[Editor's note: this post was co-authored by Marinela Profi and Wilbram Hazejager]
Data science teams are multidisciplinary, each with different skills and technologies of choice. Some of them use SAS, others may have analytical assets already built in Python or R. Let's just say each team is unique.
As part of our Continuous Integration/Continuous Delivery with monthly releases, we are always looking to extend SAS Viya integration capabilities to support open-source users and technology. The goal is to enable all types of users to leverage their best skills, ensuring governance of assets, explainable AI and operationalization of models (ModelOps).
With the October 2021 release of SAS Viya, we introduced the Python Code Editor. Data Scientists and Python programmers can now code, execute and schedule Python scripts from within the SAS code editor interface (SAS Studio) or add Python steps to a SAS Flow quickly and intuitively.
Both options offer Data Scientists the flexibility to:
- use Python inside a SAS environment for query, preparation and analysis depending on users' skills, comfort and preferences, as well as the problem they are trying to solve
- efficiently create a flow to integrate SAS and Python code for consistent delivery of analytics-ready data pipelines
- support Information Governance initiatives by displaying tables created by Python, using SAS linage diagrams
- leverage the benefits of using SAS Viya with open source for achieving business value
This post demonstrates the use of this capability with some simple Python code. You will learn:
- how to create a single program or a flow integrating python code in a SAS environment
- what happens from a high-level architecture perspective
- how to use SAS lineage diagrams to present Python table usage
Getting started
A standard SAS Viya installation does not have Python support enabled, as the environment runs in a lockdown mode, for security purposes. Your Kubernetes and/or SAS Administrator can enable Python support in lockdown mode and configure the default location for the SAS environment. Suffice it to mention here, Python 3.x is supported and you can use any Python package, as long as it is available inside the directory structure that contains Python.exe. Details about these configuration options are described in detail in the section Configure SAS to Run External Languages in the SAS Viya Administration documentation.
