This is the second post in the series co-authored with Austin Cook focused on operationalizing text analytics with SAS.
In the preceding post, we introduced the Text Investigation Framework and the unstructured data challenges it solves. The Text Investigation Framework utilizes several technologies built on SAS Viya, providing a well-integrated and open solution for operationalizing text analytics. As a follow-up to our last post, we will discuss a key application of the framework relevant to customers of all industries – monitoring customer complaints.
Monitoring Customer Complaints for Financial Institutions
Financial institutions are supervised by numerous regulatory and governing bodies - the U.S. Securities and Exchange Commission, the Office of the Comptroller of the Currency, the Consumer Financial Protection Bureau, and the Federal Deposit Insurance Corporation, among others - that hold them accountable to certain requirements and restrictions. These governing bodies leverage complaints against financial institutions to identify industry trends, halt unfair business practices, and drive enforcement actions when obstructions are identified. Financial institutions with an effective monitoring program for their complaints can identify problematic trends and quickly remediate issues. This will ultimately provide a better experience for customers and reduce their risk for regulator enforcement actions.
The Text Investigation Framework is a flexible solution for addressing text challenges across several domains. We have identified three potential use cases specifically for monitoring customer complaints. In the first use case, we examine complaints that have a high risk of non-compliance with regulatory guidelines and could result in an enforcement action. The second use case audits category model results to provide feedback and improve these models. In the final use case, we examine trending topics and categories that could be indicators for potential issues to come. To demonstrate this, we built a customer monitoring program using data from the Consumer Financial Protection Bureau’s open database. We start with the home page, where our investigator can see the applicable alerts.
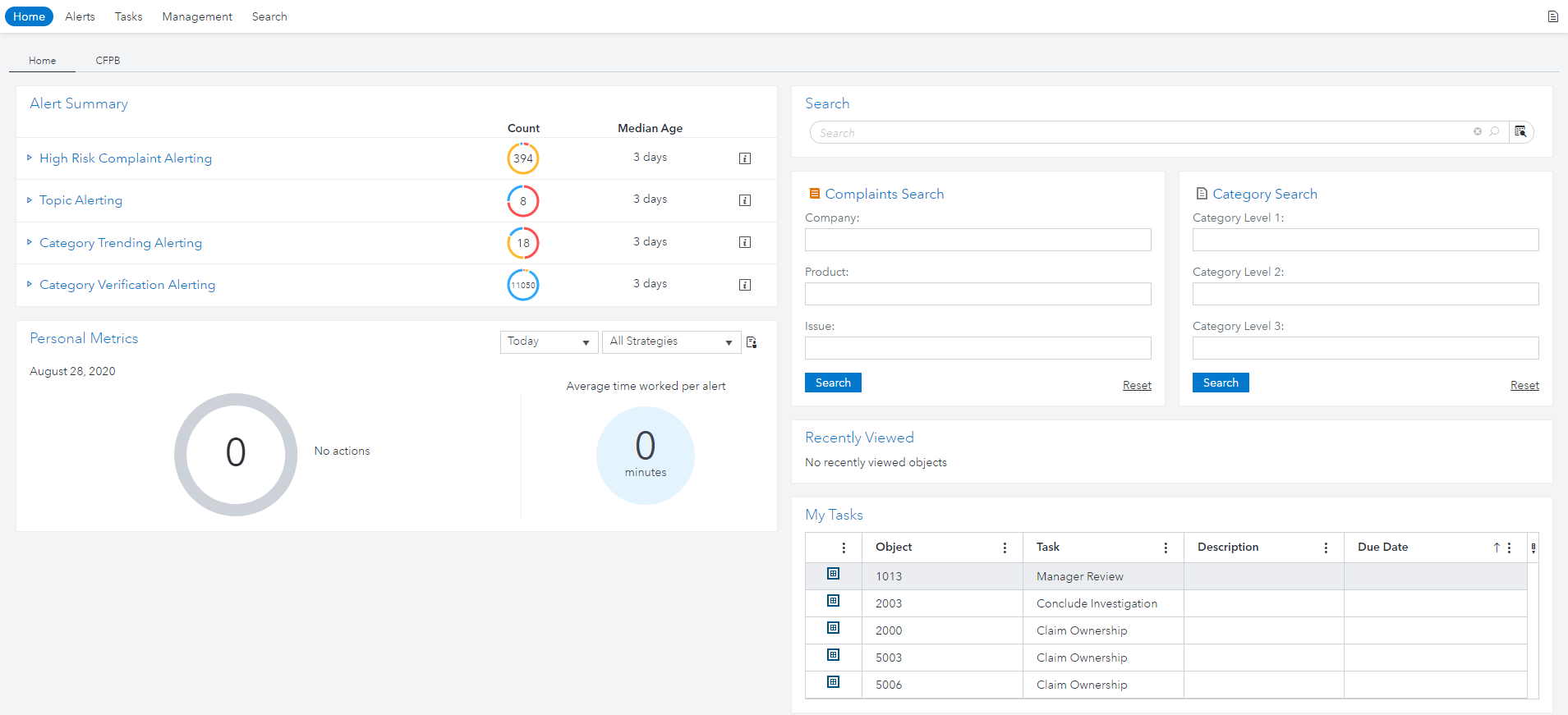
High Risk Alerting
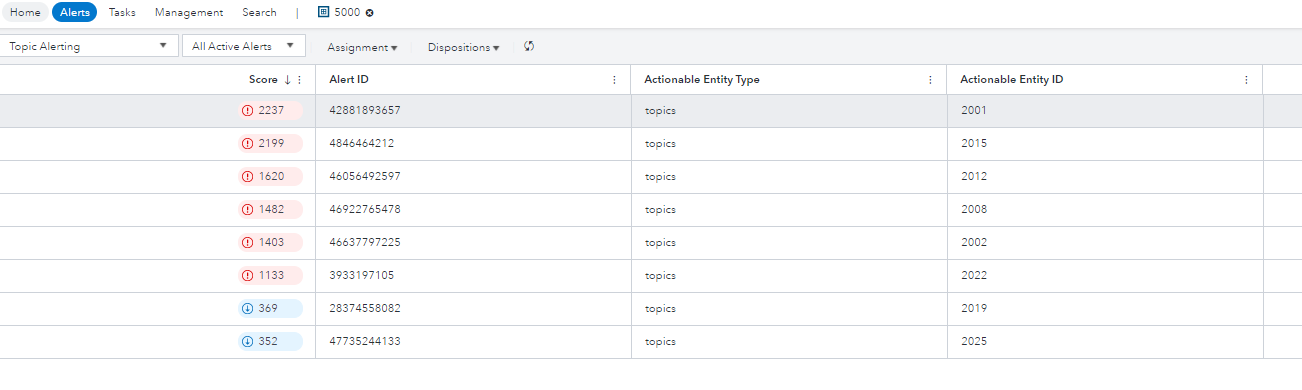
Using text analytics and machine learning, we built models that can help predict complaints that are likely a result of non-compliance to one or more regulations. Furthermore, these complaints could result in an enforcement action. By addressing these complaints early, we hope to correct business practices. This helps prevent or reduce legal and reputational ramifications. We created an alert scenario to trigger alerts for complaints that had a risk probability greater than 60% and applied a corresponding risk score for rank order.
