In machine learning, a feature is another word for an attribute or input, or an independent variable.
What is feature engineering?
Feature engineering is a process of preparing inputs for machine learning models. The goal of feature engineering is to to improve classification accuracy by considering the limitations of the learning algorithms. Preparation involves working with raw data through various feature transformations, extractions, feature selection and handcrafting new features. This process sometimes involves bringing in additional information from other sources.
Below are a few feature engineering examples that are commonly used by practitioners:
- Numeric encoding for high-cardinality nominal variables such as zip code.
- Normalizing, binning, log transformation for interval variables.
- Transformations based on missingness patterns.
- Dimension reduction techniques such as autoencoders, principal component analysis (PCA), t-Distributed Stochastic Neighbor Embedding (t-SNE), and singular value decomposition (SVD).
- Creating a new variable such as breaking down the date variable into separate variables for day of the week and month and year to capture seasonal trends.
In predictive modeling tasks, data scientists consistently report that they spend most of their time on feature engineering.
Feature engineering requires spending a lot of time with data. This includes examining descriptive statistics (such as number of levels of nominal variables, missingness, skewness of interval variables, pairwise correlations and so on) and simple graphs of input variables. The process involves thinking about structures in the data, the underlying form of the problem, and how best to expose these features to predictive modeling algorithms.
The success of this tedious human-driven process depends heavily on the domain and statistical expertise of the data scientist.
The most successful features are often the ones that are hand crafted very thoughtfully by exploiting deep knowledge of the domain considered or a good understanding of the datasets. For example, consider a housing data set like Kaggle's competition data for the Zillow Prize.
By using the zip code and another continuous feature such as total square foot of houses, you can create a new feature for the median total square foot within each zip code. You can even create another feature for the difference between the median and the actual total square foot. This new variable can be very predictive because within each neighborhood it helps to identify the houses that are different in terms of total square feet.
The feature engineering process requires a good understanding of the size and the quality of the data in hand, the performance metric that's being optimized, and the machine learning algorithm that is used. For example, if boosted trees are used, then transformations (that do not affect the rank order) tend to make a slight difference since only rank order matters for splits in trees.
In addition, when creating new features, you always need to guard against information leakage by using cross-validation very carefully. For example, if you use the target values in new feature creation directly or indirectly in the training set, you need to make sure that you don’t use target values in the same way for the validation set. Otherwise, your prediction accuracy would be too optimistic due to information leakage.
Although feature engineering is one of the most time-consuming processes and requires many skill sets, if done right, it’s also the most rewarding part of data science pipelines.
Good features not only boost your predictive accuracy but also give you the flexibility to train simpler models. This, in turn, enables you to understand and interpret your model better. By using powerful features, you can choose to fit a more interpretable regression model with fewer predictors as opposed to training a complex black-box model (which is hard to interpret) without sacrificing your prediction accuracy. In addition, deploying models with fewer features is preferable as maintaining less number of features is easier.
Why automate feature engineering?
All the requirements of successful feature engineering have made automating feature engineering a very challenging task. At the same time, however, the proven results have made automated feature engineering a hot and exciting topic recently in academia and among the machine learning scientists here at SAS. Automating feature engineering has the following advantages:
- Enables data scientists to try many different ideas with minimal effort.
- Decreases the workload of data scientists by enabling them to quickly try some simple ideas and determine promising directions that they want to invest more time.
- Helps with the shortage of data scientists who have the necessary skills.
How to automate feature engineering tasks with templates
Model Studio in SAS Visual Data Mining and Machine Learning is a web-based platform. It includes a suite of integrated tools for a comprehensive and visual approach to a wide variety of analytic data mining problems.
The software provides new data miners with preconstructed predictive modeling pipelines, called templates, to help them jump start their use of the software. Model Studio templates can be run directly for different projects that are based on different datasets.
You can modify existing templates, create your own data mining templates to quickly prototype, enhance and share models for desired analytical tasks. Thus, templates are great tools for automated tasks such as feature engineering.
The automated feature engineering template is the newest addition to the collection of templates in Model Studio.