Intro to Python Code Editor
The Python Code Editor allows you to write, run, and save Python programs. In the example outlined below, we use data in a SAS table called sashelp.class and apply data transformation using Python. By the way, the SAS table could have been a SAS data set or a DBMS table that is supported via SAS/Access software, which includes support for ODBC and JDBC.
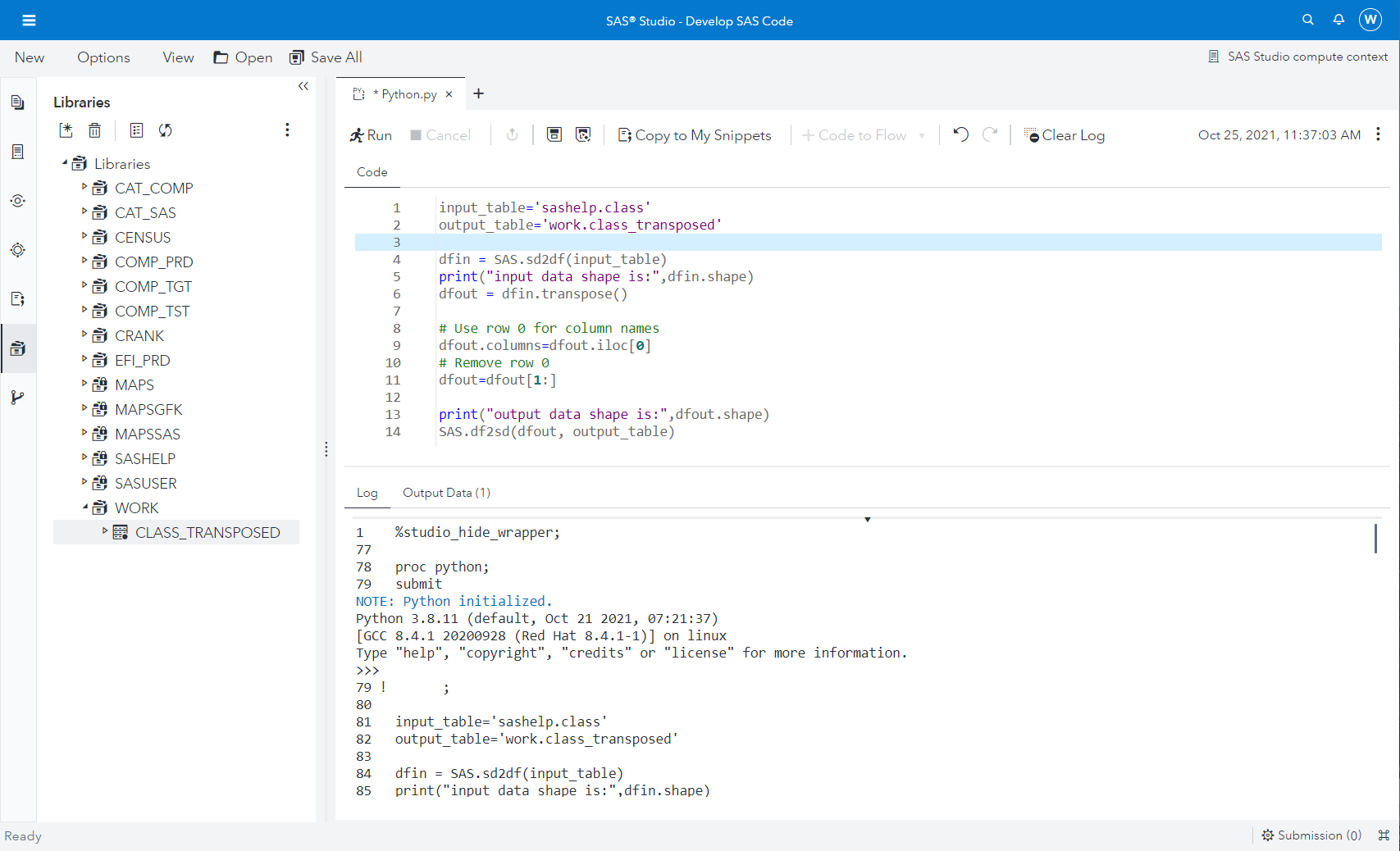
When you run your Python code from the Python Code Editor, SAS Studio runs SAS code invoking the PYTHON Procedure and embeds the Python code in a submit/endsubmit block. This procedure enables running Python statements within SAS code. Considering Figure 1, the Python editor appears similar to the SAS Code Editor; however, notice the Python.py filename, this is Python code! The Code tab is for editing your Python Code and the Log tab displays the executed statements and information from the Python console. When the Python code yields results stored in a SAS table, the table displays in the Output Data tab, where you can interactively browse its content.
The PYTHON procedure
The PYTHON procedure creates a Python subprocess from a SAS Compute Server process and automatically imports the SAS code enabling interaction between SAS and your Python instance. The next section explains this in more detail.
This module provides callback methods enabling variable sharing between Python and SAS (SAS.symget or SAS.symput), move data between SAS data sets and Pandas DataFrames (SAS.sd2df or SAS.df2sd), invoke SAS and FCMP functions (SAS.sasfnc), and submit SAS code within your Python statements (SAS.submit). The documentation for the Python procedure provides examples for each of these.
Using these callback methods, you can create a workflow that mixes SAS and Python programming as needed.
How is the Python code handled at runtime?
What happens when you run your Python program in the SAS coding interface? Let's take an architectural deep dive to explain. The following diagram summarizes what happens when you run a program in the Python Code Editor.
