is that you slowly refine the data over time to get to what is made available. To this extent, the phrase data reservoir is emerging to describe a Hadoop centric platform that is still built with the idea of structure, as opposed to the data lake, which lacks structure or control.
Hopefully the market settles on a definition soon. I prefer the broader picture as I think it reflects the reality of where we will be for some time.
Other important technologies, not covered in this blog, are Data Federation/Virtualization and Event Stream Processing technologies. In almost all cases these two technologies play a major role in the path forwards around a Data Lake no matter which definition you apply. More on their role in future blogs.
Starting point
The organizations we are working with have all generally started out looking at one of the three first scenarios to build out their knowledge of Hadoop and to deliver some quick wins. From there, the more ambitious ones have had their enterprise architects looking at whether it's possible to implement the data lake concept (mostly with the view of Hadoop as part of an overall new data ecosystem not a total replacement). Many of these organizations are approaching their efforts with the assumption that some of the Hadoop limitations we see today will be rapidly overcome, and they will be positioned as the first movers right when the next generation digital data wave hits.
What are you seeing around the data lake term? Feel free to use the comments part of this post to share your views on data lakes (or their equivalents). I am interested to see how many more definitions there are in the market and to talk with organizations that are looking at data lakes as the path forwards.
The Big Data Lab!
In my next blog post I will discuss the concept of a "big data lab." Many of our customers are starting out their journey in the Hadoop world. Their hope is that a big data lab will allow them to setup innovation centers that are not bogged down by the weight of the production regulated worlds that generally define how fast they can innovate today. If you want to learn more about that concept, then please also join us for this Webinar.
If this blog was interesting to you, be sure to look at the previous three blogs in the series that can be read by following the links below:

2 Comments
Hi Mark,
good article. I think that the idea of using the data lake instead of the enterprise data warehouse (EDW) and data marts involve some risks. You can find a description of those risks in the following articles:
https://www.linkedin.com/pulse/data-lake-caveat-emptor-daniel-mannino?trk=mp-author-card
https://www.linkedin.com/pulse/data-lake-caveat-emptor-part-21-daniel-mannino?trk=mp-author-card
Regards,
Daniel
Pingback: Swimming in a lake of confusion: Does the Hadoop data lake make sense? - Mark Torr