 In my previous post, we addressed the problem of inserting substrings into SAS character strings. In this post we will solve a reverse problem of deleting substrings from SAS strings.
In my previous post, we addressed the problem of inserting substrings into SAS character strings. In this post we will solve a reverse problem of deleting substrings from SAS strings.
See also: Inserting a substring into a SAS string
These two complementary tasks are commonly used for character data manipulation during data cleansing and preparation to transform data to a shape suitable for analysis, text mining, reporting, modeling and decision making.
As in the previous case of substring insertion, we will cover substring deletion for both, character variables and macro variables as both data objects are strings.
The following diagram illustrates what we are going to achieve by deleting a substring from a string:
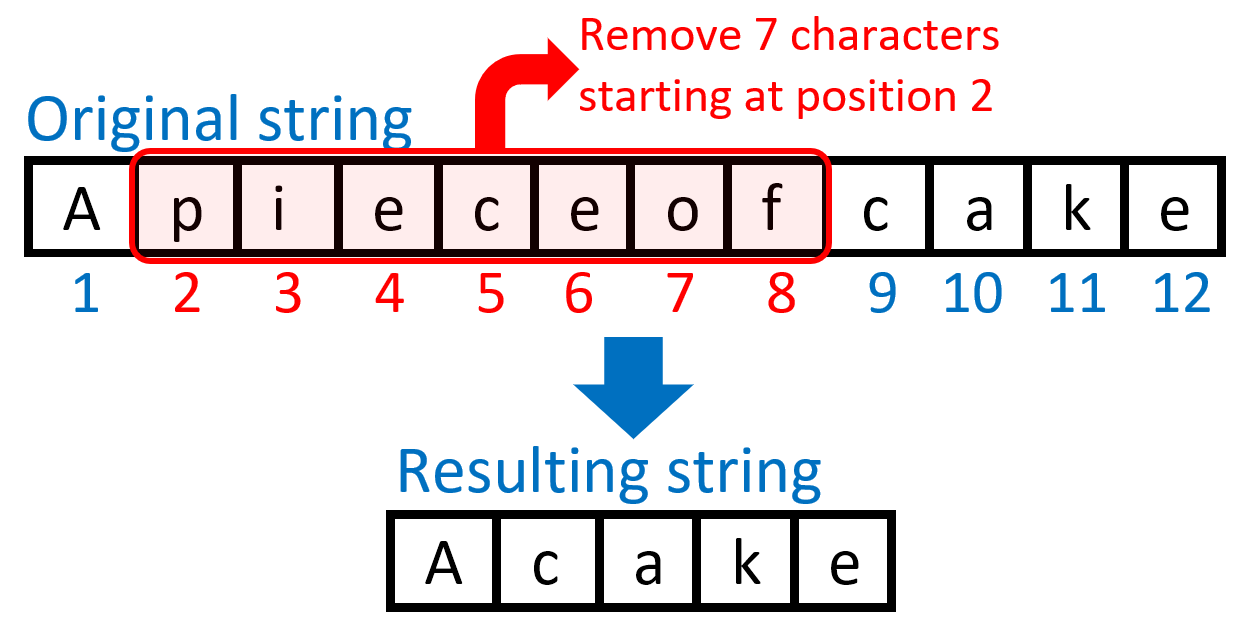
Have you noticed a logical paradox? We take away a “pieceof” cake and get the whole thing as result! 😊
Now, let’s get serious.
Deleting all instances of a substring from a character variable
Let’s suppose we have a variable STR whose values are sprinkled with some undesirable substring ‘<br>’ which we inherited from some HTML code where tag <br> denotes a line break. For our purposes, we want to remove all instances of those pesky <br>’s. First, let’s create a source data set imitating the described “contaminated” data:
data HAVE; infile datalines truncover; input STR $100.; datalines; Some strings<br> have unwanted sub<br>strings in them<br> <br>A s<br>entence must not be cont<br>aminated with unwanted subs<br>trings Several line<br> breaks<br> are inserted here<br><br><br> <br>Resulting st<br>ring must be n<br>eat and f<br>ree from un<br>desirable substrings Ugly unwanted substrings<br><br> must <br>be<br> removed <br>Let's remove them <br>using S<br>A<br>S language Ex<br>periment is a<br>bout to b<br>egin <br>Simpli<br>city may sur<br>prise you<br><br> ; |
This DATA step creates WORK.HAVE data set that looks pretty ugly and is hardly usable:

The following code, however, cleans it up removing all those unwanted substrings ‘<br>’:
data WANT (keep=NEW_STR); length NEW_STR $100; SUB = '<br>'; set HAVE; NEW_STR = transtrn(STR,SUB,trimn('')); run; |
After this code runs, the data set WANT will look totally clean and usable:

Code highlights
- We use TRANSTRN(source, target, replacement) function that does exactly what we need - replaces or removes all occurrences of a substring (target) in a character string (source). To remove all occurrences of target, we specify replacement as TRIMN("").
