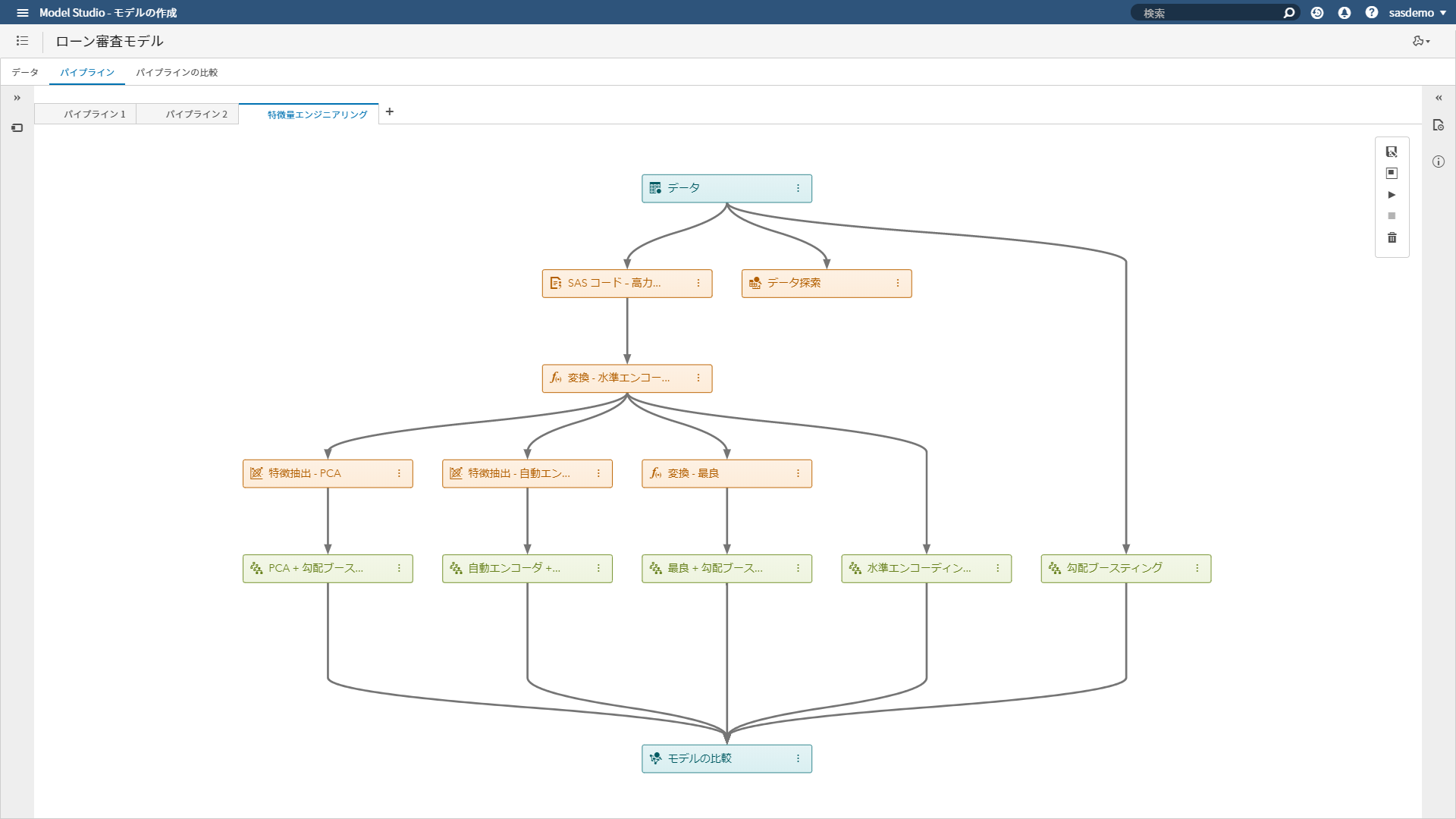
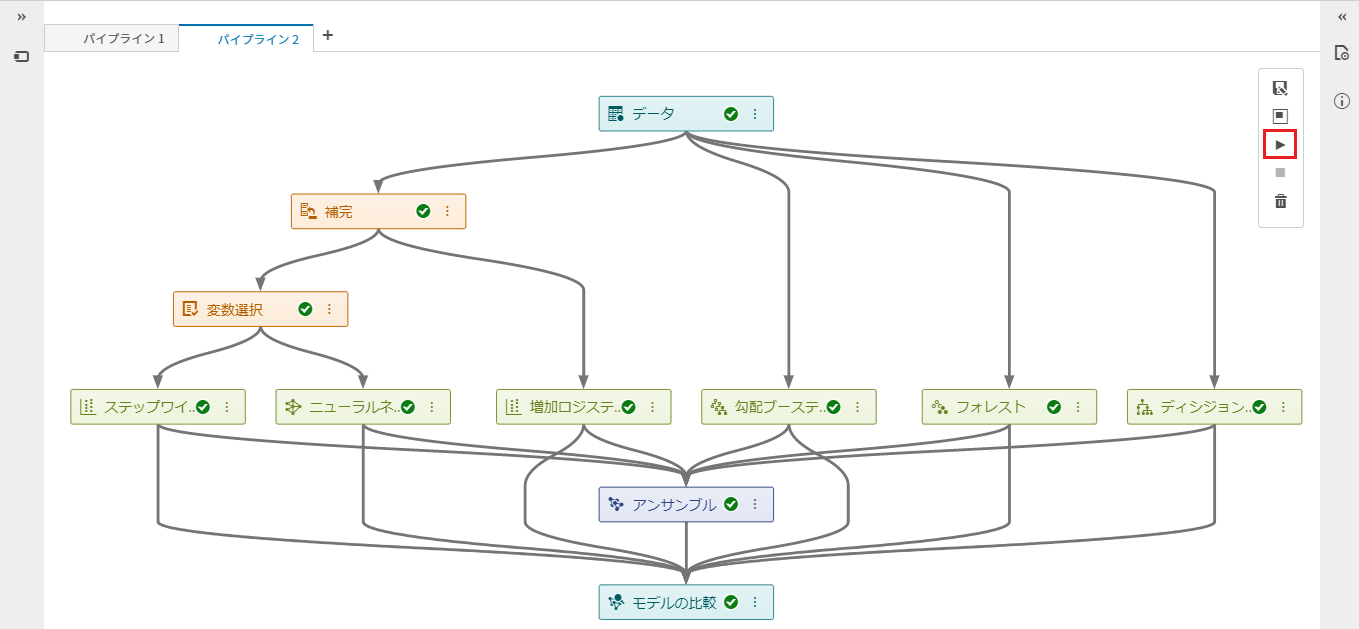
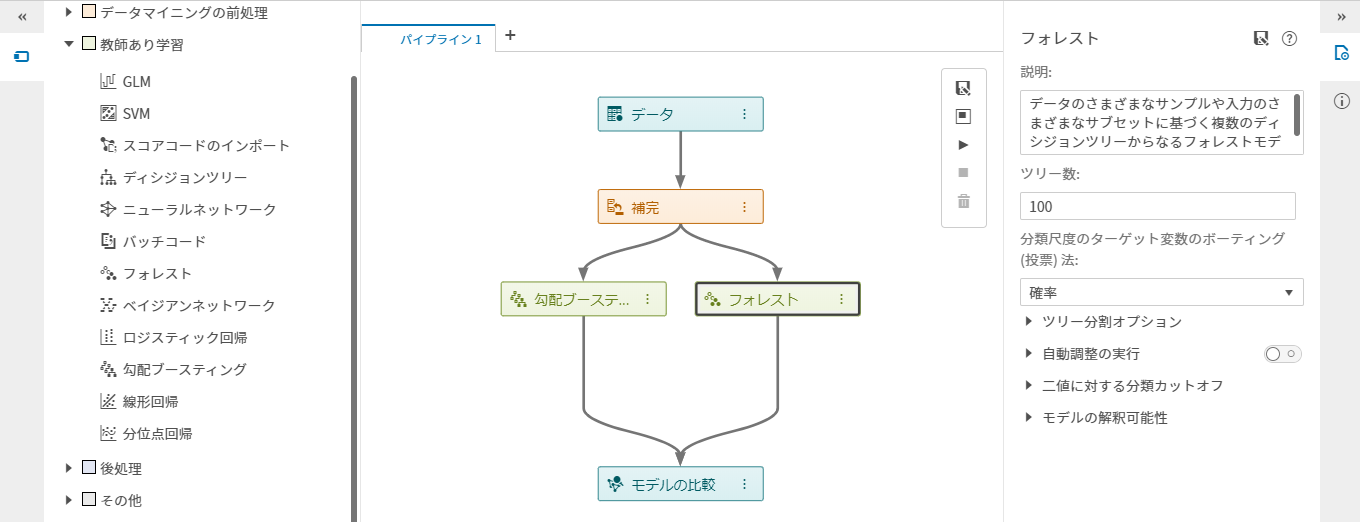
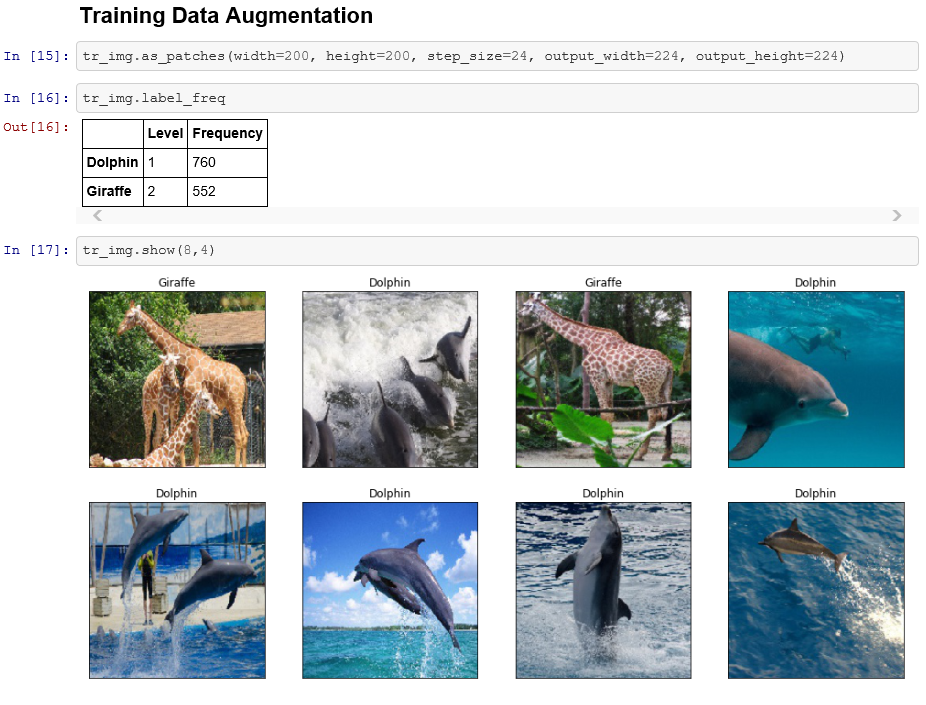
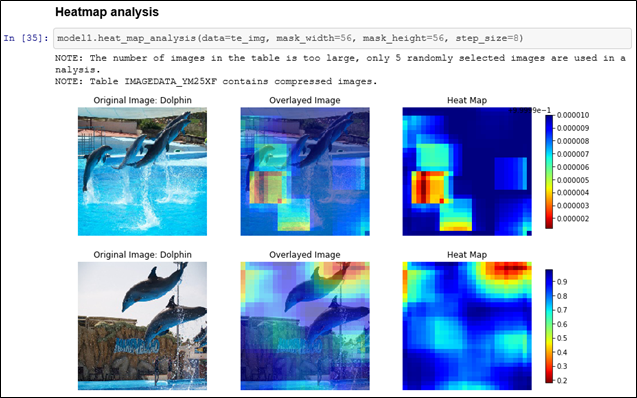
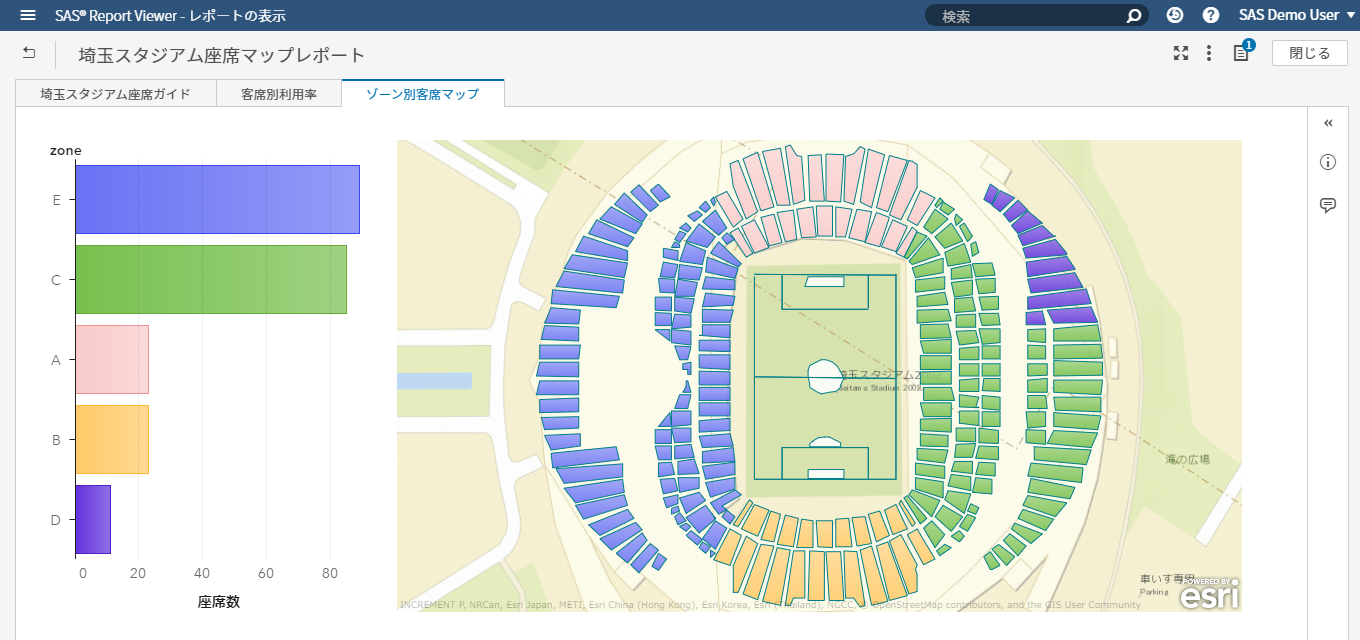
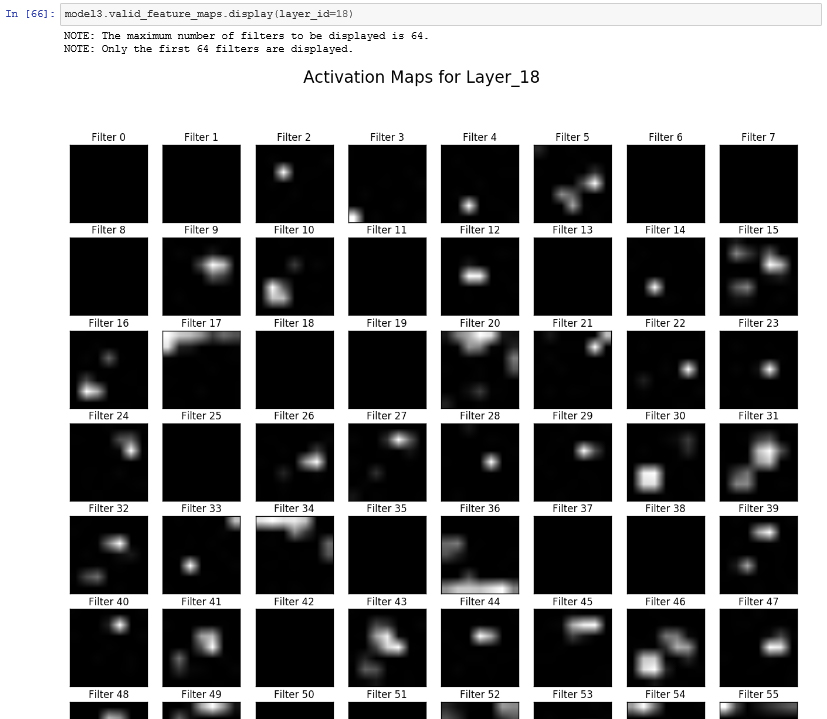
SASの一つの顔は、アナリティクスで営利目的の意思決定を支援 筆者は、SAS社員として、20年以上に渡りアナリティクスおよびAIで企業・組織を支援してきました。 金融機関における、リスク管理や債権回収の最適化 通信業における、顧客LTV最大化、ネットワーク最適化やマーケティング活動の最適化 製造業における、需要予測、在庫最適化、製造品質の向上や調達最適化 流通・小売業における、需要予測やサプライチェーン最適化 運輸業における、輸送最適化や料金最適化 ライフサイエンス・製薬企業における、業務の最適化 官公庁における、市民サービス向上のための不正検知 など、様々な業種・業務においてアナリティクスの適用によるお客様のビジネス課題の解決に携わってきました。