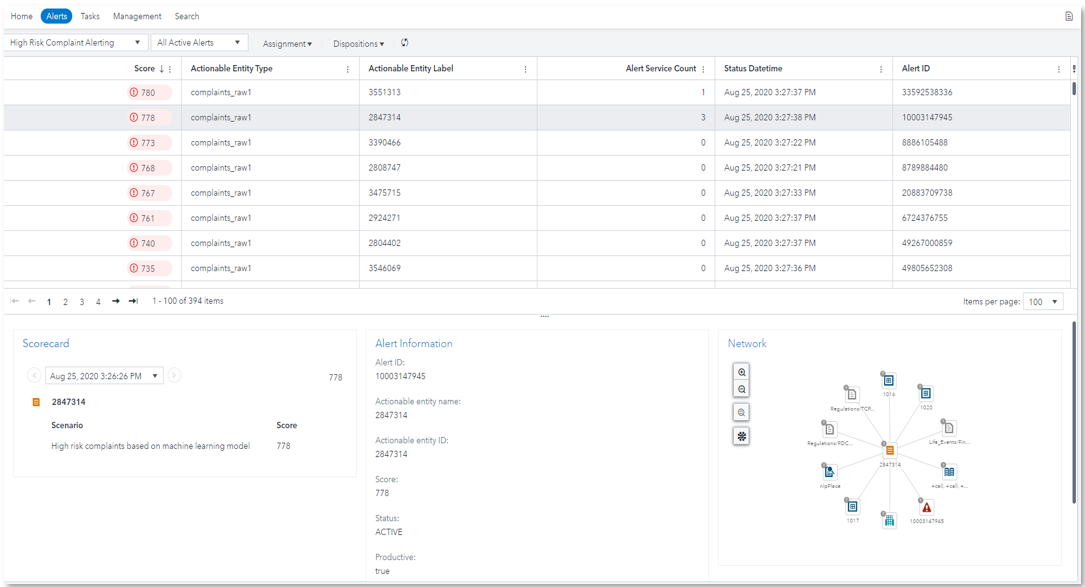
Clicking into an alert allows us to explore the complaint and all NLP-derived information such as topics, categories, sentiment, and concepts in greater detail. This allows investigators to follow the breadcrumbs as they gather more illuminating information. The alert above references a complaint that triggers several regulatory category flags including those referencing bankruptcy collection and abusive calls. When examining the complaint in more detail, we see that this consumer has been called 79 times. In short, this is indicative of a potential lapse in proper business practices.
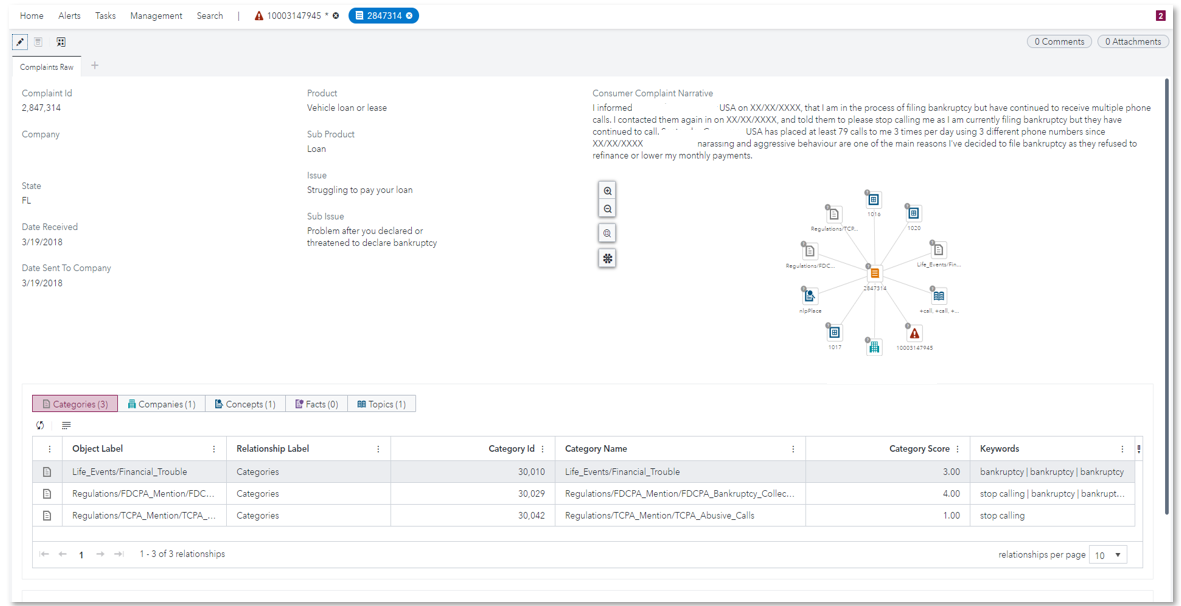
Using the workflow capabilities in the solution, a defined process can be utilized to ensure that this information gets to the appropriate parties. This workflow process can be customized to an organization’s needs and mapped to its internal audit and control efforts. In our example, the investigator will mark the alerts as compliant or potentially non-compliant. Non-compliant complaints are passed to a manager for escalation and remediation. We also added a quality control audit for compliant complaints to catch any false-negatives from investigators. From this example, we see how our Text Investigation Framework prioritizes risky complaints, allowing investigators to quickly find non-compliant complaints to alert the appropriate parties for immediate action before regulatory enforcement is necessary.