The TRANSTRN function is similar to TRANWRD function which replaces all occurrences of a substring in a character string. While TRANWRD uses a single blank when the replacement string has a length of zero, TRANSTRN does allow the replacement string to have a length of zero which essentially means removing.
- TRIMN(argument) function removes trailing blanks from character expressions and returns a string with a length of zero if its argument has missing value. It is similar to TRIM() function which removes trailing blanks from a character string and returns one blank if the string is missing. However, when it comes to removing (which is essentially replacement with zero length substring) the ability of TRIMN function to return a zero-length string makes all the difference.
Deleting all instances of a substring from a SAS macro variable
For macro variables, I can see two distinct methods of removing all occurrences of undesirable substring.
Method 1: Using SAS data step
Here is a code example:
%let STR = Some strings<br> have unwanted sub<br>strings in them<br>; %let SUB = <br>; data _null_; NEW_STR = transtrn("&STR","&SUB",trimn('')); call symputx('NEW',NEW_STR); run; %put &=STR; %put &=NEW; |
In this code, we stick our macro variable value &STR in double quotes in the transtrn() function as the first argument (source). The macro variable value &SUB, also double quoted, is placed as a second argument. After variable NEW_STR is produced free from the &SUB substrings, we create a macro variable NEW using call symputx() routine. SAS log will show the old and new values:
STR=Some strings<br> have unwanted sub<br>strings in them<br>
NEW=Some strings have unwanted substrings in them
Method 2: Using SAS macro language and %sysfunc
Here is a code example:
%let STR = Some strings<br> have unwanted sub<br>strings in them<br>; %let SUB = <br>; %let NEW = %sysfunc(transtrn(&STR,&SUB,%sysfunc(trimn(%str())))); %put &=STR; %put &=NEW; |
Deleting selected instance of a substring from a character variable
In many cases we need to remove not all substring instances form a string, but rather a specific occurrence of a substring. For example, in the following sentence (which is a quote by Albert Einstein) “I believe in intuitions and inspirations. I sometimes feel that I am right. I sometimes do not know that I am.” the second word “sometimes” was added by mistake. It needs to be removed. Here is a code example presenting two solutions of how such a deletion can be done:
data A; length STR STR1 STR2 $250; STR = 'I believe in intuitions and inspirations. I sometimes feel that I am right. I sometimes do not know that I am.'; SUB = 'sometimes'; STR_LEN = length(STR); SUB_LEN = length(SUB); POS = find(STR,SUB,-STR_LEN); STR1 = catx(' ', substr(STR,1,POS-1), substr(STR,POS+SUB_LEN)); /* solution 1 */ STR2 = kupdate(STR,POS,SUB_LEN+1); /* solution 2 */ put STR1= / STR2=; run; |
The code will produce two correct identical values of this quote in the SAS log (notice, that the second instance of word “sometimes” is gone):
STR1=I believe in intuitions and inspirations. I sometimes feel that I am right. I do not know that I am.
STR2=I believe in intuitions and inspirations. I sometimes feel that I am right. I do not know that I am.
Code highlights
- LENGTH() function determines the length STR_LEN of our initial string STR and the length SUB_LEN of our substring SUB.
- FIND() function determines position POS of the substring SUB to be deleted in the string STR. In this particular example, we used the fact, that the second occurrence of word “sometimes” is the first occurrence of this word when counted from right to left. That is indicated by the negative 3-rd argument (-STR_LEN) which means that FIND function searches STR for SUB starting from position STR_LEN from right to left.
Solution 1
This is the most traditional solution that cuts out two pieces of the string – before and after the substring being deleted – and then concatenates them together thus removing that substring:
- substr(STR,1,POS-1) extracts the first part of the source string STR before the substring to be deleted: from position 1 to position POS-1.
- substr(STR,POS+SUB_LEN) extracts the second part of the source string STR after the substring to be deleted: from position POS+SUB_LEN till the end of STR value (since the third argument, length, is not specified).
- CATX() function stitches (concatenates) these two parts together thus eliminating the second word “sometimes”. It also removes leading and trailing blanks from each piece and separates the two pieces with blanks (as specified by its first argument).
Solution 2
KUPDATE() function provides more elegant (and shorter) solution. In the kupdate(STR,POS,SUB_LEN+1) expression:
- The first argument specifies the source string STR.
- The second argument POS specifies position of the beginning of the substring.
- The third argument SUB_LEN+1 specifies length of the substring that we want to remove (+1 accounts for extra blank after word 'sometimes'.
- Optional forth argument specifies “characters-to-replace” the substring. Since we omitted it (specified none), nothing will replace the substring, that is it will be deleted.
Code notes
- If you know substring value and exact position in STR from which to delete that substring, you may skip FIND() part of the code and just specify position POS.
- If you need to delete n-th instance of your substring, you may find its position by using FINDNTH() function described in my post Finding n-th instance of a substring within a string .
