Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. In this post I'll discuss how to load multiple CSV files into memory as a single table using the loadTable action.
Load and prepare data on the CAS server
To start, we need to create multiple CSV files in a folder. I created this script to load and prepare the CSV files in the CAS server for this post. This should work in your environment. The script does the following:
- Loads the WARRANTY_CLAIMS_0117.sashdat files from the Samples caslib into memory.
- Modifies the in-memory table by renaming and dropping columns.
- Adds a sub directory in the Casuser caslib named csv_file_blogs.
- Saves a CSV file for each distinct year in the csv_file_blogs folder.
- Drops the original CAS table.
import swat import pandas as pd ## Connect to CAS conn = swat.CAS(Enter your CAS connection information) ## ## Data prep functions ## def prep_data(): """ Load and prepare the warranty_claims_0017.sashdat file in CAS """ ## Load the WARRANTY_CLAIMS_0117.sashdat from the Samples caslib into memory in Casuser conn.loadTable(path='WARRANTY_CLAIMS_0117.sashdat', caslib='samples', casout={'name':'warranty_claims', 'caslib':'casuser', 'replace':True}) ## ## DATA PREP ## ## Reference the CAS table in an object castbl = conn.CASTable('warranty_claims', caslib = 'casuser') ## Store the column names and labels in a dataframe df_col_names = castbl.columnInfo()['ColumnInfo'].loc[:,['Column','Label']] ## Create a list of dictionaries of how to rename each column using the column labels renameColumns = [] for row in df_col_names.iterrows(): colName = row[1].values[0] labelName = row[1].values[1].replace(' ','_') renameColumns.append(dict(name=colName, rename=labelName)) ## List of columns to keep in the CAS table keepColumns = {'Campaign_Type', 'Platform','Trim_Level','Make','Model_Year','Engine_Model', 'Vehicle_Assembly_Plant','Claim_Repair_Start_Date', 'Claim_Repair_End_Date'} ## Rename and drop columns to make the table easier to use castbl.alterTable(columns = renameColumns, keep = keepColumns) ## Return the CASTable object reference return castbl def save_cas_table_as_csv_files(cas_table_reference): """ Create a subdirectory in Casuser and save mutliple CSV files in it. """ ## Create a subdirectory in the Casuser caslib named csv_file_blogs conn.addCaslibSubdir(name = 'casuser', path = 'csv_file_blogs') ## Create a CSV file for each year for year in list(castbl.Model_Year.unique()): (cas_table_reference .query(f"Model_Year ='{year}'") .save(name = f'csv_file_blogs/warranty_claims_{year}.csv', caslib = 'casuser', replace = True) ) ## Drop the CAS Table cas_table_reference.dropTable() ## View files in the csv_file_blogs subdirectory fi = conn.fileInfo(allFiles = True, caslib = 'casuser') fi_subdir = conn.fileInfo(path = 'csv_file_blogs', caslib = 'casuser') display(fi, fi_subdir) ## Create the CAS table castbl = prep_data() ## Save the CAS table as a CSV file for each year save_cas_table_as_csv_files(castbl) ## and the results NOTE: Cloud Analytic Services made the file WARRANTY_CLAIMS_0117.sashdat available as table WARRANTY_CLAIMS in caslib CASUSER(Peter). NOTE: Cloud Analytic Services saved the file csv_file_blogs/warranty_claims_2015.csv in caslib CASUSER(Peter). NOTE: Cloud Analytic Services saved the file csv_file_blogs/warranty_claims_2016.csv in caslib CASUSER(Peter). NOTE: Cloud Analytic Services saved the file csv_file_blogs/warranty_claims_2017.csv in caslib CASUSER(Peter). NOTE: Cloud Analytic Services saved the file csv_file_blogs/warranty_claims_2018.csv in caslib CASUSER(Peter). NOTE: Cloud Analytic Services saved the file csv_file_blogs/warranty_claims_2019.csv in caslib CASUSER(Peter). NOTE: Cloud Analytic Services dropped table warranty_claims from caslib CASUSER(Peter.Styliadis). |
The results show that five CSV files named warranty_claims<year>.csv were created in the subdirectory csv_file_blogs in the Casuser caslib.
Next, I'll use the fileInfo action to view the new csv_file_blogs subdirectory in the Casuser caslib. In the fileInfo CAS action use the includeDirectories parameter to view subdirectories.
conn.fileInfo(includeDirectories = True, caslib = 'casuser') |