Category Auditing and Validation
Unlike predictive modeling or classification problems, text analytics can be subjective. Improving text models requires human feedback. To create a process for incorporating feedback into text models, we started by taking a sample of the categories and complaints for alerting.
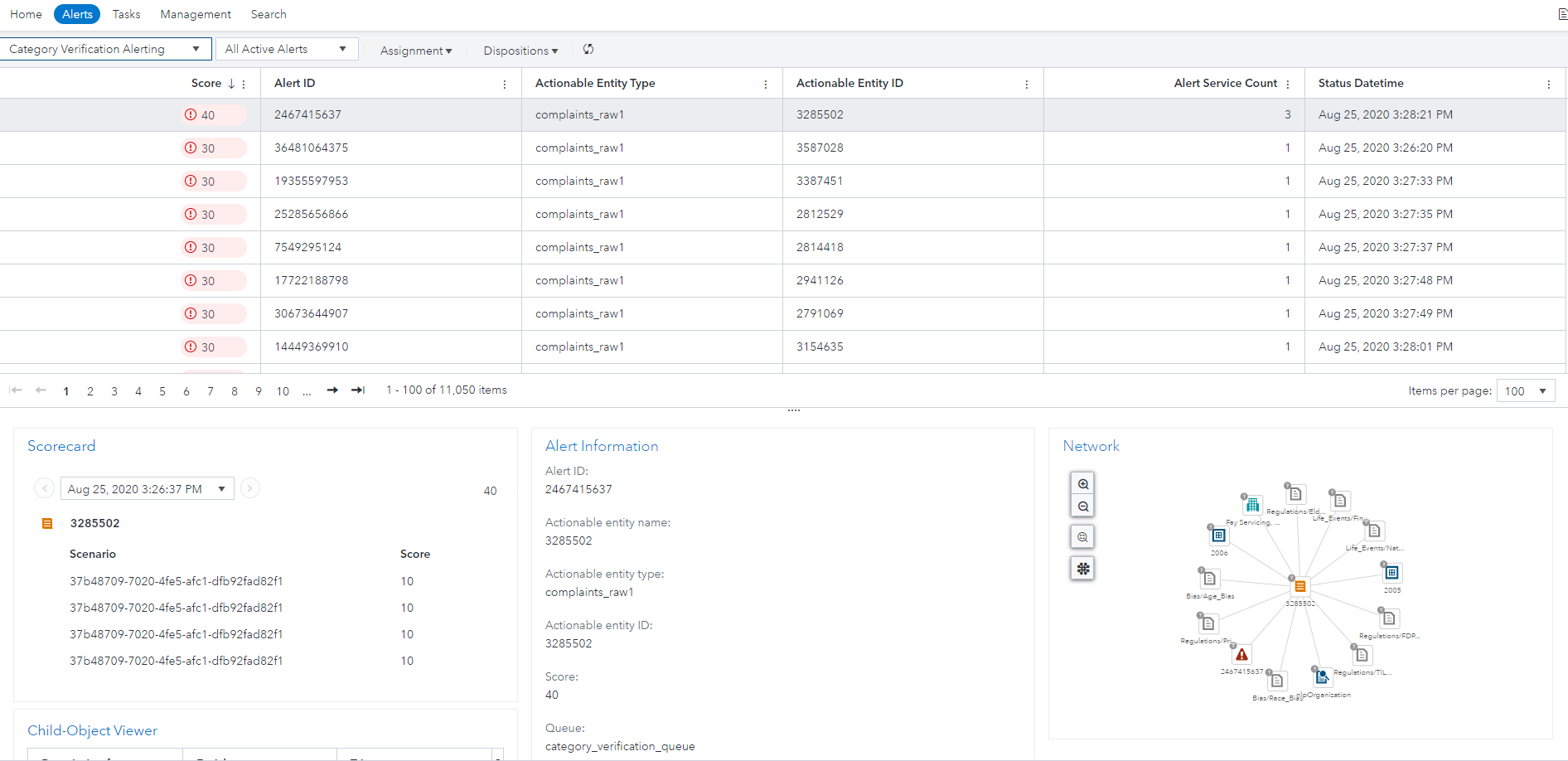
The model developers often don’t have the domain expertise to audit the output of their model. A separate party, such as a member of the line of business or compliance team, may be needed. Using the solution, we can control which member group the alert triggers for and control which users can process the alert. From here, the appropriate party can manually check the complaint narrative to see if the category match was correct. Along with the actual complaint, our models produce a match score as well as the keywords that drive the match which are presented to the investigator to help triage. In the example below, we are looking for references to natural disasters, career troubles, and financial troubles. We can validate these three categories because we see terms such as “FEMA declared disaster zone,” “out of work,” “collection company,” and others highlighted in yellow.
