So, you've heard the Hadoop hype and you are looking – or have already invested – into Hadoop. Maybe you have also realized some benefits from the Hadoop ecosystem. But now you want to maximize those benefits by using advanced analytics, or you might have heard about algorithms or machine learning libraries available for Hadoop that you want to try.
Indeed, there is a plethora of options in terms of analytic algorithms that you can use with Hadoop, ranging from open source developments such as Apache Maheout or Apache Spark, to commercial vendor tools that are capable of accessing Hadoop.
Since you might already be confused about what tools to use at this stage, my goal is to provide the information you need as you look ahead to analyzing data in Hadoop. Making successful use of advanced analytics requires more than a technology investment and a group of highly skilled data analysts. You should also think about managing processes and resources properly. So, before you jump ahead and make a decision as to what tools to use and how to equip data scientists with them, you may want to step back and think about why you are doing this.
Introducing the predictive analytics lifecycle
Today, many organizations want to use advanced analytics to gain some competitive advantage by gaining better insights into their customer’s behavior or other aspects of their organization such as their risks, product portfolios, suppliers, logistics networks, and so on. In order to achieve this level of advantage with analytics, you must keep two things in mind:
- Start thinking of advanced analytics as a strategic asset – and look into various ways to protect it. In this sense, a predictive model’s formula is no different from any other strategic asset you may have. You should ensure that any intellectual property you build around it remains safe within your organization. This will lead to questions about who can see what information about a model, especially in an environment where different people (potentially involving external partners) have collaborated on creating it.
- Be aware that any competitive advantage you may have gained with a predictive model at any particular point in time will disappear sooner or later if you don’t keep your model up to date. In other words, models do age due to various factors such as changing customer base or competitor behavior, disruptive technological innovations and so on. There comes a time when you need to update or even retire and replace them.
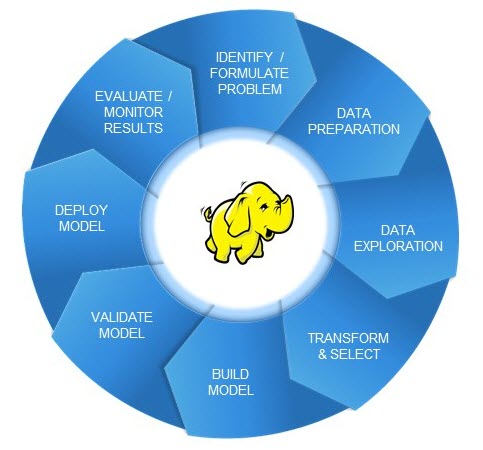
There are no new insights for companies that have reached a certain maturity level in using predictive analytics. It’s therefore no surprise that they have embraced the concept of the predictive analytics life cycle. Core to this concept is the fact that a predictive model goes through different stages of a lifecycle – starting from its birth up to its retirement and replacement by another model.
A second core concept is that different persona roles within the organization can get involved with the model at the various stages, including business functions, IT, and analysts or data scientists. Analytically mature organizations should make it a goal to move the model as efficiently as possible through these various lifecycle stages. After all, there is no use for a model that is already out of date by the time it is deployed for productive use.
Hadoop and the predictive analytics life cycle
Managing the life cycle of a predictive model can be beneficial when analyzing data in Hadoop as well, but there are a few factors – and challenges – that should be considered:
- Open source analytics concerns. Within the Hadoop ecosystem, the open source options for predictive modeling algorithms have their pros and cons. While the statistical programming language of the R Project will offer the greatest breadth of open source analytic algorithms, it might not scale well when it comes to processing larger amounts of data. Apache Spark and Mahout, on the other hand, are specifically designed to handle the amounts of data that Hadoop is typically used for, but currently they offer only a limited set of predictive analytic algorithms. This may change in the future, but what if you require both scalability to large data volumes AND a decent choice of algorithms?
- Security concerns. As Hadoop has its roots in the open source community, security concepts such as authorization and authentication are not a key strengths of Hadoop. Distributors like Cloudera and Hortonworks have done a great deal to build that functionality into their solutions. However, their focus is on data access and data management, not on access to modeling tools, particular models or even the process of validating and publishing models to a production environment.
- Exploration challenges. Hadoop, in its original design, is ideally suited for batch-oriented processing of large amounts of data. It’s not as efficient for ad-hoc queries by end users. Again, Hortonworks, Cloudera and other distributions have bridged that gap by creating user-friendly SQL-like databases and query tools that enable users to access Hadoop data in an interactive mode with the likes of Hive and Impala. However, requirements for the predictive analytics life cycle go beyond that functionality. For example, prior to building a model you may want to enable exploration on massive amounts of data through heavy use of interactive visualizations. This is a valuable step for building a model, as it provides a feeling for what outliers to remove or how to transform existing attributes or derive new attributes about the objects that you want to model.
- Workflow challenges. Although the Hadoop ecosystem embraces the concept of workflow management and includes some projects in that area (such as oozie workflow scheduler), this is not specifically tailored towards the needs of managing the workflow of a predictive analytics life cycle. To effectively manage the lifecycle of various models, you not only need a graphical user interface for non-IT workers, but also functionality to organize different lifecycle stages, and separate models by departments, projects, versions and so on. This might even go as far as managing business rules of what to do with the scores that result from a predictive model’s scoring run.
Be aware that a technical solution to address these challenges might not be enough. In some cases, you might also have to satisfy the needs of regulatory requirements, especially in the financial services industry. Even if you’re using your Hadoop in a laboratory proof-of-concept environment right now, questions about governance and compliance might start to arise as you move your predictive models to a production setting in the future.
Overcoming your Hadoop challenges
Governance, industry regulations,and organizational requirements that put certain restrictions on how analytics models can be deployed in a productive environment are not new to SAS. Therefore, SAS has built a stack of solutions that help customers manage their models throughout the predictive analytics life cycle. SAS has also embraced Hadoop as a new distributed storage technology for big data, and SAS can work alongside open source analytics products to overcome any shortcomings.
In fact, many SAS products and solutions for Hadoop have recently emerged that will allow customers to:
- Access data from a Hadoop cluster for modeling purposes and writing back generated predictive scores to Hadoop.
- Perform data management and data quality operations necessary to generate analytic base tables for modeling in the Hadoop cluster.
- Explore those data in an interactive and visual manner by lifting them once into shared memory of the distributed environment (and using in-memory technology to analyze it).
- Build predictive models in collaborative manner, again using in-memory technology to perform model training with highly parallelized algorithms that take advantage of distributed computing resources.
- Validate and publish these models to production, using scoring acceleration to speed up the scoring process by parallelizing scoring job execution across the nodes of the Hadoop cluster.
- Monitor model performance over time and initiate recalibration or new model setup for a new round of the life cycle, either triggered by alerts or in a completely automated fashion, and finally.
- Manage all required resources including servers, users, models, life cycle templates, workflows, reporting content etc. using SAS meta data.
Read this paper for more information on productivity in Hadoop, especially for managing the predictive analytics life cycle. It will be interesting to see how customers that have embarked on the Hadoop journey will progress to managing the predictive analytics life cycle, once they move their usage of Hadoop to more productive applications.
