 In part one of this blog posting series, we introduced machine learning models as a multifaceted and evolving topic. The complexity that gives extraordinary predictive abilities also makes these models challenging to understand. They generally don’t provide a clear explanation, and brands experimenting with machine learning are questioning whether they can trust the models.
In part one of this blog posting series, we introduced machine learning models as a multifaceted and evolving topic. The complexity that gives extraordinary predictive abilities also makes these models challenging to understand. They generally don’t provide a clear explanation, and brands experimenting with machine learning are questioning whether they can trust the models.
In part two of this series, we will address the following questions:
- Do marketers and consumers really need interpretability from machine learning?
- When is interpretability needed within a brand’s adoption curve of analytics?
Defining interpretability
What exactly does interpretability mean? First, it is not about understanding every detail about how a model works for each training data point. Interpretability enables analysts to explain to campaign managers, creative designers, A/B testers and marketing technologists why a particular decision is being made. More specifically, in the context of journey conversion analysis, it encapsulates:
Understanding the main drivers that affect why customers convert.
- Explaining the decisions that are made by an algorithm to classify a customer as highly probable of converting (or not converting).
- Finding out the patterns/rules/features that are learned by an algorithm to help explain consumer decisions.
- Being critical by helping analysts to challenge the results and ensure robustness and unbiased decisions.
Do marketers and consumers really need interpretability from machine learning?
If your initial reaction is “no” to this question, here is an alternative perspective.
Marketing analysts want to build and deploy offer recommendations with high accuracy. They want to understand the model’s underpinnings and pick the best algorithm for the problem. If they can influence others to use their derived insights, and key performance indicators improve, who’s getting that promotion sooner than expected?
End users who serve as the recipients of the analyst’s recommendations want to know why a model gives a certain prediction. They want to know how they will be affected by those decisions - for better or worse. These users have emotional desires to trust the model because they rely on them for job security.
Consumers, in exchange for their valued attention, want to be treated fairly, and with personalized relevance. If they are mistreated, they may reject the brand and switch to a competitor. They expect a certain measure of trust when they are shopping online or clicking ads.
Regulators and lawmakers want to make the system fair and transparent. They want to protect consumers. With the inevitable rise of machine learning algorithms, they are becoming more concerned about the decisions made by models.
All those segments want similar things from black box models. They want the models to be:
- Transparent: The system can explain how it works and/or why it gives certain predictions.
- Trustworthy: The system can handle different scenarios in the real world without continuous control.
- Explainable: The system can convey useful information about its inner workings, for the patterns that it learns and for the results that it gives.
