
Sequences are an important type of data that often occurs in fields such as medicine, business, finance, and education. The goal of sequential pattern mining is to discover frequently occurring sequences to extract useful knowledge from data. With the increase in the size of databases, mining long sequences is quite a challenging task. The sequence action set provides actions that are effective in sequence mining tasks for various data sets. In this post, we will show how the seqmc action is able to mine long sequences efficiently from a large database. The seqmc action uses Monte Carlo sampling to mine sequences within a transaction data set.
An event is a set of elements or items. A sequence is an ordered list of events. A database consists of many sequences. Our goal is to find frequently occurring ordered events or subsequences. Support for a sequence is defined as the frequency of occurrence of a sequence within the data set. It’s a meaningful parameter that helps in finding important frequent patterns. The number of occurrences of a sequence (also known as support) might not always represent a pattern's significance. A pattern with high frequency might not be significant because it is usually an expected pattern. However, a pattern with low frequency might be of interest. Mining long length frequent patterns from a large data set for low support value is challenging due to the large search space. Such a process is computationally costly. Therefore, choosing an efficient sequential pattern mining technique becomes important.
Sequence mining action set
The sequence action set contains actions to perform sequence mining. The cspade action is supported in the sequence action set. It’s an efficient sequential pattern mining algorithm for discovering all frequent sequences. It uses a vertical id-list database format that minimizes I/O costs by reducing database scans and effective lattice search techniques to minimize computational costs. The cspade action incorporates syntactic constraints on the mined sequences, which include length and width restrictions, as well as minimum and maximum gaps.
A sequence with k items is called a k-sequence. For example, a user can analyze a large data set for frequent sequences with a lower support value and length k. Let’s say the value of k is greater than or equal to 10. The cSpade algorithm will generate a substantial number of patterns from length 1 to k for a given support value. It takes a large memory space and a longer execution time to process all possible frequent sequences. It also requires post-processing to filter only the k-length sequence from the large output data set.
You can use the seqmc action to extract a long length sequence from a large data set. It is an approximate method. This means it relies on random sampling techniques for finding solutions (frequent sequences). Randomly sampled candidates are verified for a given minimum support value. Because of the randomness in sample selection, the final number of solutions is reduced. All the reported solutions exactly match that of an exact method like the cspade action. The seqmc action can process data distributed over a grid. The parallel implementation makes it more suitable for large database analysis.
Analyzing long frequent sequences on clickstream data for online shopping
The goal of this clickstream data analysis is to examine online visitors' behavior patterns. These patterns are a powerful reference for a number of areas. The areas include strategizing and planning, improving services and content, page display for better web modification, visitor behavior predictions, and marketing strategies. These will help online retailers gain valuable information about customers and their platforms.
The data set contains information on the clickstream from an online store offering clothing for pregnant women. The data are from five months in 2008 and include, among others, product category, location of the photo on the page, country of origin of the IP address, and product price in US dollars.
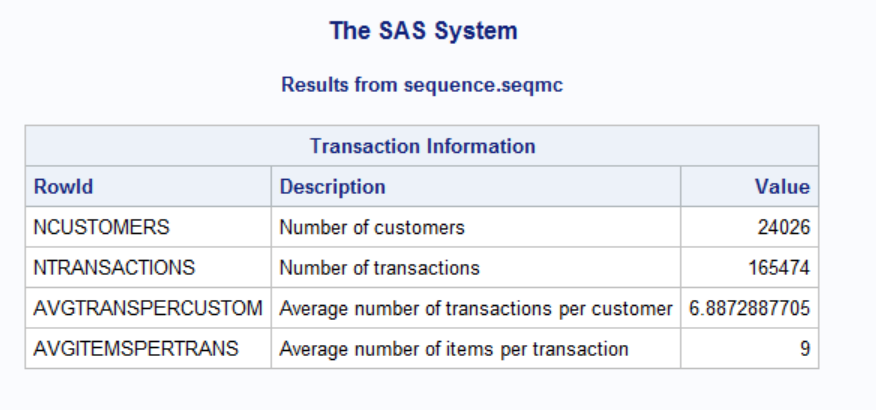
Table 1 gives descriptions of the clickstream data set. It is a sequential data set that contains 14 variables.
| Data Set Characteristics | Multivariate, Sequential |
| Number of Instances | 165,474 |
| Sequence Count | 24,026 |
| Average Sequence Length | 61.98 |
| Number of Attributes | 14 |
| Item Count | 317 |
Table 1: Clickstream data set description
The data set contains 24,026 clickstream sequences, which are a list of ordered clicks on different attributes. The total item count is 317, which are attributes chosen as an item for analysis. The total number of clicks (also known as instances) from all users in the data set is 165,474.
An itemset is a collection of items. This data set is interesting for algorithm testing because it is a sequence of itemsets instead of a sequence of items. The ‘Session Id’ column is used as the sequenceID, and the ‘Order’ column is utilized as the eventID. We delete the ‘Date’ column because only the ‘Order’ is used to generate sequences (the date is always identical for a given purchase). Columns that are used as attributes for itemID are ‘country’, ‘main category’, ‘clothing model’, ‘colour’, ‘location’, ‘model photography’, ‘price’, ‘price 2’, and ‘page’.