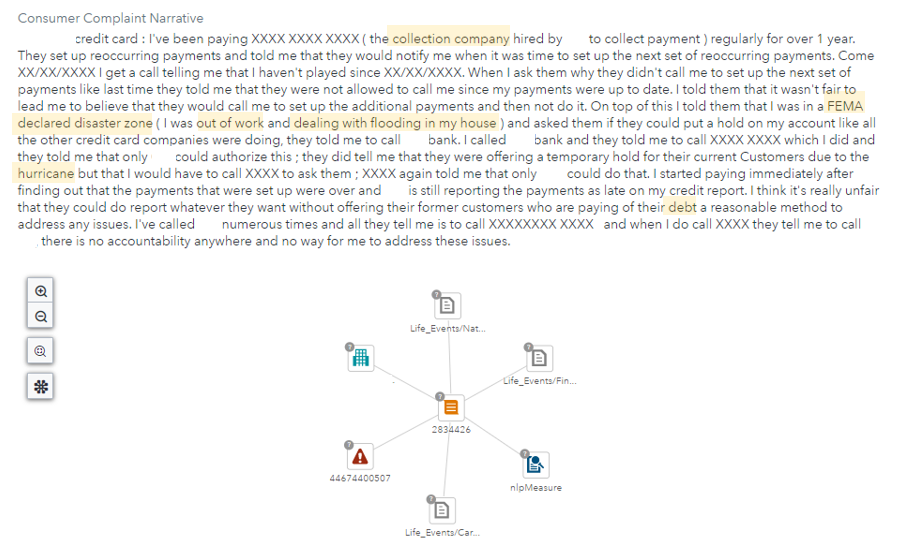
Using a workflow task, an investigator returns their assessment as a match or a non-match. All data from the user interactions is tracked and audited and can be leveraged internally or externally to the solution. For our purposes, we generated a dashboard that visualizes the performance of our category rules. Categories typically follow a taxonomy or hierarchy. Additionally, results can be summarized at various levels of the hierarchy to determine where to focus efforts. Our categories built to find mentions of regulations are performing better than our categories built to find bias. We can explore the performance of individual categories as well.
