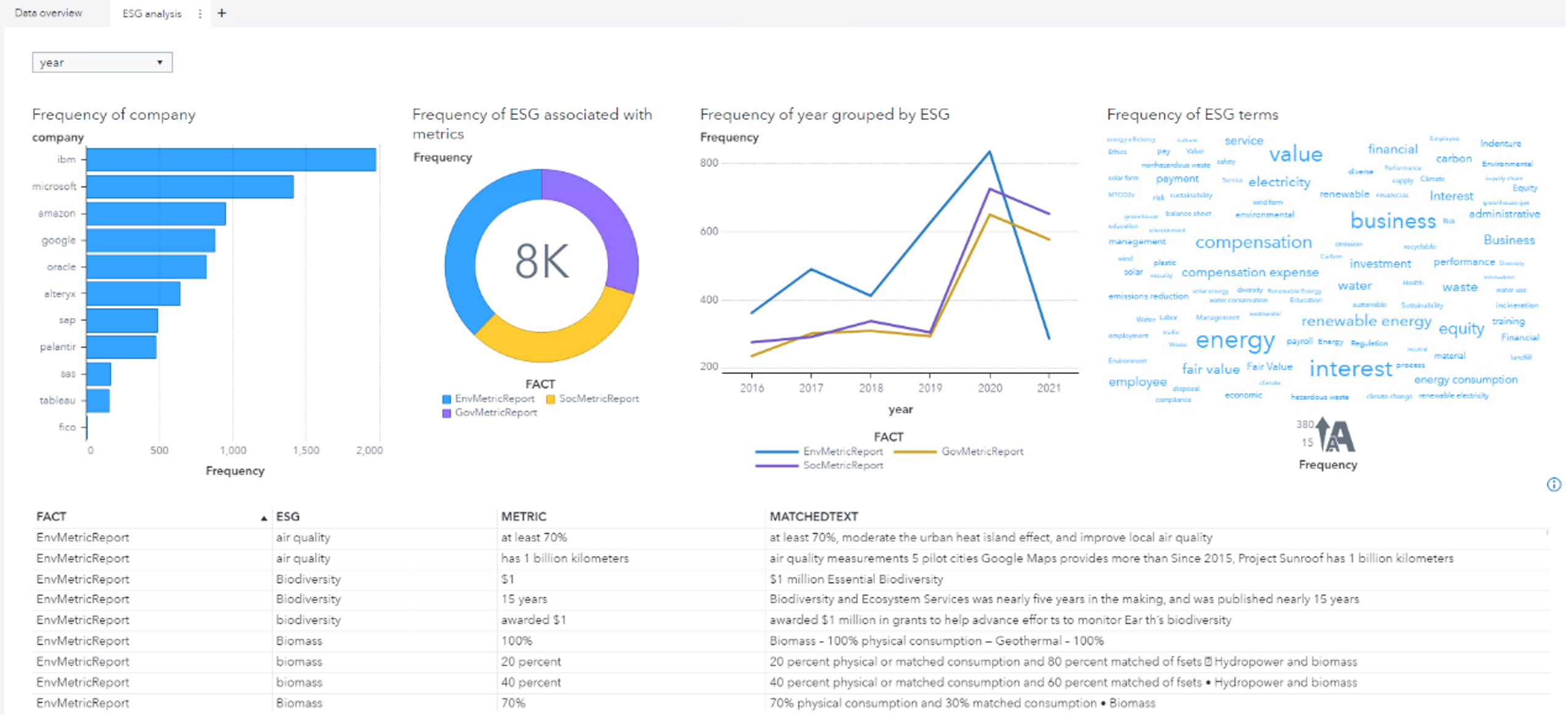
Find duplicates and near-duplicates in a corpus with Natural Language Processing
To find exact duplicates, matching all string pairs is the simplest approach, but it is not a very efficient or sufficient technique. Using the MD5 or SHA-1 hash algorithms can get us a correct outcome with a faster speed, yet near-duplicates would still not be on the radar. Text similarity is useful for finding files that look alike. There are various approaches to this and each of them has its own way to define documents that are considered duplicates. Furthermore, the definition of duplicate documents has implications for the type of processing and the results produced. Below are some of the options.
Using SAS Visual Text Analytics, you can customize and accomplish this task during your corpus analysis journey either with Python SWAT package or with PROC SQL in SAS.