
Note from Gül Ege Sr. Director, Analytics R&D, IoT: The pattern of training in the Cloud, with your choices of framework and inferencing at the Edge with a target environment, are especially common in Internet of Things (IoT). In IoT, there is a proliferation of hardware environments on the Edge. SAS and Microsoft are collaborating around ONNX Runtime. The goal is for developers and systems integrators to have the deployment flexibility they need to train deep learning models using a variety of frameworks. As well, they can seamlessly deploy on a variety of hardware platforms. Supporting diverse hardware environments is critical. Allen Langlois, Daniele Cazzari, Shunping Huang, and Saurabh Mishra from SAS IoT and Pranav Sharma and Ryan Hill from Microsoft explain why this collaboration is so important to the developer community.
Authors: Allen Langlois, Daniele Cazzari, Shunping Huang, and Saurabh Mishra from SAS IoT
Pranav Sharma and Ryan Hill from Microsoft
Artificial Intelligence (AI) developers enjoy the flexibility of choosing a model training framework of their choice. This includes both open-source frameworks as well as vendor-specific ones. While this is great for innovation, it does introduce the challenge of operationalization across different hardware platforms. It’s a massive build and maintenance ask to adapt to individual target environments given runtime dependencies, libraries, drivers, and specific packaging requirements. This problem gets compounded with the growing trend to perform inferencing at the Edge, given the variety of Edge environments.
But now, SAS and Microsoft are collaborating around ONNX Runtime (ORT). This is so developers and systems integrators have the deployment flexibility they need to train deep learning models using a variety of frameworks and to seamlessly deploy on a variety of hardware platforms.
This pattern of training in the Cloud with a framework of your choice and inferencing at the Edge with a target environment of your choice is especially common in Internet of Things (IoT). This is where there is a proliferation of hardware environments on the Edge. Supporting this diverse hardware environment is critical. It's why the collaboration between the SAS IoT team and the ONNX Runtime team at Microsoft is so important to the developer community. Together, we’re creating a solution that makes “train with any framework and inference in any Edge or Cloud environment” a reality.
SAS Event Stream Processing integration with ONNX runtime
SAS Event Stream Processing (ESP), is a high-performance streaming analytics platform designed to apply analytic processing to a live stream of data to produce real-time results for low latency actions. At the core of this platform is the ESP server, the versatile runtime that allows operationalization of AI and machine learning (ML) models against streaming data. The prospect of native support for ONNX Runtime from the SAS ESP server allows developers to use a broad range of readily accessible models. As well as leverage the SAS ESP developer framework for rich workflow support.
In many scenarios, additional developer support is needed for inferencing with Deep Learning models to maximize benefits for the developer and address the challenges of deployment. Models, like YOLO and OpenPose, for example, require a scoring process flow that includes pre-and post-processing logic, along with the inferencing, to prepare or render results for other applications. SAS ESP’s developer framework facilitates this scoring process flow by enabling the user to design a full end-to-end pipeline.
A pipeline typically starts with data ingestion, with inputs that range from camera frames to streaming sensors values, etc. It also includes an input transformation stage to support common operations, such as resizing or normalizing the input data to fulfill an algorithm’s preprocessing requirements. Once the ONNX layer is complete, the post-processing typically requires an output transformation block that is an extensible collection of post-processing routines that convert ONNX output into processable information, such as a bounding box or body part coordinates in object detection and classification scenarios.
This process flow could also be expanded, allowing the combination of multiple models for different scenarios. For example, developers could run a face detection model and then provide the detected faces to another model trained to detect emotions. It is also possible to track different input sources, like sensors, in parallel and combine the results to understand the likelihood that a complex process will fail such as a complex factory production line.
ONNX Runtime and Execution Providers
ONNX Runtime technology plays an important role in this process to meet the challenges associated with putting these models into production. It's an open-source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms. Its library, built with different execution providers, enables developers to use the same application code to execute inferencing on different hardware accelerators, for example, Intel GPU or NVIDIA GPUs.
The Execution Provider (EP) interface in ONNX Runtime enables easy integration with different hardware accelerators. There are published packages available for x86_64/amd64 and aarch64 or developers can build from source for any custom configuration. This flexibility enables developers to create an optimized package for ONNX Runtime to be used across the diverse set of Edge devices and scoring accelerators available in the Cloud. This package supports the same APIs for the application code to manage and execute the inference sessions.
