In The Princess Bride, one of my favorite movies, our hero Westley – in an attempt to save his love, Buttercup – has to navigate the Fire Swamp. There, Westley and Buttercup encounter fire spouts, quicksand and the dreaded rodents of unusual size (RUS's). Each time he has a response to the threats and is able to get them through to the other side.
Just like Westley and Buttercup, our data heroes, which include the business analysts and data scientists, must brave the Data Swamp. What's a Data Swamp? It's a junkyard of minimally processed, dirty data that our Data Lakes, once filled with so much promise, can easily become.
How can you prepare yourself for the Data Swamp? Data preparation, data munging, data wrangling and data blending are all terms used to describe the challenging process that business analysts and data scientists go through on a daily basis. They have to acquire data from multiple sources, profile it to better understand it, transform it into the right format, clean it up, and then deliver it in-memory for visualization, analysis or reporting.
In fact, a Ventana Research study estimates that "More than 45 percent of their time goes to preparing data for analysis or reviewing the quality and consistency of data." (My colleague Mazhar writes in more detail about self-service data preparation challenges and benefits here.)
SAS Data Loader for Hadoop is certified to work on both Cloudera and Hortonworks instances of Hadoop and provides self-service big data preparation, data quality and data integration capabilities for business analysts and data scientists. (Learn more about SAS Data Loader for Hadoop - and sign up for a free trial)
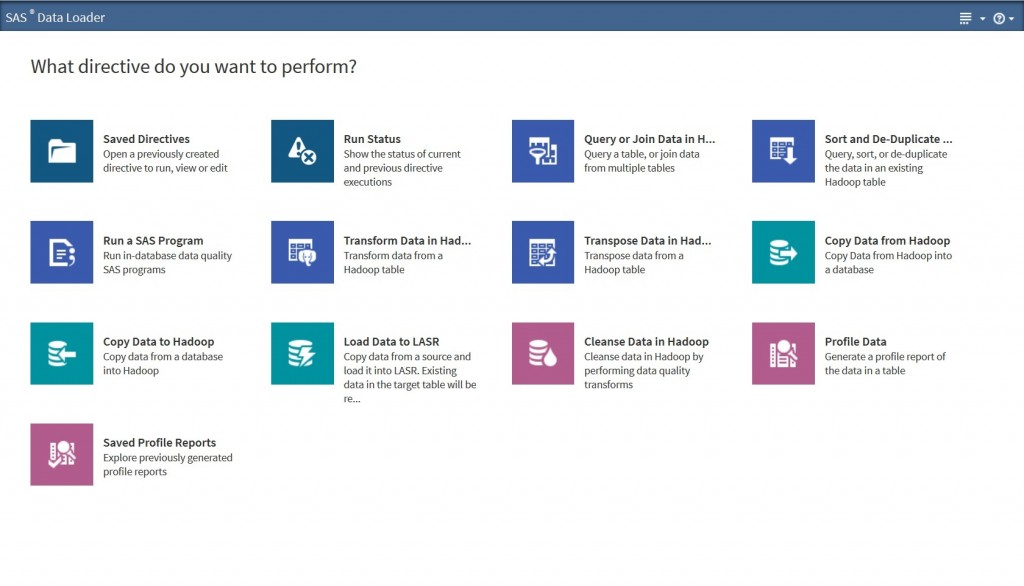
The point-and-click user interface allows users to prepare, integrate and cleanse big data faster and easier without writing code. It also provides the analytical power of SAS underneath the hood using the SAS Embedded Process, a lightweight SAS execution engine. This allows users to harness the big compute power of Hadoop by pushing code and data quality processing down to the cluster for improved scalability, governance and performance. Inconceivable? Not any more.
In many ways, managing data on Hadoop is like Westley navigating the quicksands of the Fire Swamp. With so many different open source components of the Hadoop ecosystem released at different times, it can be difficult to get the proven stability and support that SAS and it's Hadoop partners can bring to the table. Clark Bradley, another colleague, writes in more detail about the SAS and Hadoop capabilities in the Snap, Crackle, Pop of Data Management on Hadoop.
Once you've successfully transformed your Data Swamp into a Data Lake, you can live happily ever after. Have fun storming the castle!

1 Comment
Pingback: Provisioning Data for Advanced Analytics with SAS Data Loader for Hadoop