営利目的(ここでは市民サービスの向上も含めることにします)の企業・組織におけるアナリティクスの活用目的は主に以下の3つに集約されます。 収益(売り上げ)の増大 コストの低減 リスク管理 アナリティクスは、いわゆる「データ分析」を手段とし、過去起きたことを把握して問題を定義し、次に将来を予測し、様々な選択肢の中から最適な予測に基づいて意思決定をしていくことになりますが、その過程の中で、起きてほしい事象を予測して促進したり、起きてほしくない事象を予測して防いだり、その予測のばらつきを管理したりということを行っていきます。 このような営利目的でのアナリティクスの活用はSASという会社が誕生した40年以上前から行われており、基本的な活用フレームワークは変わっていません。IT技術の進化によって、利用可能なデータの種類や大きさが、増えてきただけにすぎないと言えます。例えば、昨今のAIブームの代表格であるディープラーニングですが、ディープラーニングという処理方式の進化と、GPUという処理機械の進化によって、非構造化データをより良く構造化しているものであり、もちろんモデリング時のパラメータ推定値は何十億倍にはなっていますが、モデリングのための1データソースにすぎません。もう少しするとディープラーニングも使いやすくなり、他の手法同様、それを使いこなすあるいは手法を発展させることに時間を費やすフェーズから、(中身を気にせず)使いこなせてあたりまえの時代になるのではないでしょうか。 SASのもう一つの顔、そして、SAS社員としての誇り、Data for Goodへのアナリティクスの適用 前置きが長くなりましたが、SAS社員としてアナリティクスに携わってきた中で幸運だったのは、データの管理、統計解析、機械学習、AI技術と、それを生かすためのアプリケーション化、そのためのツール、学習方法や、ビジネス価値を創出するための方法論や無数の事例に日常的に囲まれていたことだと思います。それにより、それら手段や適用可能性そのものを学習したり模索することではなく、その先の「どんな価値創出を成すか?」「様々な問題がある中で優先順位の高い解くべき問題はなにか?」という観点に時間というリソースを費やすことができていることだと思います。そのような日常の仕事環境においては、アナリティクスの活用を営利目的だけではなく、非営利目的の社会課題の解決に役立てるというのは企業の社会的責任を果たす観点においても必然であり、Data for Goodの取り組みとしてSAS社がユニークに貢献できることであり、SAS社員として誇れるところだと考えています。 