
SAS has been a leading software provider for analyzing unstructured documents for many years. However, recent innovations by using large language models (like those supporting ChatGPT) have made automated analysis of textual information more popular. Text analytics uses natural language processing, document classification, and information extraction to identify, extract, and organize key contextual data buried within documents. These documents can be as brief as a few sentences or span thousands of pages. This blog post describes a problem that is more similar to the latter. It highlights SAS® Visual Text Analytics in a real-world example of digital transformation for a large customer grappling with manually reviewing patient medical records.
Medical records are a treasure trove of data buried in narrative written comments, often containing abbreviations that share multiple meanings. Manually locating, interpreting, and extracting critical information from these is difficult and time-consuming. The Health Information Technology for Economic and Clinical Health (HITECH) Act of 2009 created incentives for the adoption of electronic health records. However, incompatible systems often require providers to submit documents as scanned images. Despite HITECH’s incentives, some practices continue to use paper records and forms to capture relevant patient information. Think of the last time you visited a care provider and were asked to complete a patient history questionnaire.
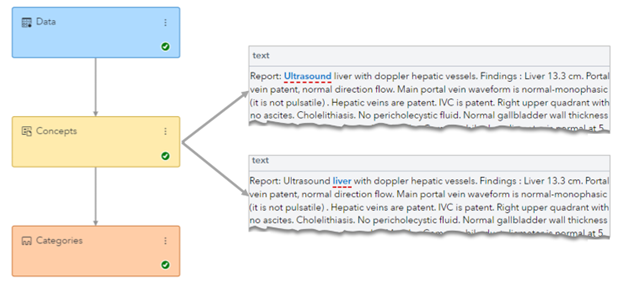
Converting these documents into useful, accessible, and structured output was a large healthcare customer's challenge. First, SAS was asked to develop a process to assist human medical record reviewers by identifying specific types of documents. Then, the targeted information that appears in a relevant context would be extracted. Both tasks are challenging, but extracting information colored by a complex and nuanced medical domain is particularly daunting. For example, does the abbreviation “AA” refer to aortic aneurysm or abdominal aorta? The model must recognize and process surrounding contextual cues to interpret appropriately. Figure 1 demonstrates how models rely on these cues to determine if specific text strings should be extracted. In this example, the model uses relevant contextual anchors like “f/u” (interpreted as “follow up”) to know the x-ray examination highlighted in blue has yet to be performed. As a result, this text portion is ignored when the model searches for records reporting x-ray results.

Using the SAS® Viya® platform as our foundation, we leveraged multiple tools and technologies to create a highly efficient multi-faceted workflow. For example, a third-party optical character recognition (OCR) service converts scanned images into digitized text. From there, SAS’ proprietary form-matching tool recognizes specific structured documents, extracts key values, and crops images for further analysis. Computer vision models built with SAS Viya: Machine Learning reviews the images and detects circled words, checked boxes, and other annotations to interpret selections made by patients or providers. Finally, SAS Visual Text Analytics handles the bulk of the workload, tackling the nuanced challenge of contextual analysis, information extraction, and data standardization. This entire process incorporates more than 40 analytic models, all coordinated and maintained by using SAS Viya. As a result, providers are automatically directed to key documents like radiology reports, where the model has extracted information like the procedure (such as an MRI), the tissue examined (such as the left knee), and the examination date.
Rule-based text analysis models (like those built with SAS Visual Text Analytics in Figure 2) currently might not be as fashionable as large language models. However, they are deterministic (reliable), interpretable (trustworthy), and computationally efficient (fast) without the need for expensive GPU hardware or external API services. For example, the combination of models SAS created currently processes more than six million document images daily, producing a significant return on investment for the customer. Consequently, the speed, repeatability, and accuracy of this process have enabled the customer to focus its human capital on serving patients more efficiently.
Summary
Building upon this project's ongoing and growing success (more than four years and counting), SAS Research and Development will include models to extract and analyze information from medical records as part of our new Packaged AI Models Initiative. These models will classify common elements of medical records (for example, hemograms, metabolic panels, progress notes, and so forth) and extract diagnostic results or other medical findings. These models can assist medical record reviewers, clinical researchers, or anyone interested in creating structured output from this critical source of unstructured data. This is an exciting time for SAS as the initiative creates a new resource for customers requiring smaller targeted models instead of large complex solutions. Read more about this innovative new direction planned for an international leader in data analysis.
LEARN MORE | SAS Models LEARN MORE | AI Technology for the Real World





