
The first principle of analytics is about bringing the right analytics technology to the right place at the right time. Whether your data are on-premises, in the cloud, or at the edges of the network – analytics needs to be there with it. Being true to this principle means we need to make sure that our algorithms exploit computational resources in the most optimal fashion.
Regardless of how you store your data or how much there is, the goal is to build powerful analytical models using that data to provide answers quickly for better decision making. Today I'm fortunate to talk to Josh Griffin, a Senior Manager in Analytics R&D, about how we accomplish parallelization and optimal computation in SAS software.
Meet Josh Griffin
 Udo: Josh, you and your team are working on optimization routines, performance considerations, and parallelization of our software stack. Tell us a little bit about yourself and your responsibility at SAS.
Udo: Josh, you and your team are working on optimization routines, performance considerations, and parallelization of our software stack. Tell us a little bit about yourself and your responsibility at SAS.
Josh: My background before coming to SAS was in large-scale nonlinear nonconvex optimization and in derivative-free optimization. The former tends to come in to play when doing things like training machine learning models, while the latter is critical for modern auto-tuning algorithms. Currently, my team and I work on building and maintaining many supporting routines ultimately surfaced in SAS statistical and machine learning products.
I believe that ultimately, all analytics vector to some specific optimization problem class. If that problem happens to be nonlinear and/or nonconvex, my team can help. In addition to nonlinear, my team also has experts in linear algebra. This is key as arguably all optimization further reduces to a series of linear algebra operations. How fast these operations can be executed plays a pivotal role in how fast the optimization and analytics can be performed. And of course, we very interested in exploiting available cloud architecture. We want to make maximal use of available worker nodes, CPU's, GPU's, minimizing cache misses and memory transfers, etc.
It is critical to consider and tailor code to modern architectures that we expect customers to have now or one day. Like a symphony, high-speed analytics needs all of these components synchronized and in harmony to do what we call "light up the grid". Meaning, make optimal use of the customer's cloud resource by stepping up to this boundary without overprescribing/locking out any one node. I will admit this is tricky.
Over half of my team has had calls from our grid admin for "lighting up the grid" too long or too aggressively. As much as I like to keep our grid admin happy, I am proud my team knows how to do this. Just because a customer gives a routine 100 worker nodes doesn't mean that routine can use them. My team clearly can. So it is a bit of a balancing act, but thoroughly fun, like solving a never-ending stream of really challenging puzzles.
Will AI and smart machines take over the world?
Udo: We have heard so much about AI and smart machines taking on the world. What’s your take on such claims?
Josh: Current AI approaches are all based on machine learning. Under the surface, machine learning models are found using various optimization routines. Thus models can be found more readily if you can parallelize these routines while leveraging new GPU and CPU chip architectures. Modern AI has indeed accomplished feats that are seemingly impossible. Part of the AI revolution comes from breakthrough theory and methods. Still, almost all of these methods would be hypothetical without the power that new chip architectures and cloud computing offer.
One of the most popular machine learning methods today, stochastic gradient descent (SGD), is around 70 years old. It was one of the simplest algorithms to describe and trivial to implement sequentially from an optimization perspective. Why is it so popular now? SGD beats more intricate optimization methods in part because modern cloud computing environments are very friendly to SGD iterations. This allows the algorithm to iterate remarkably quickly. Note that when moving from sequential SGD to parallel, its simplicity is utterly lost. Making it work well in parallel is like being a symphony conductor. A lot of different elements must work harmoniously together.
I completely agree with Jensen Huang's 2017 quote, "Software is eating the world, but AI is going to eat software." I think it is already doing so, but not in the way people think.
I had a mentor in undergraduate school once say to a fellow student frustrated by one of the coding exercises, "Computers do not do what you want them to; they do [exactly]what you tell them to." In a way, machine learning is changing that. For example, I can mistype every word in a search query and obtain identical results compared to perfect grammar and spelling. The underlying machine algorithm is very good at guessing my intentions. I guarantee you that the computer is still doing exactly what the developers told it.