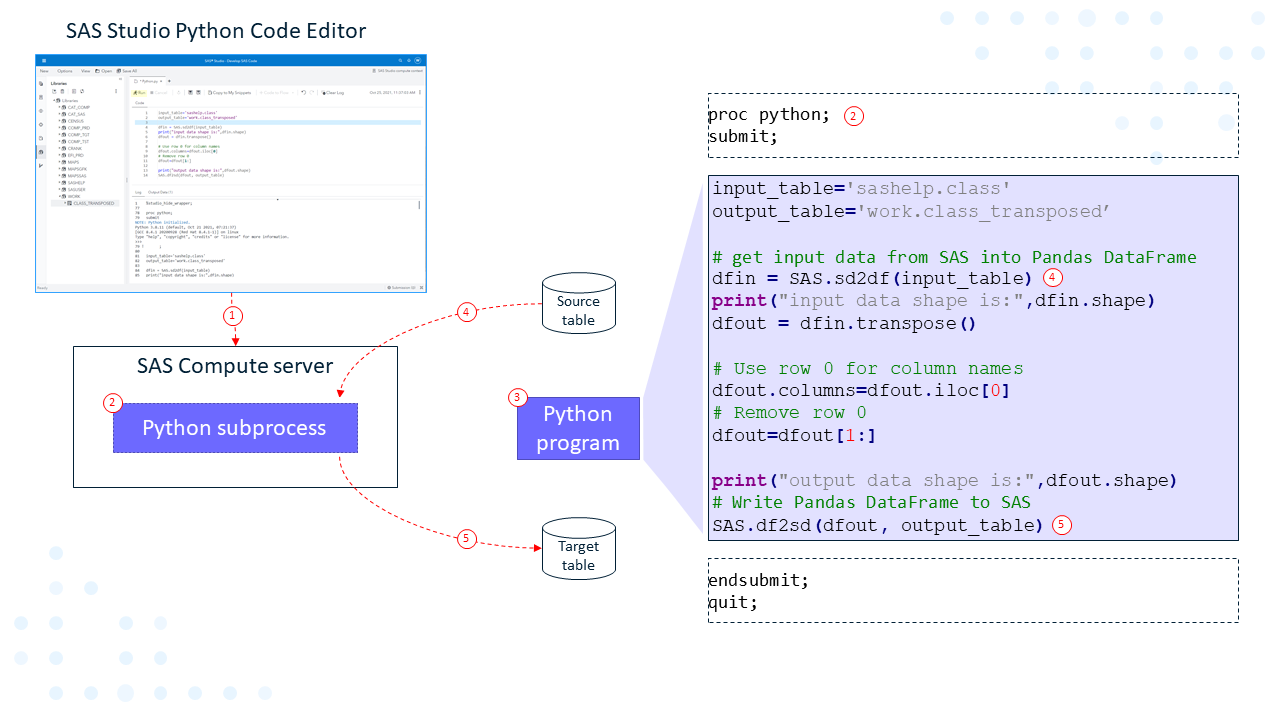
- Run your Python code from the Python Code Editor.
- As SAS Studio works with SAS Compute Server, invoke the Python procedure on the SAS Compute Server, which starts a Python subprocess.
-
The code provided in the code editor is put inside a proc python
submit/endsubmitblock, which executes inside the Python subprocess. - Because the Python code contains a call to the SAS.sd2df() function, the SAS Compute Server reads the specified SAS table, and provides data in the specified Pandas DataFrame.
- The sample code issues a SAS.df2sd() call transfering the results from a Pandas DataFrame back into a SAS table.
The sample Python code contains some statements calling a few Pandas functions, but you could use any available Python package in the Python directory configured by your SAS Administrator.
Integrating Python steps with SAS steps in a flow
Now that we have developed and tested our Python code, we are going to embed it in a Studio Flow. This allows us to combine Python code and standard data transformation functionality in SAS Studio Flow. Moreover, we can view and define the data transformation using a graphical flow with a mix of SAS and Python transformations. And finally, we can easily schedule the flow.
In the next example, we modify the Python code so it contains no hardcoded table references. Instead, it uses tables connected to the input and output ports of the step.
In the following flow, we have dropped a Python Program step onto the canvas and connected tables representing the input and output tables. The table steps contain information about data location. Note that those table steps could represent a SAS data set but could also be a table that lives in a DBMS system.
