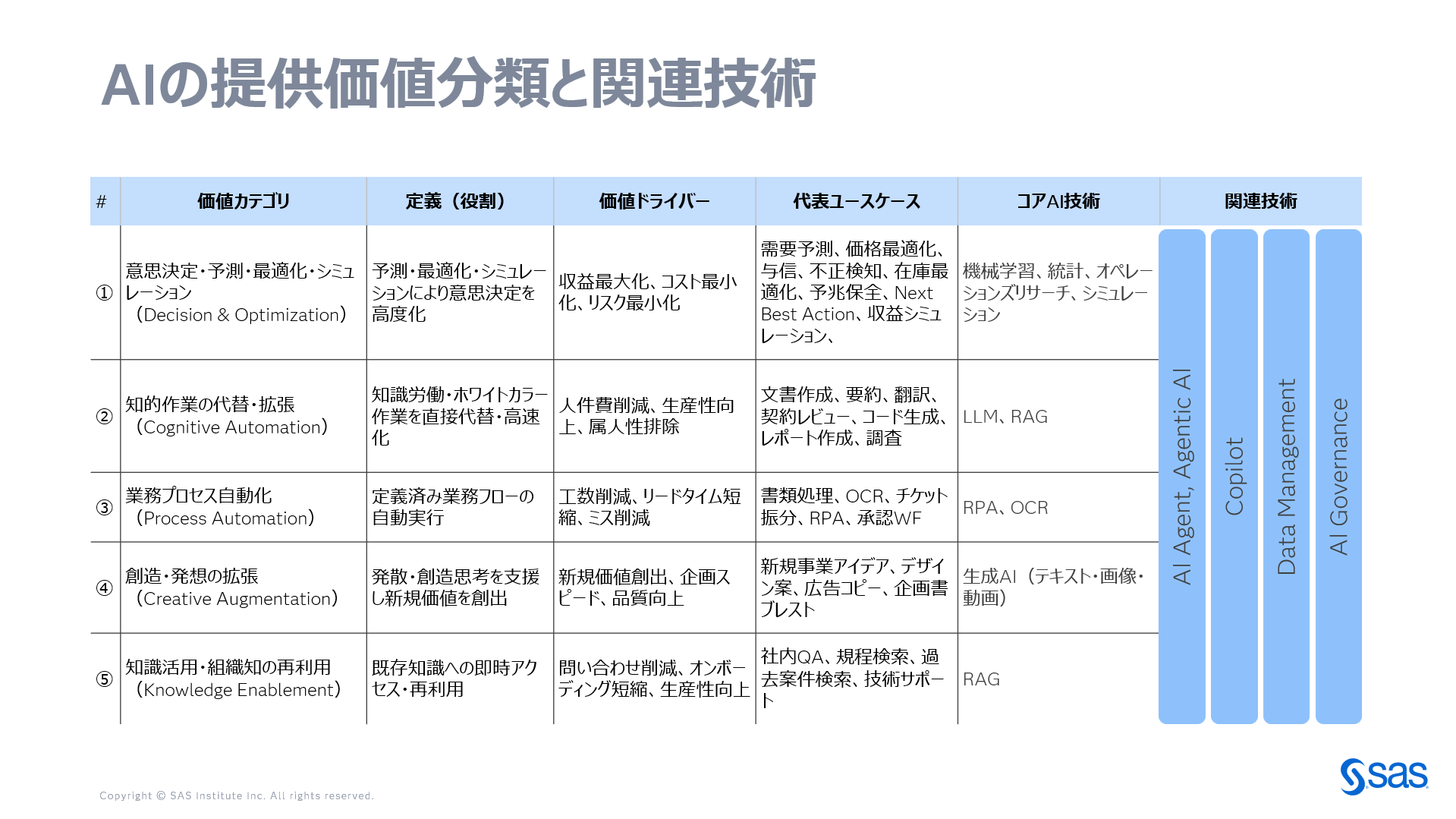

はじめに 昨今、AIをはじめとするさまざまな技術が登場する中で、「より良い意思決定」へのIT技術の貢献の仕方そのものが、新しい段階に入りつつあります。 AIエージェントやエージェンティックAIのトレンドで謡われているような、意思決定の自動化自体は、決して新しい話ではありません。ルールベース、最適化、予測モデルなどを用いた意思決定の自動化は、従来から多くの業務においてシステムによって実行されてきました。 一方で現在起きている変化は、単なる自動化の延長ではありません。 意思決定が エージェンティック(自律的)に実行され、人が事前に設計することなく、状況に応じて意思決定フローを創造し実行されるようになりつつあります。同時に、意思決定の自動化は一部の成熟した企業や部門に閉じたものではなく、より多くの人や業務に 民主化されつつある と言えます。これが昨今のエージェンティックAIのトレンドの本質です。 この変化に伴い、意思決定に求められる要件も、変化してきています。 こうした状況を踏まえると、どのAI技術を使うかを議論する前に、そもそも意思決定とは何で構成されているのか、そして AI技術はそのどこに、どのように貢献しうるのかを、理解しておく必要があると考えるに至りました。 本稿では、そのための前提として、意思決定の構造をあらためて整理します。目的は、特定の技術や手法を論じることではなく、より良い意思決定の実現のために、AI技術をどこにどのように適用すべきかを考えられるようにすることです。 意思決定とは何か あまり厳密にそして学術的に定義することは避けます。本稿における意思決定とは、利益を追求する、あるいは昨今はサステナブルな経営目的に、複数の選択肢の中から、ある目的に照らして目的関数を最大化する行動を選択するプロセスを指します。 意思決定は、単一の判断行為ではありません。情報の収集、分析・評価、選択、ルール準拠、実行、そして結果の受容までを含む、一連のプロセスとして捉える必要があります。 したがって、意思決定の良し悪しは、結果だけで評価されるべきものではなく、以下のような構造の要素それぞれを注視する必要があります。 意思決定を構成する6つの要素 意思決定を構造として捉えると、以下の6つの要素に分解することができると筆者は考えます。 1. スピード(Speed) 判断までに要する時間です。意思決定が遅れることは、それ自体が機会損失を生みます。細かく見ると、意思決定プロセスの開発とデプロイまでの時間、あるいはリアルタイムの応答性など、準備と実行それぞれが関係してきます。 