Payment Fraud continues to be a challenge for banks. With the increasing number of digital payment types and the ever-growing volumes of Real-Time Payments, real-time fraud detection and prevention are vital.
At the same time, customers are demanding a frictionless customer experience, so fraud detection methods need to be sophisticated enough to maintain the required balance.
While rules-based detection can be a good start, it can be difficult to keep up with fraud shifts and maintain efficacy. Rules tend to be reactively built based on individual fraud cases rather than considering full customer data and behavior.
Machine learning combined with behavior profiling alongside rules are best deployed together as part of a layered fraud prevention approach. Machine learning models use advanced methodologies and statistical techniques to identify risky payments. They are highly predictive not only in identifying fraud but also in being able to identify those genuine customer transactions to ensure that the high False positive ratios necessary in today’s environment are achievable.
Supervised vs Unsupervised learning
Supervised learning is when the model is trained on labeled data. In the case of a fraud model, this means having accurately tagged fraudulent transactions within the training data set. The model learns from this data to help predict outcomes in the future. Supervised methods include methodologies like linear regression, logistic regression, decision trees and random forest.
In unsupervised learning, the model is not trained on labeled data and instead works to gain its own insights from the data. Unsupervised learning uses clustering and association techniques.
Supervised models generally have better performance and are more predictable than unsupervised ones. However, supervised Machine Learning techniques require an upfront investment to ensure that the data is tagged correctly to achieve the best results. This may not be possible for organizations whose fraud reporting is not well-controlled or in the case of RTP they have few historical fraud events. In these cases, semi-supervised models may be ideal where supervised learning methods are first used to derive a preliminary set of features or models followed by an application of unsupervised methods to refine the results.
SAS models
SAS provides industry leading predictive models using a range of machine learning. These are generally built with the bank’s own data to give them the optimal fraud detection, unique to their customers and unique to the fraud patterns which they have.
To support behavior profiling, each SAS model is built including SAS’s patented Signature technology, which is a method of storing an entity’s historical transactional information and allows the model to determine someone’s typical habits. SAS models are able to support multi-entity Signatures; these might include customer, account, beneficiary or device, for instance. When scoring a transaction, the model accounts for not only the current transaction, but also the historical behavioral activity of all relevant entities captured by the Signatures. It is widely recognized that historical behavior is predictive of fraud. Typically, there are regular patterns of usage or spending; therefore, deviations from these established patterns may indicate suspicious activity and fraud.
SAS uses the information in these Signatures to derive hundreds of statistical variables that target unusual activity and collectively serve as inputs for the fraud detection model.
Examples of behavioral variables that can be derived from Signatures include, but are not limited to, the following: Average number of transactions in a given period, Typical spending amounts, Typical bill pay usage, Geographical variance and Spend velocity.
Geographic location related variables are very useful information for fraud detection, however customer locations on file aren’t always reliable. Sometimes that information is unavailable, so trying to use this fixed home location to calculate distance from home may not be appropriate. So, SAS also developed a proprietary dynamic home which allows the model to infer the current location of the customer. It uses the locations of clustered transactions to help reduce the false positives where the customer's home location is not actually representative of their true home or the area in which they usually transact.
In addition to behavioral variables, the fraud model relies on risk variables that capture relative fraud risk of various aspects of transactions based on historical data. These risk variables are complementary to behavioral characteristics described above and play a particularly important role in scoring customers and users without regular patterns of spending activity.
SAS begins with thousands of possible model features derived from various input fields. During the modelling process, the number of variables is reduced through a combination of techniques including applying transformations, Kolmogorov–Smirnov tests, correlation with target, Linear / logistic regression, linear interdependency and missing value imputation.
For each of the steps above, SAS follows a threshold-based approach. For example, SAS picks a threshold for the correlation between target and variable. All variables that fall below this threshold are eliminated from modelling. The exact value of the threshold is based on the SAS modelling teams' previous experience, so that the number of candidate variables after filtering remains sufficient to proceed with the subsequent steps.
Finally, SAS also performs several checks to filter out unstable variables.
This reduction of variables invariably results in the selection of the most significant variables that contribute the most to model performance. Among the final set of variables, different variables are important as different scenarios are encountered.
SAS models can also benefit from behavior segmentation. An example of behavior segmentation is to separate business and consumer customers early in the modelling process and essentially build separate models with the variables that are most relevant to each segment.
Different modelling techniques such as gradient boosting and neural networks are considered to determine the best technique. In fact, a combination of techniques are often used to achieve the best performance through an ensemble model.