So for me, Jensen’s quote simply means that future developers will be using AI to create powerful new products. Thus without an intimate knowledge of modern machine learning tools, developers will ultimately be left behind. Much like how the automobile started as a fantastic invention, but now we drive it daily without a thought.
How does cloud computing help our customers?
Udo: We learned from an earlier post that cloud computing accelerates transformation. How do we make sure that our customers and users can take advantage of most modern architectures?
Josh: Having been at SAS for over a decade, I was a developer when our exciting transformation to fully distributed computing began. Since those days, we have worked very hard to ensure our software runs universally in modern cloud computing environments. We continually seek new and innovative ways to fully leverage the allotted cloud-computing resource. In the early days, distributed computing was a niche area, relevant to an elite subgroup of well-funded university departments, national labs, and large-cap companies who had access to private compute clusters.
The advent of cloud computing has genuinely democratized distributed computing, making it available to almost anyone. There is, of course, an inherent time-based cost now with cloud computing resources. Users no longer necessarily pay a one-time fee and then own the resources indefinitely. Now they may "rent" computing power for a transient amount of time. In the old days, you wanted to reduce run time to make the customer happy. Now reducing run time saves the customer actual dollars. That is, the faster you run, the more efficiently you run … this also translates into cost reduction. The advent of modern cloud computing architectures opens the door for everyone to benefit. SAS developers have worked extremely hard in recent years to ensure our users can leverage these same opportunities.
Can't divide the cake? Stack the cake
Udo: SAS has invested quite some efforts in the parallelization of our algorithms. Can you share some insights on how we go about this?
Josh: I love working in the world of distributed and threaded computing – both the challenges and the possibilities. But I feel it is a mistake to think cloud computing and big data are conjoined entities. Yes, cloud computing is an excellent answer to big data, but it is also a perfect coupling with small data. It is easy to get tunnel vision. It can take a lot of effort to change the way you think and be open to new algorithms and ways of doing things. Indeed, there are only so many ways to slice a cake before it becomes impractical to divide calculations further. And of course, certain calculations are inherently sequential and thus cannot be computed simultaneously.
This circles back to the concept of tunnel vision; most problems we solve do not live in a vacuum. They are not solved as an end in itself (as developers, we can forget this). They typically are part of a larger analysis pipeline. Cloud computing enables you to solve many variants of the pipeline in parallel to find what works best. That is if you cannot divide the cake any further, stack the cake. You can parallelize job stacking very efficiently.
For example, a customer has a small data statistic problem to solve. Our analytics and statistic products come equipped with a lot of flexibility on how to explore data. What combinations are best? In the past, it was the user's job to find the needle in the haystack manually. We now have tools that can automate this search for them and do this all in parallel.
So I would say the biggest effort is learning to look at the world of analytics through a separate lens. Once you do, you can see parallelism and cloud computing opportunities everywhere, regardless of data size or problem type. Of course, it takes effort to make these opportunities a reality, but that is the fun part for developers.
The biggest effort is learning to look at the world of analytics through a separate lens. Once you do, you can see parallelism and cloud computing opportunities everywhere, regardless of data size or problem type. Share on XUnsolvable problems from the past solved today
Udo: Can you provide some examples of problems we can solve today, which were unthinkable some years ago?
Josh: Two examples pop into my head. The first was when I solved my first support-vector machines (SVM) problem to global optimality with more than 2.2 billion observations spanning over a terabyte of data. We could handle many more observations than this, but the 2.2 threshold is special. Internally, data dimensions are often stored as int's. The largest int is 2,147,483,647. I always held my breath when making the jump from 2 billion observations to 3 billion. When we passed this threshold, I breathed a sigh of relief.