最終的に成果を左右するのは「データ」 そして、もう一つの真実に我々は常に直面します。クラウド・テクノロジー、機械学習、ディープラーニングなどの処理テクノロジーがどんなに進歩しようともアナリティクス/AIによって得られる成果を左右するのは「データ」です。どのようなデータから学習するかによって結果は決まってきます。 IoT技術で収集したセンサーデータは知りたい「モノ」の真実を表しているだろうか? 学習データに付与されたラベル情報は正確だろうか? 学習データは目的を達成するために必要な集合だろうか? そのデータは顧客の心理や従業員の心理をどこまで忠実に表しているだろうか? 特に、Data for Goodのチャレンジはまさにそのデータ収集からスタートします。ほとんどの場合、データは目的に対して収集する必要があります。そして、下記の取り組みのうち2つはまさに、我々一人一人が参加できる、市民によるデータサイエンス活動として、AI/アナリティクスの心臓部分であるデータをクラウドソーシングによって作り上げるプロジェクトです。 Data for Good: 人間社会に大きな影響を及ぼすミツバチの社会をより良くする 概要はこちらのプレスリリース「SAS、高度なアナリティクスと機械学習を通じて健康なミツバチの個体数を増大(日本語)」をご参照ください。 ミツバチは、人間の食糧に直接用いられる植物種全体の75%近くに関して受粉を行っていますが、ミツバチのコロニーの数は減少しており、人類の食糧供給の壊滅的な損失につながる可能性があります。この取り組みでは、IoT, 機械学習, AI技術, ビジュアライゼーションなどSAS のテクノロジーを活用し、ミツバチの個体数の保全/保護する様々なプロジェクトを推進しています。この取り組みは以下の3つのプロジェクトから成り立っています。 ミツバチの群れの健康を非侵襲的に監視 SASのIoT部門の研究者は、SAS Event Stream ProcessingおよびSAS Viyaソフトウェアで提供されているデジタル信号処理ツールと機械学習アルゴリズムを用いて、ミツバチの巣箱の状態をリアルタイムで非侵襲的に追跡するために、生物音響監視システムを開発しています。このシステムによって養蜂家は、コロニーの失敗につながりかねない巣箱の問題を効果的に理解し、予測できるようになります。 関連ページ:5 ways to measure