Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. In this post I'll discuss how to update rows in a distributed CAS table.
Load and prepare data in the CAS server
I created a script to load and prepare data in the CAS server. This should work in your environment. The script:
- connects to the CAS server
- loads the RAND_RETAILDEMO.sashdat file from the Samples caslib into memory in the Casuser caslib and names the CAS table rand_retaildemo
- lower cases all column names
- keeps specific columns
- creates a new column named age_dup that is a duplicate of the age column
- previews the new CAS table
## Packages import swat import os import pandas as pd pd.set_option('display.max_columns', 50) import numpy as np ## General CAS connection syntax conn = swat.CAS(host, port, username, password) ## Add your connection information ## Load the RAND_RETAILDEMO.sashdat file into memory on the CAS server conn.loadTable(path = 'RAND_RETAILDEMO.sashdat', caslib = 'samples', casout = { 'name' : 'rand_retaildemo', 'caslib' : 'casuser', 'replace' : True }) ## Reference the CAS table retailTbl = conn.CASTable('rand_retaildemo', caslib = 'casuser') ## Create a copy of the table with a new column (retailTbl .eval("age_dup = age", inplace = False) ## create a duplicate of the age column .copyTable(casout = {'name':'rand_retaildemo', 'caslib':'casuser', 'replace':True}) ) ## Create a list of columns to rename newColNames = [{'name':col,'rename':col.lower()} for col in retailTbl.columns.to_list()] ## List of columns to keep keepColumns = ['custid','bucket','age','age_dup','loyalty_card','brand_name','channeltype','class'] ## Rename and keep columns retailTbl.alterTable(columns = newColNames, keep = keepColumns) ## Preview the new CAS table display(retailTbl.shape, retailTbl.tableDetails(), retailTbl.tableInfo(caslib = 'casuser'), retailTbl.head()) ## and the results NOTE: Cloud Analytic Services made the file RAND_RETAILDEMO.sashdat available as table RAND_RETAILDEMO in caslib CASUSER(Peter). |
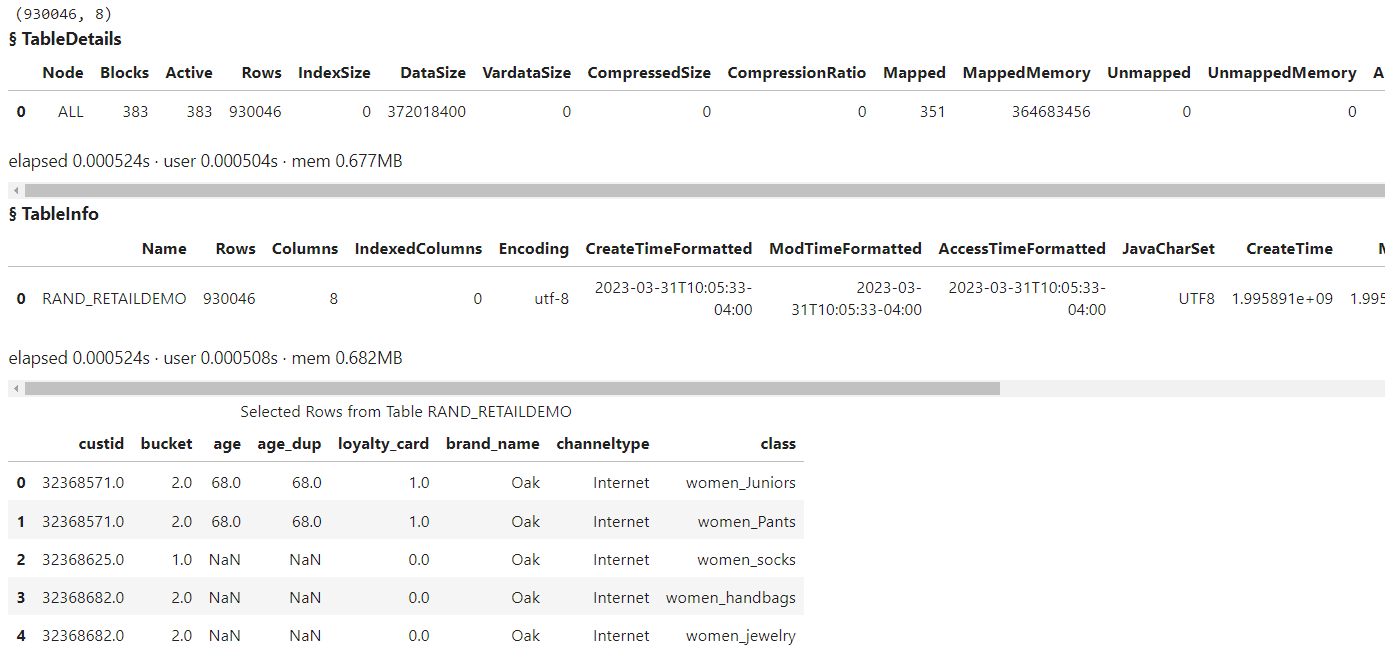
The results show:
- the file RAND_RETAILDEMO.sashdat was loaded into memory in the Casuser caslib as the CAS table RAND_RETAILDEMO
- the CAS table RAND_RETAILDEMO has 930,046 rows and 8 columns
- the CAS table is separated into 383 blocks
- the Casuser caslib has one table loaded into memory (RAND_RETAILDEMO)
- a five row preview the RAND_RETAILDEMO CAS table
Update rows in a table
The preview of the CAS table shows the brand_name, channeltype and class columns contain character values. I want to standardize the casing of the character data in each of those columns by:
- upper casing all values in the brand_name column
- lower casing all values in the channteltype column
- proper casing all values in the class column
I'll use the table.update CAS action to update rows in a CAS table. In the update action specify the set parameter with a list of dictionaries, each dictionary specifies the column to update and how to update it. In the dictionary var specifies the column name and value specifies how to update the column. The value key requires SAS functions or constants.