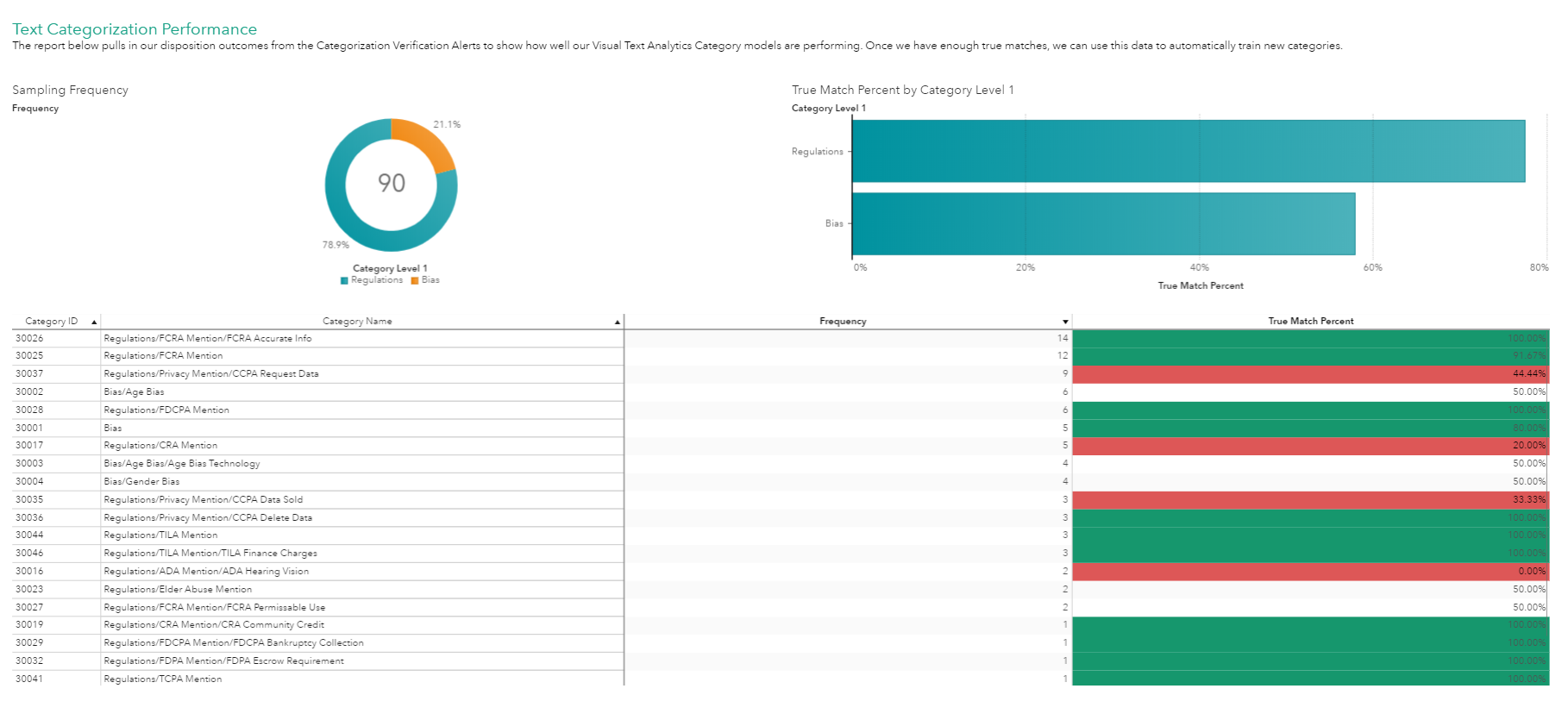
A key feature within the solution’s text analytics capabilities is its ability to automatically generate Boolean classification rules from existing labeled data. Within the Text Investigation Framework, we developed a feedback loop. Our feedback loop compiles the complaints of the poorly performing categories with the true positive classifications and triggers a new text modeling project to create improved rules. This feedback loop ensures that your categorization results should get better over time.
Trending Topics and Categories
Trending topics and categories are those that are recently occurring at a greater frequency over a defined time period. By monitoring our trending topics and categories, we can get a pulse on what is top of mind for consumers. This allows us to make better-informed strategic operational changes. This information can include problems to address, product changes to make, or even potential areas of market share that can be expanded.
One powerful feature of the solution is to easily aggregate transaction-level data to create look-back periods for alerting. With this feature, we can create alerts on topics and categories that are occurring more often. Normally a complex coding process, creating aggregations and look-backs in the solution is fast and easy with our user interface. To prioritize our findings, our alerts will give higher scores to topics and categories with the greatest growth in frequency.