Lastly, I'll view the available files in the csv_file_blogs subdirectory. To view files in a subdirectory in a caslib add the folder name in the path parameter.
conn.fileInfo(path = 'csv_file_blogs', caslib = 'casuser') |
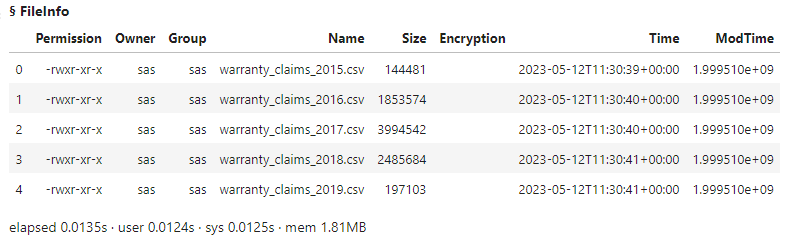
The results show that the subdirectory has five CSV files.
Load all of the CSV files as a single table
To easily load multiple CSV files as a single in-memory CAS table use the table.loadTable CAS action. The only requirements when loading multiple CSV files:
- All of the CSV files must end with .csv.
- Set the multiFile option to True in the importOptions parameter.
- The CSV files must have the same number of columns and the columns must have the same data type.
Here, I'll use the loadTable action with the path parameter to specify the subdirectory csv_file_blogs and the caslib parameter to specify the Casuser caslib. The importOptions parameter uses the fileType option to determine the other parameters that apply. The CSV file type has a multiFile option. If you set the multiFile option to True, it will try to load all CSV files from the path into a single in-memory table. The casOut parameter simply specifies output CAS table information.
conn.loadTable(path="csv_file_blogs", caslib = 'casuser', ## Specify the subdirectory name (csv_file_blogs) and the input caslib name importOptions = { ## Specify the import options 'fileType' : 'CSV', 'multiFile' : True }, casOut = { ## Specify output CAS table information 'name' : 'allCSVFiles', 'caslib' : 'casuser', 'replace' : True }) ## and the results NOTE: The file, '/cas/data/caslibs/casuserlibraries/peter/csv_file_blogs/warranty_claims_2015.csv' was used to create the CAS Table column names. NOTE: The CSV file table load for table, 'allCSVFiles' produced 153217 rows from 5 files. NOTE: Cloud Analytic Services made the file csv_file_blogs available as table ALLCSVFILES in caslib CASUSER(Peter). |
The action concatenated each CSV file and loaded them as a single distributed CAS table named ALLCSVFILES.
Next, I'll run the tableInfo action to view available in-memory tables in the Casuser caslib.
conn.tableInfo(caslib = 'casuser') |

The action results show one CAS table is in memory.
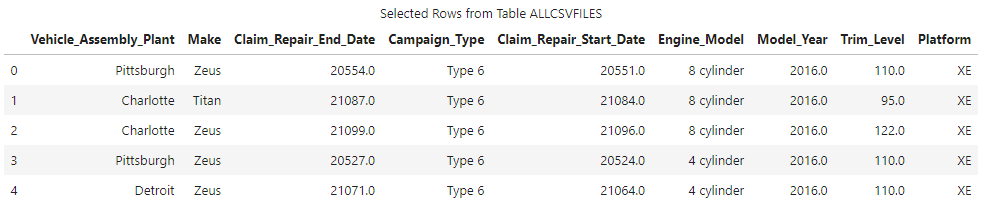
Then I'll make a client-side reference to the distributed CAS table and run the head method from the SWAT package.
allcsvfilesTbl = conn.CASTable('allcsvfiles', caslib = 'casuser') allcsvfilesTbl.head() |
Finally, I'll run the SWAT value_counts on the Model_year column.
(allcsvfilesTbl ## CAS table .Model_Year ## CAS column .value_counts() ## SWAT value_counts method ) ## and the results 2017.0 70479 2018.0 43975 2016.0 32707 2019.0 3510 2015.0 2546 dtype: int64 |
The results show all five years of data were imported into the CAS table, one for each CSV file.
Add file name and path columns to the CAS table
The importOptions parameter has a variety of CSV options you can use to modify how to import the files. Two useful options are showFile and showPath. The showFile option includes a column that shows the CSV file name. The showPath option includes a column that shows the fully-qualified path to the CSV file.
conn.loadTable(path="csv_file_blogs", caslib = 'casuser', ## Specify the subdirectory name (csv_file_blogs) and the input caslib name importOptions = { ## Specify the import options 'fileType' : 'CSV', 'multiFile' : True, 'showFile' : True, 'showPath' : True }, casOut = { ## Specify output CAS table information 'name' : 'allCSVFiles_path_info', 'caslib' : 'casuser', 'replace' : True }) ## and the results NOTE: The file, '/cas/data/caslibs/casuserlibraries/peter/csv_file_blogs/warranty_claims_2015.csv' was used to create the CAS Table column names. NOTE: The CSV file table load for table, 'allCSVFiles_path_info' produced 153217 rows from 5 files. NOTE: Cloud Analytic Services made the file csv_file_blogs available as table ALLCSVFILES_PATH_INFO in caslib CASUSER(Peter). |
I'll run the tableInfo action to view available CAS tables.
conn.tableInfo(caslib = 'casuser') |
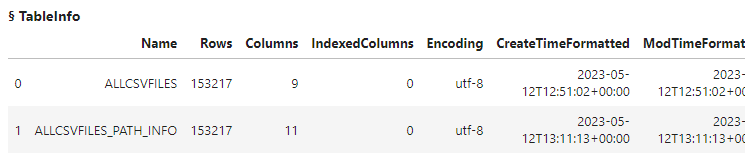
The action shows that two CAS tables are now in-memory.
I'll reference and preview the new CAS table .
allcsvfiles_path_infoTbl = conn.CASTable('allcsvfiles_path_info', caslib = 'casuser') allcsvfiles_path_infoTbl.head() |

The preview shows the new CAS table has a column named path and a column named fileName.
Lastly, I'll use the SWAT value_counts method to view how many rows came from each CSV file. I'll specify the CAS table reference, the column name, then the value_counts method.
(allcsvfiles_path_infoTbl .fileName .value_counts() ) ## and the results warranty_claims_2017.csv 70479 warranty_claims_2018.csv 43975 warranty_claims_2016.csv 32707 warranty_claims_2019.csv 3510 warranty_claims_2015.csv 2546 dtype: int64 |
The results show the CSV files were concatenated into a single CAS table. We can see how many rows came from each file.
Summary
The SWAT package blends the world of pandas and CAS to process your distributed data. In this example I focused on using table.loadTable CAS action to concatenate multiple CSV files into a single distributed CAS table using a single method.