The collaboration between SAS and Microsoft will also support different execution providers to be bundled in the same build package, which will enable the same library to be used on different platforms and would alleviate the need to build and maintain separate packages. This greatly simplifies the process of deploying models for execution on various hardware platforms both on the Edge and in the Cloud.
As shown in Figure 1, SAS is leveraging the streaming analytic plug-in feature of SAS ESP to support ONNX scoring. Specifically, SAS built an ESP plugin-in that serves as a bridge between ESP server and ONNX Runtime. This plug-in will load the ONNX Runtime library dynamically. Then it will call the APIs to load an ONNX model and score it with the input tensors received from the previous pre-processing step. When the scoring is done, the plug-in will retrieve the output tensors from ONNX Runtime and then send them back to the ESP server for post-processing. We also surface a few useful options from ONNX Runtime to the plug-in. This includes execution provider settings, logging levels, etc., which can allow customers to better control the behavior of ONNX scoring.
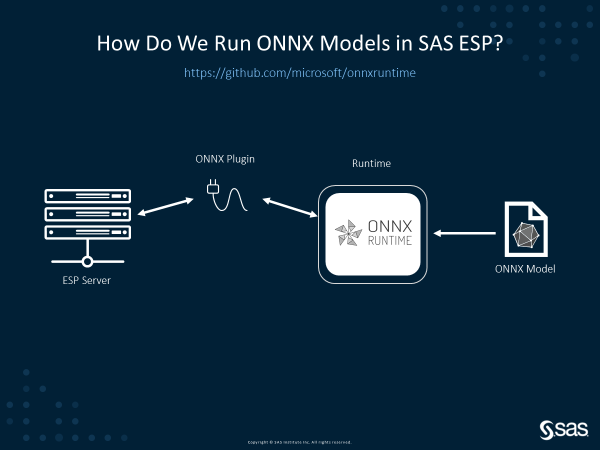
Dynamic loading with ONNX Runtime Execution Providers
Before this feature was introduced, EPs were tightly coupled with ORT core and this coupling necessitated linking the EP statically with ORT core, which forced a dependency between ORT and the EP even if the EP was not used at runtime. Dynamic EP loading eliminates this tight coupling by introducing a new abstraction that EPs will program against. This abstraction sits between ORT core and the EPs. It is implemented in terms of a header file whose implementation is provided by ORT core. This allows ORT to load an EP dynamically without incurring the cost of setting up unnecessary dependencies. The result is flexible deployments across heterogenous environments with less coding for each execution provider.
Details about the abstractions used and other information about this implementation can be found here.
How it works
Previously, ONNX Runtime would be built as a single library, for example on Windows: onnxruntime.dll. If it was built with a provider like CUDA, the CUDA provider code would be built as a part of this library. In this case, onnxruntime.dll now has the CUDA provider. But it also depends on the CUDA system libraries as the onnxruntime.dll now has the dependencies of the CUDA provider. The same applies to any other shared providers.
With the new shared providers, CUDA is now built as a separate library: onnxruntime_providers_cuda.dll. Only this library depends on the CUDA system libraries. If a user of onnxruntime requests using the CUDA provider, then onnxruntime will dynamically load onnxruntime_providers_cuda.dll (and report an error if it can’t be loaded).
Internally, onnxruntime_providers_cuda.dll accesses all of the core onnxruntime.dll functionality it used to access directly through a C++ interface. And compiles using a header file that makes this interface look almost exactly like the original internal classes (to minimize code changes in the providers). By doing it this way, the ONNX Runtime library can still be built as a static library vs a shared one, as a shared provider depends on this interface, not onnxruntime.dll itself.
Summary of the SAS and Microsoft Collaboration
SAS and Microsoft’s collaboration changes the game for developers and systems integrators with capabilities that deliver benefits including:
- The flexibility of targeting multiple hardware platforms for the same AI models without additional bundling and packaging changes. This is crucial considering the additional build and test effort saved on an ongoing basis.
- Leveraging hardware acceleration which is fully accessible by targeting a hardware platform.
- Supporting flexible developer pipelines with a mix of models and input sources for complex use case scenarios. As mentioned earlier, some use cases are complex by nature. They might require handling of multiple input types and may require several models stitched together to realize the pipeline. This approach offers the ultimate flexibility to fully embrace such scenarios.
To learn more about how you can simplify your development pipeline and streamline deployment for Edge and Cloud, contact us at esp@sas.com or visit www.microsoft.com.
Learn More | ONNX Runtime Learn More | SAS Event Stream Processing