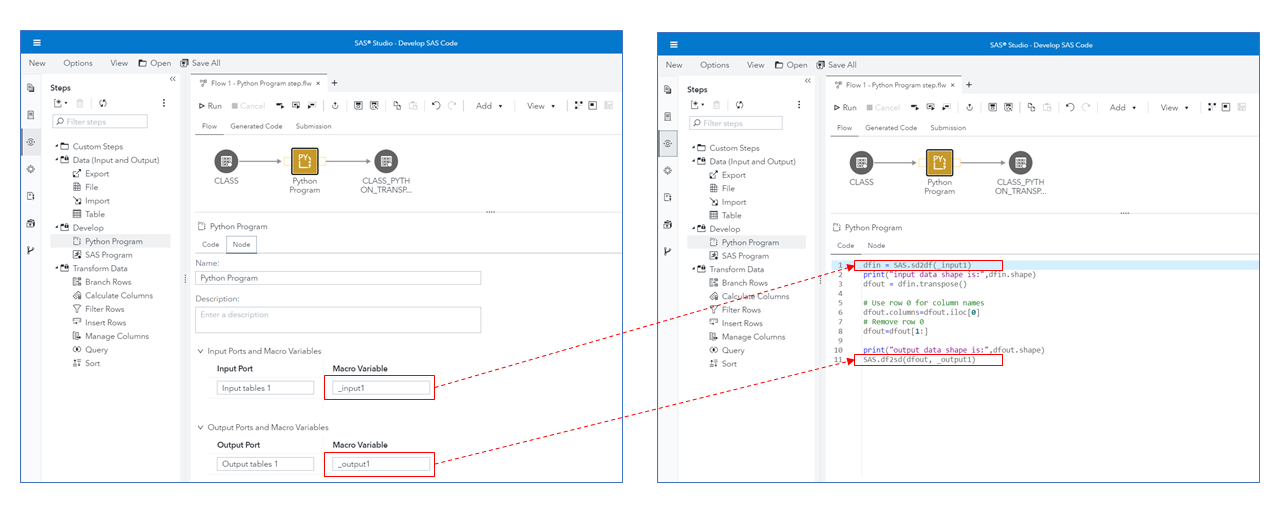
The Python Program step supports input and output ports (not networking ports!) and each has an associated variable representing the name of the table connected to that port. The user can overwrite the names of these ports.
Note: The Python Program step has a single input and output port by default, but you can add and remove ports using the popup menu.
When we run the flow, the code framework generates code for each step in the flow. For the Python Program step, it also creates Python variables, _input1 and _output1, which contain the name of the connected table using SAS table reference syntax libref.tablename.
Just like we observed previously with the Python Code Editor, the Python Program step invokes proc python SAS code and the native Python code provided in the Code tab of the step, and is embedded inside a submit/endsubmit block.
As a result, the generated code for the Python Program step, using input and output ports in Python code from Figure 3, looks like this:
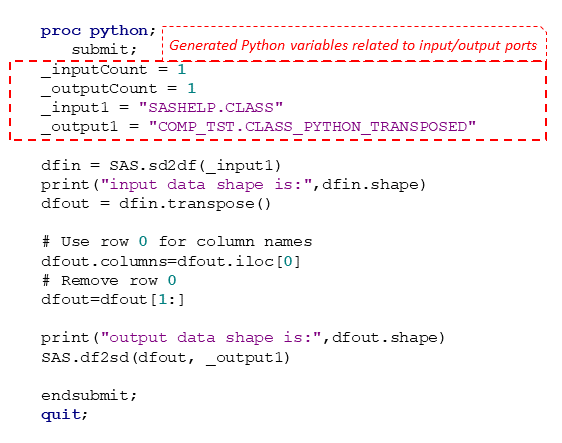
This code is visible in the Generated Code tab in Studio Flow.
Now that we have embedded our code in a Python Program step in Studio Flow, we can change the properties of the input and output Table steps and point to a different table. The Python code uses the name changes when we run the flow interactively. If your data requires pre- or post-processing, you can add additional steps in the flow.
In the example below, we added a Query step to join data from an additional source using an inner-join and applied a filter. We also change the properties of the Table step by adjusting the name of the table where we store the results of the Python processing.