Automation through Model Studio templates is a great tool for both experts and non-experts. It helps non-experts try some simple ideas first to see if there is any value in their data sets before they invest more time. Therefore, it can help companies make quick decisions with lower cost before exhausting all possible feature engineering techniques with the hope that one of them would work. In addition, it provides an environment for domain experts to quickly create their own templates based on years of experience on working with similar data which can be used repeatedly for their next projects and shared with data scientists who have less experience.
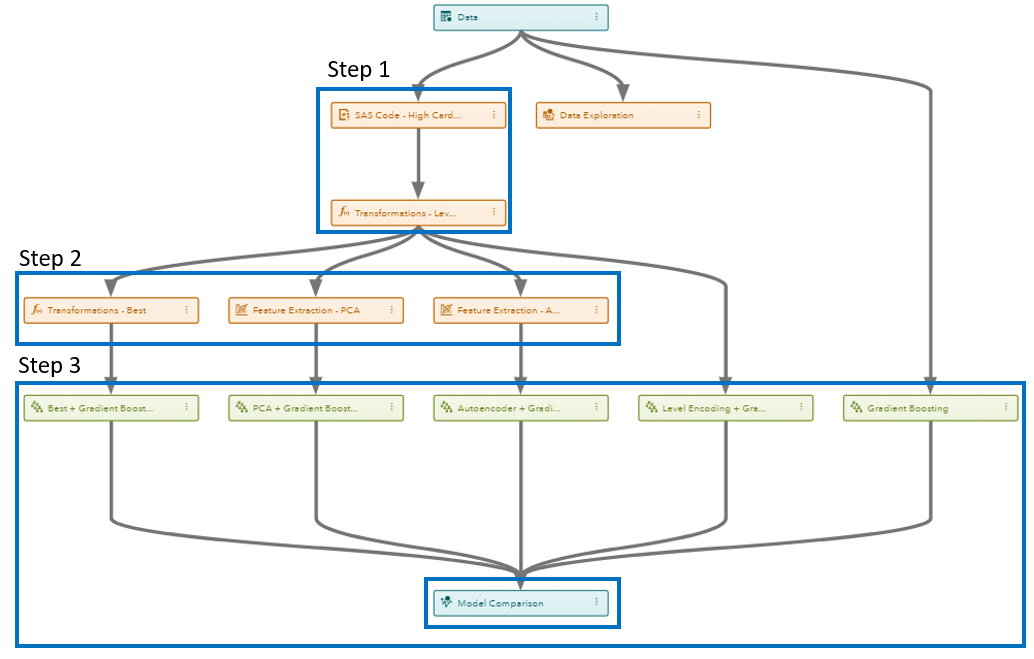
This is the first feature engineering template in Model Studio. It automatically creates engineered features by using popular feature transformation and extraction techniques. The idea is to automatically learn a set of features (from potentially noisy, raw data) that can be useful in supervised learning tasks without needing manually create handcrafted engineered features. This template can be explained in 3 steps as shown by the figure:
- Performing level encoding for high-cardinality variables.
- Creating new features by using “Best” transformation, PCA / SVD, and autoencoder methods.
- Comparing the predictive performance of the newly engineered features to original features.
A more detailed explanation of the template can be found at “3 Steps of the Automated Feature Engineering Template in SAS.”
It’s important to remember that using this template does not guarantee that one of the automatically created feature sets will perform better than the original features for your data, because every data set is unique, and this template uses only a few techniques. Instead, the goal of this template is to show an example of how you can create different automatically engineered feature sets by using many other tools provided in Model Studio and test their performance in a similar way with a minimal effort.
You can easily modify this template or create your own from scratch that is tailored for your own business application, and then share it with your coworkers. We are very much looking forward to hearing about how you use Model Studio templates to create feature engineering templates that consider a lot of the data issues in your domain such as healthcare, insurance and finance.
If you are interested in learning more about SAS data mining and machine learning capabilities check out SAS Visual Data Mining and Machine Learning or watch this demo about feature engineering in SAS from Brett Wujek.