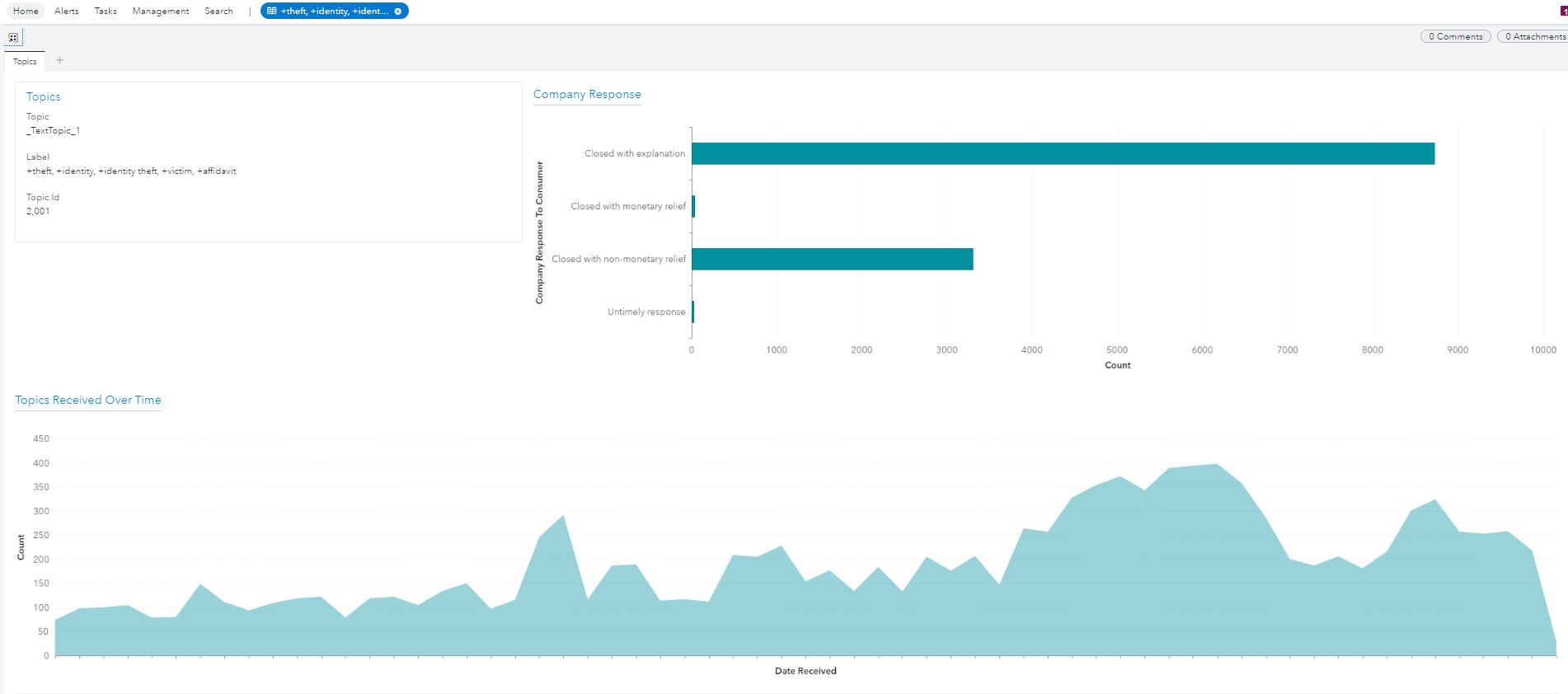
We can explore the topic or category featured in the alert for more information. Below, we can see that complaints around identity theft peaked around two quarters ago. Then they dipped down for a quarter and rose up this quarter. If we are examining growth between this quarter and last quarter, this is a clear increase across quarters. With this knowledge that identity theft complaints are on the rise, organizations can rethink their processes to better protect consumers and prevent identity theft.
Conclusion
The Text Investigation Framework was designed to create a process for turning unstructured text data into a decisioning system. Today, we applied this framework to monitoring financial consumer complaints. By monitoring complaints, we hope to provide a better experience for customers while ensuring regulatory compliance. Financial institutions with an intimate knowledge of their complaints can identify problematic trends and quickly remediate issues while potentially reducing any losses due to regulator enforcement actions. If you’re interested in understanding how SAS can better help operationalize your text analytics, please contact Sophia Rowland or Austin Cook.