Deleting selected instance of a substring from a SAS macro variable
Here is a code example of how to solve the same problem as it relates to SAS macro variables. For brevity, we provide just one solution using %sysfunc and KUPDATE() function:
%let STR = I believe in intuitions and inspirations. I sometimes feel that I am right. I sometimes do not know that I am.; %let SUB = sometimes; %let POS = %sysfunc(find(&STR,&SUB,-%length(&STR))); %let STR2 = %sysfunc(kupdate(&STR,&POS,%eval(%length(&SUB)+1))); %put "&STR2"; |
This should produce the following corrected Einstein’s quote in the SAS log:
"I believe in intuitions and inspirations. I sometimes feel that I am right. I do not know that I am."
Additional Resources for SAS character strings processing
- Inserting a substring into a SAS string
- Removing repeated characters in SAS strings
- How to unquote SAS character variable values
- Expanding lengths of all character variables in SAS data sets
- Finding n-th instance of a substring within a string
Your thoughts?
Have you found this blog post useful? Please share your thoughts and feedback in the comments section below.
WANT MORE GREAT INSIGHTS MONTHLY? | SUBSCRIBE TO THE SAS TECH REPORT
16 Comments
Hi, curious ... what's the purpose of the variable SUB in this code. Thanks.
data WANT (keep=NEW_STR);
length NEW_STR $100;
SUB = '<br>';
set HAVE;
NEW_STR = transtrn(STR,'<br>',trimn(''));
run;
Hi Mike,
Thank you for this catch. I meant to use SUB within the expression NEW_STR = transtrn(STR,SUB,trimn('')); instead of hard-coded NEW_STR = transtrn(STR,'<br>',trimn(''));
I have corrected this in the blog.
Nice article! I had not used two of the functions referenced and I'm excited to try them. Thank you.
You are welcome, and thank you, Louise, for your lovely comment. I feel rewarded that even such a SAS pundit as you learn something new from my blog 🙂
Perl Regular Express is good for this kind of question.
data HAVE; infile datalines truncover; input STR $100.; datalines; Some strings<br> have unwanted sub<br>strings in them<br> <br>A s<br>entence must not be cont<br>aminated with unwanted subs<br>trings Several line<br> breaks<br> are inserted here<br><br><br> <br>Resulting st<br>ring must be n<br>eat and f<br>ree from un<br>desirable substrings Ugly unwanted substrings<br><br> must <br>be<br> removed <br>Let's remove them <br>using S<br>A<br>S language Ex<br>periment is a<br>bout to b<br>egin <br>Simpli<br>city may sur<br>prise you<br><br> ; data want; set have; want=prxchange('s/<.+?>//',-1,str); run;Thank you, Ksharp, for your constructive comment. Indeed, Perl regular expressions are very powerful and can be used in SAS via prxchange() function. However, I found it to be considerably less efficient than using SAS string manipulation functions. For example, I ran the following code, and it turned out that the
transtrn(STR,'<br />',trimn(''))approach ran more than twice as fast asprxchange('s/<.+?>//',-1,str):/* 25 sec */ data LONG; set HAVE; do i=1 to 10000000; output; end; run; /* 3:51 min = 231 sec */ data WANT; set LONG; want=prxchange('s/<.+?>//',-1,str); run; /* 1:48 min = 108 sec */ data WANT1; set LONG; want=transtrn(STR,'<br />',trimn('')); run;Could you run this (or similar) test on your machine to see if your results are consistent with mine?
Agree. But PRX could handle many tags like:
<a href="." rel="nofollow ugc">... and so on</a>and have less code and are more powerful. Everyone has different preferences I guess.
To me it is always choice between 1) code length, 2) run time, and 3) code clarity. In my current projects I am dealing with rather large data, therefore program efficiency (run time) is a paramount. For this particular example, code length is not much different:
transtrn(STR,'<br />',trimn(''))vs.
prxchange('s/<.+?>//',-1,str)However, processing time for the first code snippet is considerably less. Besides, code clarity and repeatability is better.
Having said that, for some string processing tasks (e.g. data validation) using regular expressions can produce more robust solutions.
SAS Rules, everywhere!
A useful / instructive article, thanks for sharing.
You are welcome, Allan. Thanks for sharing your feedback!
Nice pieces of code, especially the TRIMN('') pseudo-constant and the KUPDATE. Thanks for sharing ! What's more, according from the documentation - and to its 1st letter name, as well - the KUPDATE function generously applies to single-byte encoding variable *and* multi-bytes UTF also, therefore full viya enabled. Why not byte off more than you can chew ? 😉
Thank you, Ronan, for your very constructive comment. Indeed, KUPDATE function is extremely powerful.
Nice counterpart to the previous article.
As an "extra", let me remind the COMPBL() function which allows to remove multiple blanks from a string 🙂
All the best
Bart
Thank you, Bart! Yes, COMPBL() is a very handy function. I also wrote UNDUPC() function that removes ANY repeated characters from a string.
Very useful. Thanks
Great, I am happy to hear that, Bill. I am sure you will put it to use.