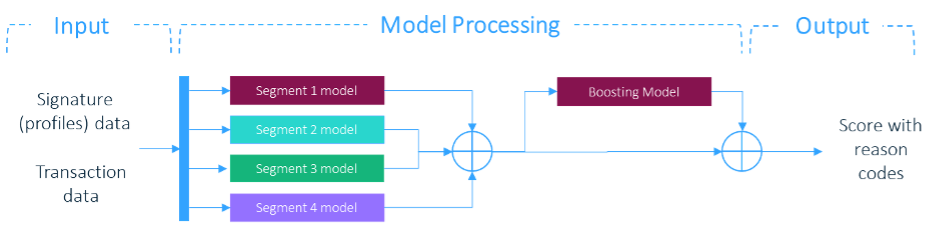
SAS models output a score from 0 to 999 to indicate the likelihood of the transaction being fraudulent. SAS has developed proprietary, reason code-generation technology which allows the model output to also include a list of risk reason codes. These reason codes are designed to give end users insights of the relevant risks associated with the model output score. Unlike traditional techniques that use individual variables as reasons, the SAS methodology first groups variables that are correlated and have a similar concept into different risk factors. Each of these risk factors are represented by a reason code. The model produces three such risk reason codes that indicate the top three highest priority reasons for why a transaction is likely to be in a fraudulent state (if it is indeed at risk at the time of the transaction).
Case Study 1:
Client A required a model to score real-time payments transactions.
The modelling period was based on 18 months of historical data which included non-monetary transactions such as logins and detail changes, payments and deposit transactions and fraud data. This date range ensures coverage of seasonality and major recurring socio-economic events such as tax payments. As fraud reporting is usually delayed, additional months of fraud data were also included to ensure that all the fraud that occurred during the 18-month period was included.
Various data issues were identified by SAS, the modelling impact was determined and the issues were rectified in the data at source where possible or documented for consideration in modelling.
The main categories of fraud seen in the data were Account Takeover cases where the customer’s credentials were stolen, cases where the customer was involved, cases where the customer was implicit in giving the fraudster their money or credentials such as with an investment scam, romance scam, phone phishing, remote access fraud or an email hack.
The Account Takeover cases made up the majority of the fraud transactions, but the customer involved case contributed to most of the fraud money lost.
Signature entities at the Online user ID and customer level were used to build up a behavioral history across the various channels and transaction types to identify unusual behavior. Variables were developed which looked at the login events and financial transaction patterns. Additionally, SAS’s proprietary dynamic home idea was used to infer the typical locale of the customer to calculate a more accurate distance from home variable.
SAS tried various modelling methods and found that in this case, the gradient boosting method proved to be the most effective at detecting the highly complex and nonlinear patterns in this fraud detection problem.
The model evaluation indicated around a 17% rise in transaction detection rate and 11% rise in Value Detection rate over the existing payments model.
Case Study 2:
Client B required a model to score payment transactions made from their mobile, personal and business internet banking channels.
The modelling period was based on 17 months of historical data which include payments and fraud data. As with Client A, the data range ensured seasonality was considered and that the fraud during the period was captured.
A customer account Signature and a separate beneficiary account Signature were developed in this case, allowing the model to consider the holistic picture of the sender account and the receiving account independently. Variables were then able to be developed based around the patterns of these entities considering things such as transaction amount, time of day, sender and receiver relationships and maturity. Also, although only a portion of the IP address was provided in the data to maintain PII standards, SAS was able to create geolocation centroids from this which allowed SAS’s proprietary dynamic home idea to be used to inform the model as well.
A strong fraud pattern was detected that could not be identified solely on Signature information where accounts that only received money for a long time suddenly decided to send money. In order to catch such patterns in real-time via the model, SAS designed a new batch job feature to inform the model.
Behavior segmentation was implemented which split the transactions into two segments based on transaction types. The best model performance was achieved by using a gradient boosting trees model for one segment and a neural network model for the other.
During the evaluation period, the model performed very well with a Transaction Detection rate of 79.1% and a Value Detection Rate of 75% at a 11.4:1 False Positive Rate.
Conclusion
Between the dynamic payments landscape and the ever-adapting fraudsters who continue to find new ways to exploit technology and customers, identifying fraud is only becoming more complex. Standard fraud prevention approaches are no longer as effective as they once were. SAS’ advanced machine learning models, which can analyze behaviors and detect suspicious patterns in real-time, can go a long way in helping organizations to better prevent fraud and protect customers.