昨今のトレンドから参入してきたエンジニアには意外と見過ごされがちですが、エージェンティックな意思決定においても、エージェントシステムとしての応答速度だけではなく、そのエージェンティックAIに組み込まれる「モデル」の開発・デプロイメント時間も重要であり、実は後者の方が実験的なプロセスを繰り返す必要があり時間がかかります。 2. 質(Quality) 意思決定がどれだけ望ましい結果をもたらす確率を高めているか、すなわち期待値や予測精度を指します。 質は経験や勘に委ねるものではなく、測定・評価され、改善される対象であるべきです。こちらも誤解されがちなこととして、過去のデータだけを学習データに使用することで、バイアスが含まれたモデルを作成してしまうことに注意が必要です。 3. 説明性(Explainability) なぜその判断に至ったのかを説明できるかどうかです。 意思決定がエージェンティックかつ民主化されるほど、膨大な量とスピードで実行された意思決定の判断理由を後から検証できること、管理者である人間が説明責任を果たせることが重要になります。 4. 再現性・一貫性(Consistency) 同じ条件であれば、同じ判断がなされるかどうか。 属人性を排し、意思決定の品質の下限を保証するための要件です。これは自動化が進むほど、重要性が増します。 5. 学習性(Learning) 意思決定の結果をもとに、外界(顧客や製造装置)とのインタラクションによって得られた結果をもとに、プロセスやルール、モデルをタイムリーに改善できるかどうか。 意思決定は一度自動化すれば終わりではなく、継続的に学習し、進化し続ける必要があります。 6. 目的整合性(Objective Alignment) 個々の意思決定およびその連鎖が、経営目標や組織の目的と整合しているかどうか。 この要素を欠くと、局所的には合理的な判断が、全体としては価値を損なう結果を招きます。例えばキャンペーンは営業部隊のKPIを向上しますが、サプライチェーンのKPIを悪化させることが多く、企業内のバリューチェーン全体を目的関数にすることが本来重要です。 これらの要素のバランスを測ることが重要 これら6つの要素は、どれか一つだけを最大化すればよいものではありません。スピードを重視すれば質や説明性が犠牲になり、再現性を重視すれば学習が止まることもあります。より良い意思決定とは、これら6要素をバランスよく満たし、継続的に改善していくことに他なりません。 攻め・守りの意思決定との関係 最後に、これまで本ブログで取り上げてきた「攻めの意思決定」「守りの意思決定」を、本稿で整理した6つの要素にマッピングしてみます。 参考1:守りの需要予測から、攻めの収益最大化への転換をするために 参考2:そのデータ活用は攻め?守り? 守りの意思決定は、再現性、説明性、目的整合性が特に重要となる意思決定です。既存プロセスを安定的に回し、品質の下限を保証することが求められます。