Welcome to the fifth installment in my series Getting Started with Python Integration to SAS Viya. In previous posts, I discussed how to connect to the CAS server, how to execute CAS actions, how to work with the results, and how your data is organized on the CAS server. In this post I'll discuss loading files into the CAS server. Before proceeding, I need to clear up some terminology. There are two sources for loading files into memory, server-side and client-side. It's important to understand the difference.
Server-Side vs Client-Side
Let's start off with an image depicting server- and client-side file locations.

Server-side files are mapped to a caslib. That is, files in the data source portion of a caslib are server-side. For more infomation on data sources, see Part 4 of this series. Client-side files are files that are not mapped to a caslib. These could be files stored in a SAS library or other local files. That's about it!
In this post, I'll focus on loading server-side files into memory (Part 6 of the series will cover client-side files). In Python, we have two data loading options, the loadTable CAS action, or the load_path method. The techniques are almost identical. The difference is the loadTable action returns a dictionary of information and the load_path method returns a CASTable. If you use the loadTable action you must reference a new table in a separate step. In general, I prefer the actions as they are available in any language such as CASL, R, and Python. Conversely, methods like load_path are specific to a language.
Let's look at a few examples of loading different types of datafiles into CAS.
Loading a SAS Data Set into Memory
In the first example, I want to load the cars.sas7bdat SAS data set from the casuser caslib into memory. Let's confirm the table exists in the caslib by executing the fileInfo action. I made my connection to CAS, naming it conn. For more information about making a connection to CAS, visit Part 1 of the series.
conn.fileInfo(caslib="casuser") |
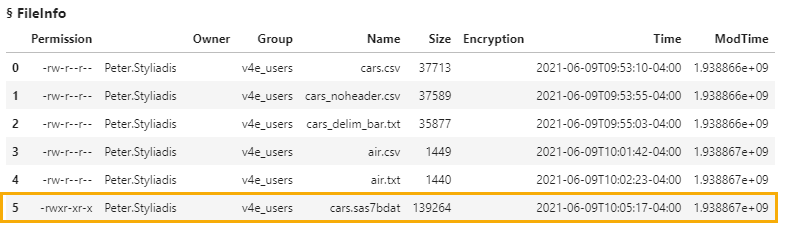
In the results I can see that the cars.sas7bdat file is available in the casuser caslib.
Next, I'll use the loadTable action. First I'll specify the path parameter with the full file name, then the caslib parameter specifying the input caslib, and lastly the casOut parameter to specify the new CAS table. In the casOut parameter you specify a dictionary of key value pairs. Here, I want to name the new table cars_sas and place the table in the casuser caslib.
conn.loadTable(path="cars.sas7bdat", caslib="casuser", casOut={ "name":"cars_sas", "caslib":"casuser" }) |
After executing the loadTable action, the result returns a dictionary of information about the new table.
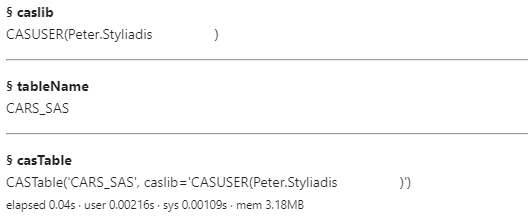
Now that the file is loaded into memory, I can process the data by making a reference to the in-memory table using the CASTable method. Then I'll use the head method to view the first 5 rows.
cars = conn.CASTable("cars_sas",caslib="casuser") cars.head() |

Loading a CSV file into Memory
In the next example, I'll load a CSV file into memory. Even though it's a different file type, we still use the loadTable action. The only change needed is the file name in the path parameter. That's it!
conn.loadTable(path="cars.csv", caslib="casuser", casOut={ "name":"cars_csv", "caslib":"casuser" }) csv = conn.CASTable("cars_csv", caslib="casuser") csv.head() |

Loading a Text file into Memory
Lastly, data is not always stored in the correct format. Sometimes when loading files you need to modify the default parameters. In this final scenario, let's explore an example using the importOptions parameter. importOptions takes a variety of key value pairs as the values to dictate how to load the file. The options vary depending on the file type.
The file in this example contains no column names, and the delimiter is a vertical bar (or pipe).
I'll begin with specifying the column names in a variable named colNames. Then, in the loadTable action I'll add the importOptions parameter and specify the following:
- file type I want to import, using the fileType subparameter,
- the delimiter, using the delimiter subparameter,
- the getNames subparameter with the value False, since no column names exist,
- and lastly, the vars subparameter with the names of the columns.
And as in the previous examples, I'll print out the first five lines of the resulting table from memory.
colNames=['Make', 'Model', 'Type', 'Origin', 'DriveTrain', 'MSRP', 'Invoice', 'EngineSize', 'Cylinders', 'Horsepower', 'MPG_City', 'MPG_Highway', 'Weight', 'Wheelbase', 'Length'] conn.loadTable(path="cars_delim_bar.txt", caslib="casuser", casOut={ "name":"cars_text", "caslib":"casuser" }, importOptions={"fileType":"DELIMITED", "delimiter":"|", "getNames":False, "vars":colNames} ) csv = conn.CASTable("cars_text", caslib="casuser") csv.head() |

Summary
The loadTable action is flexible and an easy way to load tables into memory. Benefits of the loadTable action include:
- it's filetype agnostic
- has many options available based on the file types being imported into memory
- available in any CAS-compatible language like Python, R and CASL with slight changes to the syntax based on the language used