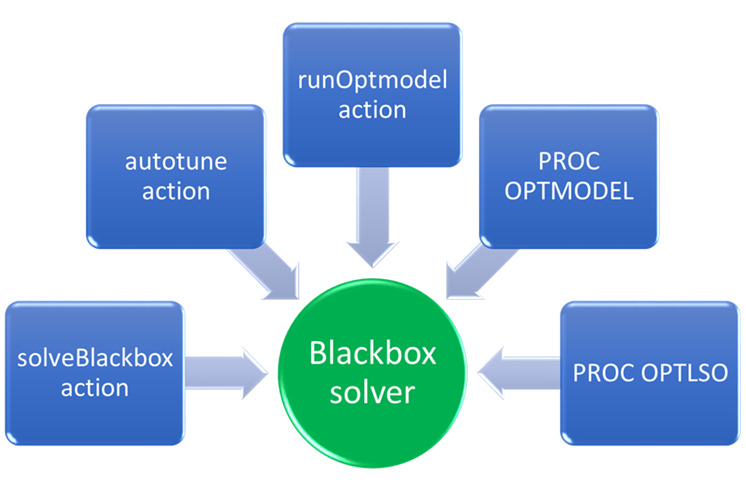
Of course, there is traffic on blogs arguing just because you can solve a problem on that scale to arbitrary accuracy, should you? Maybe with better models and data processing, smaller samples of the data work just as well. As a developer, it is my job to be ready for whatever sized problems the customer throws at me. This brings me to my second example, of which I am still excited. My team recently developed an action called solveBlackbox. No matter what size data problem you are solving, this tool makes the cloud computing environment an exciting option.
It is a tool that I dreamed about creating for several years at SAS. SAS Viya opened the door for this dream to become a reality. Though we just released this action, I have been testing a prototype for several years now. Like a Swiss Army knife, it is a tool I find a use for wherever I go. A lot of what a data scientist and analyst do is trial and error, trying many combinations of options and ideas to finding what works best. Rather than you spending your weekend sifting through a haystack of possibilities, SAS can automate this process for you as well as search asynchronously using multiple levels of parallelism.
 I've read that Thomas Edison tested thousands of different materials before finding a stable material for the light bulb. I imagine the idea of the light bulb and the physics behind it required a revolutionary mind like Edison. But performing thousands of repetitive experiments manually would be a waste of his time and talent. How awesome would it have been if he could have flipped a switch, gone away for the weekend, and return to a table of all the thousands of tests and their results?
I've read that Thomas Edison tested thousands of different materials before finding a stable material for the light bulb. I imagine the idea of the light bulb and the physics behind it required a revolutionary mind like Edison. But performing thousands of repetitive experiments manually would be a waste of his time and talent. How awesome would it have been if he could have flipped a switch, gone away for the weekend, and return to a table of all the thousands of tests and their results?
I think it will be some time before users fully grasp the scope of the power they now have available at the fingertips. The solveBlackbox action is just one small example of what SAS can now do for our users.
Rather than you spending your weekend sifting through a haystack of possibilities, SAS can automate this process for you as well as search asynchronously using multiple levels of parallelism. Share on XFuture of SAS and the cloud
Udo: SAS is moving towards to cloud. What does the future hold for you and your team?
Josh: When it comes to research and development, I often think of the Ouroboros, the snake eating itself which symbolizes eternal cyclic renewal. It perfectly captures how the world of software works. We create new and exciting tools for our customers. Then we realize that a tool can be used as a base to create a new product. I often think about how today's tools might be used as stepping stones to build new and innovative products for our customers. Each new product may open a door previously thought shut. In the past, you would hit a computational limit of what you could do on one computer. Now with the cloud at our disposal, almost anything is possible to reconsider.
One goal I have is simplifying the customer's life through automation. The cloud creates the opportunity to explore more potential cases in parallel. The mere fact of making these cases creates new metadata sets that we can use to detect patterns and find new solutions. AI opens exciting doors to learn and then automate the boring repetitive components of our jobs. This free us to focus on the part of the problem that requires innovation and creativity.
Part of the reason I became a manager was so I could have more involvement in the different areas of work that our awesome SAS developers do each day. All of these pieces fit nicely together when viewed from the perspective of the cloud computing architecture. SAS is unique in that we have more than 40 years of analytic computing expertise legacy all positioned together in one unique ecosystem. We have all the pieces to solve any problem we might encounter on the cloud. I look forward to putting more and more of these puzzle pieces together.
Udo: Many thanks for all that you do for SAS, our customers, and our partners. Keep up the great work.
This is the fifth post in our series about statistics and analytics bringing peace of mind during the pandemic.
