In the current artificial intelligence (AI) media storm, the deep learning hype is especially strong. Let's explore how these terms relate and why they're so hot right now. First, deep learning is not synonymous with AI or even machine learning. Artificial Intelligence is a broad field which aims to "automate cognitive processes." Machine learning is a subfield of AI that aims to automatically develop programs (called models) purely from exposure to training data.
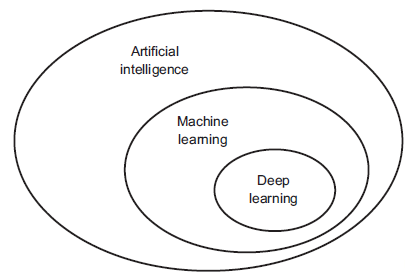
Deep learning is one of many branches of machine learning, where the models are long chains of geometric functions, applied one after the other to form stacks of layers. It is one among many approaches to machine learning but not on equal footing with the others.
What makes deep learning exceptional
Why is deep learning unequaled among machine learning techniques? Well, deep learning has achieved tremendous success in a wide range of tasks that have historically been extremely difficult for computers, especially in the areas of machine perception. This includes extracting useful information from images, videos, sound, and others.
Given sufficient training data (in particular, training data appropriately labelled by humans), it’s possible to extract from perceptual data almost anything that a human could extract. Large corporations and businesses are deriving value from deep learning by enabling human-level speech recognition, smart assistants, human-level image classification, vastly improved machine translation, and more. Google Now, Amazon Alexa, ad targeting used by Google, Baidu and Bing are all powered by deep learning. Think of superhuman Go playing and near-human-level autonomous driving.
In the summer of 2016, an experimental short movie, Sunspring, was directed using a script written by a long short-term memory (LSTM) algorithm a type of deep learning algorithm.
How to build deep learning models
Given all this success recorded using deep learning, it's important to stress that building deep learning models is more of an art than science. To build a deep learning or any machine learning model for that matter one need to consider the following steps:
- Define the problem: What data does the organisation have? What are we trying to predict? Do we need to collect more data? How can we manually label the data? Make sure to work with domain expert because you can’t interpret what you don’t know!
- What metrics can we use to reliably measure the success of our goals.
- Prepare validation process that will be used to evaluate the model.
- Data exploration and pre-processing: This is where most time will be spent such as normalization, manipulation, joining of multiple data sources and so on.
- Develop an initial model that does better than a baseline model. This gives some indication of whether machine learning is ideal for the problem.
- Refine model architecture by tuning hyperparameters and adding regularization. Make changes based on validation data.
- Avoid overfitting.
- Once happy with the model, deploy it into production environment. This may be difficult to achieve for many organisations giving that a deep learning score code is large. This is where SAS can help. SAS has developed a scoring mechanism called PROC ASTORE that allows deep learning method to be pushed into production with just a click.
Is the deep learning hype justified?
We're still in the middle of deep learning revolution trying to understand the limitations of this algorithm. Due to its unprecedented successes, there has been a lot of hype in the field of deep learning and AI. It’s important for managers, professionals, researchers and industrial decision makers to be able to distill reality from the hype created by the media.
Despite the progress on machine perception, we're still far from human level AI. Our models can only perform local generalization. Adapting to new situations that must be similar to past data, whereas human cognition is capable of extreme generalization, quickly adapting to radically novel situations and planning for long-term future situations.
To make this difference concrete, imagine you’ve developed a deep network controlling a human body, and you wanted it to learn to safely navigate a city without getting hit by cars, the net would have to die many thousands of times in various situations until it could infer that cars are dangerous, and develop appropriate avoidance behaviors. Dropped into a new city, the net would have to relearn most of what it knows. On the other hand, humans are able to learn safe behaviors without having to die even once — again, thanks to our power of abstract modeling of hypothetical situations.
Lastly, remember deep learning is a long chain of geometrical functions. To learn its parameters via gradient descent one key technical requirements is that it must be differentiable and continuous which is a significant constraint.
Download a deep learning whitepaper to learn more