retailTbl.update(set = [ {'var':'brand_name', 'value':'upcase(brand_name)'}, {'var':'channeltype', 'value':'lowcase(channeltype)'}, {'var':'class', 'value':'propcase(class)'} ]) |
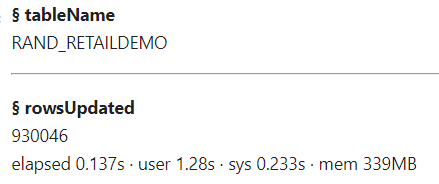
The results show I updated all 930,046 rows with the update action. Next, I'll preview the updated CAS table.
retailTbl.head() |
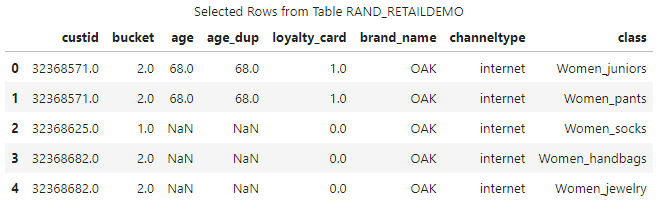
The preview shows I updated the case of the brand_name, channeltype and class columns.
View missing values
Next I'll execute the distinct action on the age and age_dup columns to confirm they have missing values. The age_dup column is simply a copy of the age column.
retailTbl.distinct(inputs = ['age', 'age_dup']) |
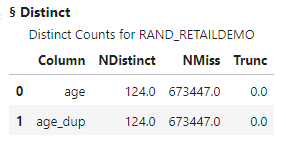
The results show the columns have 673,447 missing values.
Update rows based on a condition
After finding missing values, I've determined I want to replace them with the mean age. I'll start by storing the mean age in the variable meanAge.
meanAge = retailTbl.age.mean().round(3) meanAge ## and the results 43.577 |
Specifying the rows to update
One way to update values by a condition is by filtering the CAS table for the rows to update. You can do that by specifying the query method to filter the CAS table for all rows where age is missing. Then add the update action to update the age column using the meanAge variable value.
(retailTbl .query("age is null") .update(set = [ {'var':'age', 'value':f'{meanAge}'}]) ) |
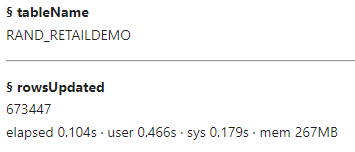
The update action updated 673,447 rows. This number matches the total number of missing values in the age column. Let's run the distinct action to confirm no missing values exist in age.
retailTbl.distinct(inputs = ['age', 'age_dup']) |
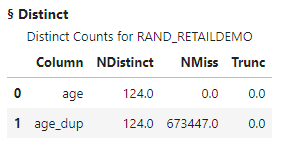
The distinct action shows the age column does not have any missing values. I'll confirm the unique values in the age column by running the value_counts method.
(retailTbl .age .value_counts() ) |

The value_counts method shows that 673,447 rows have the mean age value 43.577.
Update rows using conditional logic
Another way to update rows is using conditional logic. You can perform conditional logic with the SAS IFN function (IFC for character). The IFN function returns a numeric value based on whether an expression is true, false, or missing. Here I'll specify the IFN function and test if age_dup is missing. If age_dup is missing, return the meanAge value. Otherwise, return the original age_dup value.
(retailTbl .update(set = [ {'var':'age_dup', 'value':f'ifn(age_dup = . , {meanAge}, age_dup)'}]) ) |
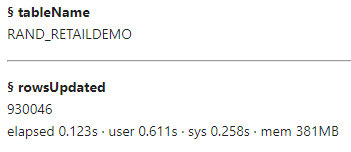
The update action updated all 930,046 rows. All rows are updated because conditional logic checks each row and updates the values. While this method works, for this scenario the previous method is a bit more efficient since only the necessary rows are updated.
Let's confirm no missing values exist the age_dup column.
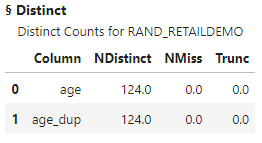
The distinct action shows the age_dup column does not have any missing values. I'll confirm the unique values in the age_dup column by running the value_counts method.
(retailTbl .age_dup .value_counts() ) |
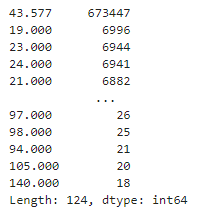
The value_counts method shows that 673,447 rows have the mean age value 43.577. These are the expected results.
Save the CAS table as a data source file
Lastly, I'll save the updated CAS table as a data source file using the table.save action. For more information on saving CAS tables check out my previous post Part 17 - Saving CAS tables.
retailTbl.save(name = 'retail_clean.parquet', caslib = 'casuser') ## and the results NOTE: Cloud Analytic Services saved the file retail_clean.parquet in caslib CASUSER(Peter). |
Summary
The SWAT package blends the world of pandas and CAS to process your distributed data. In this example I focused on using the Python SWAT package to update rows in a CAS table. Updating data in CAS tables is a bit different than updating DataFrames using pandas. Understanding how to update CAS tables enables you to avoid having to create a copy of a large in-memory CAS table, improving speed and conserving resources.