We are using the SPMF format of the original data, which is in CVS format. The data set can be obtained from this GitHub repository.
We further convert the online store’s SPMF horizontal data into a vertical data format that is acceptable input data set format for the seqmc action. The script used for this operation can be obtained from this GitHub repository.
Our goal is to analyze the input data set for generating long frequent sequences with low support values. For this experiment, we have selected “minSupport” as 0.01 (1%), which is a percentage value of an output sequence present in the input data set. We selected “k” as 10, which means the output frequent sequences with 10 items.
When we used the cspade action to generate output frequent sequences with similar input parameters, it was still running 24 hours later. The execution time and memory required to process the data for the 10-item output frequent sequence is very high because the cspade action will generate all possible combinations of frequent sequences from k =1 to 10. This will generate a large number of output frequent sequences, which might not be useful for further analysis of the data.
In the seqmc action for the sampling-candidate step, we use the “nSamples” parameter to randomly sample 2M candidates. For verifying the candidate step, we use “nSamplesToVerify” to verify 100K sample candidates for the given support criteria. We use the distributed grid environment with 5 nodes. Then we successfully generate 2608 10-item frequent sequences as output in less than 25 minutes.
Here is the SAS code used:
data sascas1.eshop; set work.eshop; run; proc cas; loadactionset "sequence"; sequence.seqmc / table="eshop", minSupport=0.01, casOut="seqout", itemID="item", eventID="eventid", sequenceID="seqid", k=10, seed=12345, nSamples=2000000, nSamplesToVerify=100000; run; quit; |
Here is the output of the seqmc action:
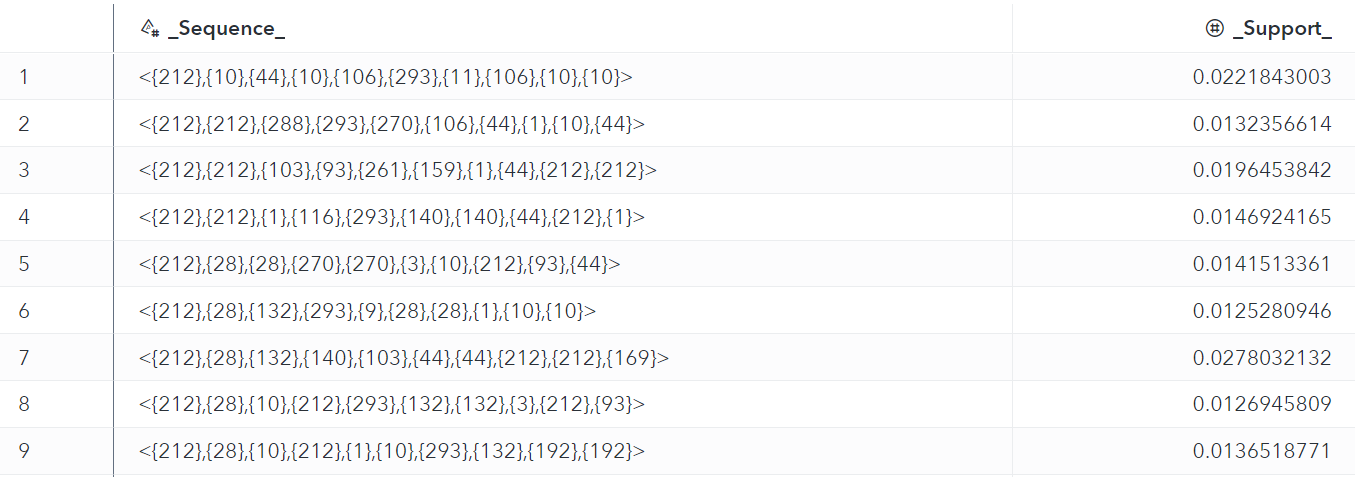
The output data set shown in Table 3 contains frequent sequences and their support percentage values, which signify the frequency of an output sequence. The higher value of nSamples and nSamplesToVerify means we will get closer to the exact number of solutions (output frequent sequences) that are being generated by exact methods like the cspade action. Also, we can control the number of output frequent sequences by nSamplesToVerify. This is because if all the sample candidates in the verifying method satisfy support criteria, we will get a maximum of those many sequences as output.
Conclusion
The sequence action set provides algorithms with different capabilities. The selection of action depends upon user data and mining constraints that the user might be interested in. The seqmc action is primarily suitable for analyzing large data sets where we need to generate long frequent sequences with a low support value. Selecting suitable values of the nSamples and nSamplesToVerify parameters can make the action run in much less time compared to other algorithms and provide us with sufficient frequent sequences as output. The exact methods such as the cspade action should be preferred when the size of the data set is small and/or the length (k) of the sequence is small. In another blog post, we will show an example of how to use the cspade action.
LEARN MORE | SPMF: An Open-Source Data Mining Library






1 Comment
great blog