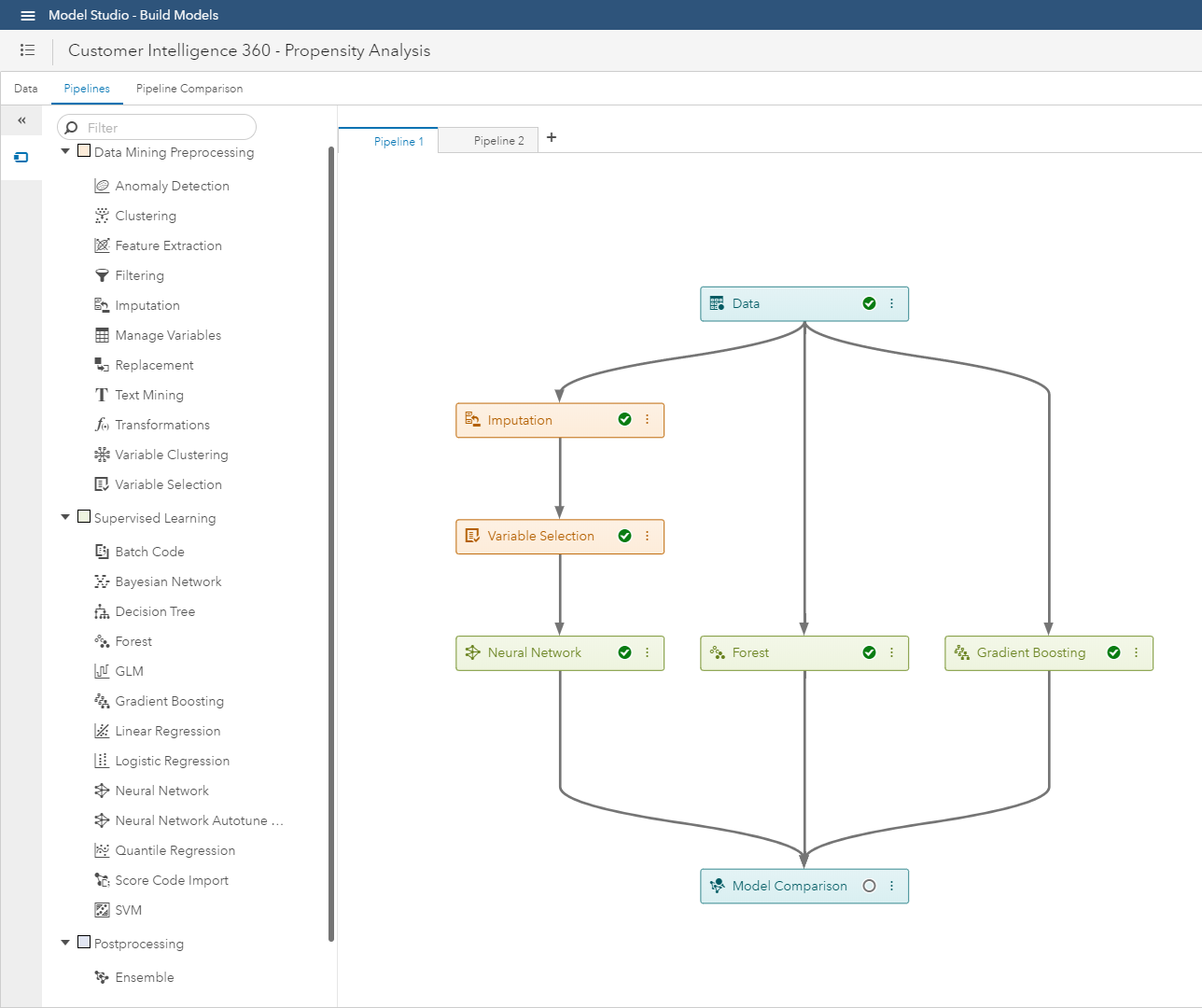
Within SAS Customer Intelligence 360 using SAS Visual Data Mining & Machine Learning, you have control over:
When is interpretability needed within a brand’s adoption curve of analytics?
In which stage of the analytical process do you need interpretability? It may not be necessary to understand how a model makes its predictions for every application. However, the higher the stakes, the more likely accuracy, as well as transparency, is necessary. After you define your mission, you should focus on which techniques you need in each stage of the workflow.
Stage one: Interpretability in pre-modeling
Understanding your data set is very important before you start building. Exploratory data analysis and visualization techniques immediately come into play. This can include summarizing the main characteristics, finding critical points and surfacing the relevant features from your data.
After you have an overall understanding, you need to think about which features you are going to use. If you intend on explaining the input-output relationship of your predictors, you need to start with meaningful inputs. While highly engineered features can boost the accuracy of your model, they will not be interpretable when you put the model to use.
Stage two: Interpretability in modeling.
In general, white box approaches are models that focus on predicting average behavior. In contrast, black box approaches often make more accurate predictions for the finer details (or localized aspects) of modeled behaviors.
In a sense, white box models approximate their fit of data while creating a way for analysts to extract precise stories. Black box methods can train sharper models, but only allow analysts to express approximated stories.
White box models: Decision trees and regression algorithms are the traditional tools here. They are easy to understand when used with few predictors. They use interpretable transformations and give you global intuition about how things work, which helps you understand what’s going on anywhere in the model. On the flip side, if you have hundreds of features and build a very deep, large decision tree, things can become complicated rapidly for digital marketing execution.
Black box models: Deep neural networks, forests and gradient boosting can be considered here. They provide countless predictors, form complex transformations, and detect localized patterns in training making comprehensive interpretation tricky. It’s typically hard to visualize and understand what is going on inside these models. They are even harder to communicate to a target audience. However, their prediction accuracy can be much better.
Stage three: Interpretability in post-modeling
Interpretability in the model predictions helps you inspect the relationships between input features and output predictions. Adding transparency at this phase can help you understand the most important features for a model, how those features affect the predictions and how sensitive your model is to certain features.

Takeaways
In this article, we addressed and made cases for:
- What interpretability is within machine learning?
- Do we really need it?
- Where does it apply?
In part three of this blog posting series, we will progress and share more details on:
- Interpretability techniques within SAS Customer Intelligence 360 & SAS Viya
- Proxy methods
- Post-modeling diagnostics
We will approach these topics from the perspective of a practitioner.