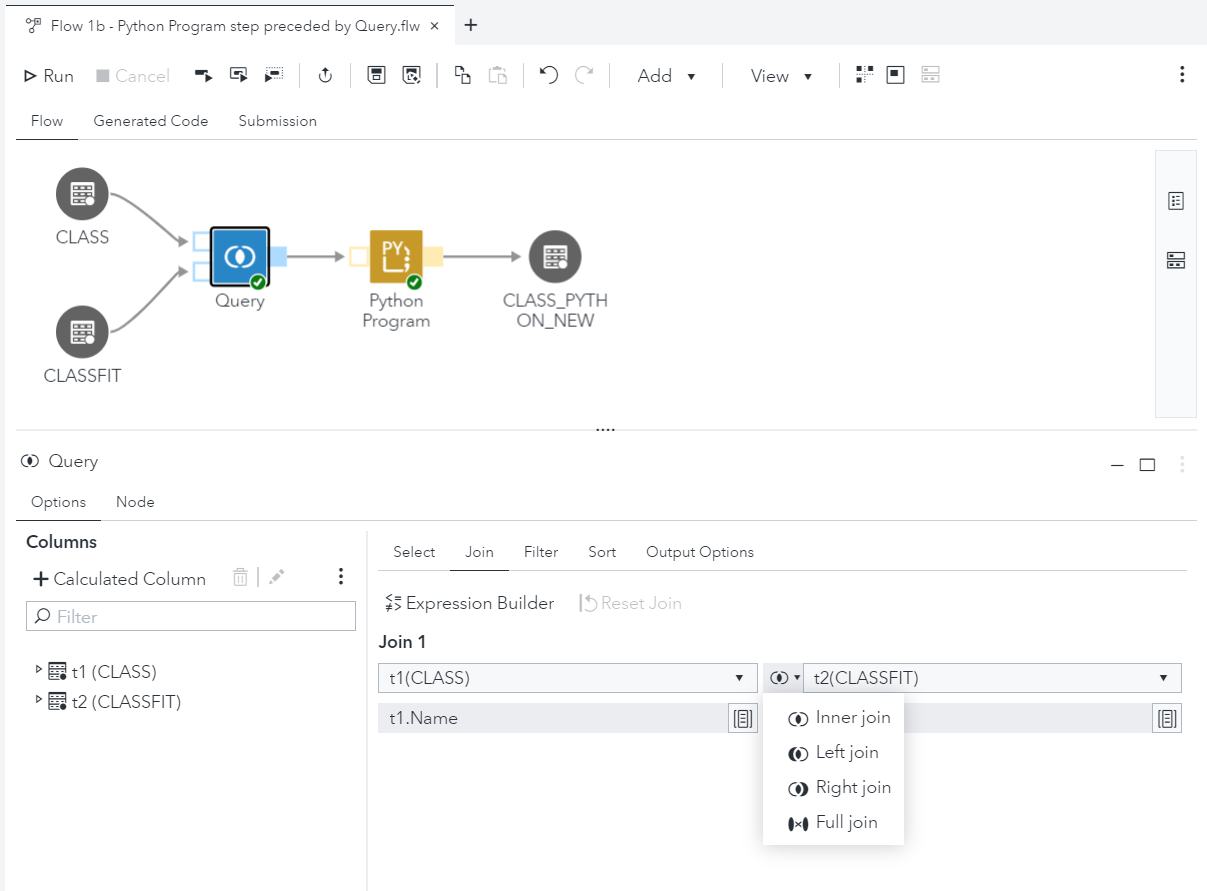
The flow is now complete and the green tick-marks on each of the transformation steps indicate the steps ran successfully.
How to keep an overview of which tables are used where?
Thus far we have created a single Studio Flow with steps that work on input tables and create output tables. When you have multiple flows, perhaps created by other users in the environment, and some of these flows use tables created/updated by our flow, how do you keep an overview of which tables were used where? This is where SAS Lineage Viewer comes into play.
So, let’s assume another user creates a flow that uses our output table to perform some further data transformations creating another table. How would we know about this?
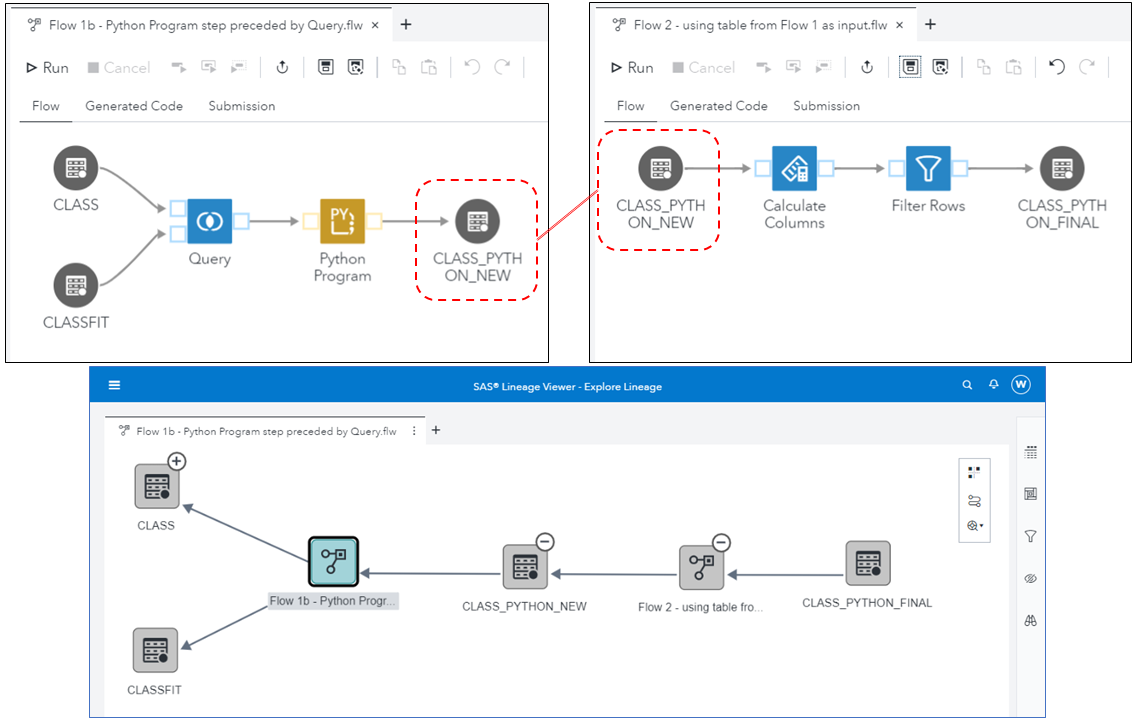
The lineage diagram above shows the CLASS and CLASSFIT tables are inputs in Flow 1b and this flow wrote data into table CLASS_PYTHON_NEW. In Flow 2, the table is input, and the flow writes data into table CLASS_PYTHON_FINAL.
This definition of each flow is known to SAS Lineage Viewer and we searched it for our flow, called Flow 1b. The result shows a diagram with all input and output tables. And if a table is used somewhere else, it has a (+) icon. In our example, by expanding the CLASS_PYTHON_NEW table, the diagram shows use by Flow 2.
By using SAS Lineage Viewer, you can quickly see which tables are used where, even when your Studio Flows contain Python Program steps.
Wrapping things up
This Python code editor allows programmers and data scientists to code, execute and schedule Python scripts. The functionality is available from within the code editor interface in SAS Studio or by adding Python steps to or program in a SAS Studio Flow. In either case, it offers flexibility to use Python or SAS for query, preparation, and analysis depending on user's skills, comfort and preference, and problem they are trying to solve. You can now create a single program or flow to integrate code. Additionally, use steps and nodes from SAS and Python code for consistent delivery of analytics and ready data pipelines in a productive, efficient manner. In this post we introduced the module and how to get started, how it works, and the architecture behind it.
Learn more
SAS integrates with open source in every step of the analytics life cycle. Users can learn more about how SAS works with open source by downloading the eBook, “Drive Analytic Innovation Through SAS and Open Source Integration” and by visiting developer.sas.com.
We have also developed specific packages available on Github and supported by SAS R&D: SASPy and SWAT, both aimed at a Python programmer wanting to use functionality available on a SAS server from their Python client environment.
About the co-author
Wilbram Hazejager - Principal Systems Architect
Wilbram Hazejager is a principal systems architect for data management products at SAS. He has been involved for many years in SAS’ data management products in various roles, including product management, working closely with customers, and authoring a number of papers on SAS data management products. He holds a Master of Science degree in Applied Mathematics from the Eindhoven University of Technology in the Netherlands.

2 Comments
Is it available in SAS onDemand for Academic?
When I graduated many moons ago, there were engineers telling my "why did you learn SAS" there is going to be an open source coding language that will change the world and get rid of SAS. No it was not R, it was SQL. SQL did amazing things, and SAS integrated it into its system and the company became a force for using SQL and analytics together. I am hopeful that history can repeat itself here. It has take us a little longer than I would have liked, but this looks great. As with SQL you saw the move to BI platforms. We are seeing this already with AI too! and with the integration of SAS and Python ...this makes for an amazing AI platform. Really excited.