We all have challenges in getting an accurate and consistent view of our customers across multiple applications or sources of customer information. Suggestion-based matching is a technique found in SAS Data Quality to improve matching results for data that has arbitrary typos and incorrect spellings in it. The suggestion-based concept and benefits were described in a previous blog post. In this post, I will expand on the topic and show how to build a data job that uses suggestion-based matching in DataFlux Data Management Studio, the key component of SAS Data Quality and other SAS Data Management offerings. This article takes a simple example job to illustrate the steps needed to configure suggestion-based matching for person names.
In DataFlux Data Management Studio I first configure a Job Specific Data node to define the columns and example records that I’d like to feed into the matching process. In this example, I use a two column data table made up of Rec_ID and a Name column and sample records as shown below.
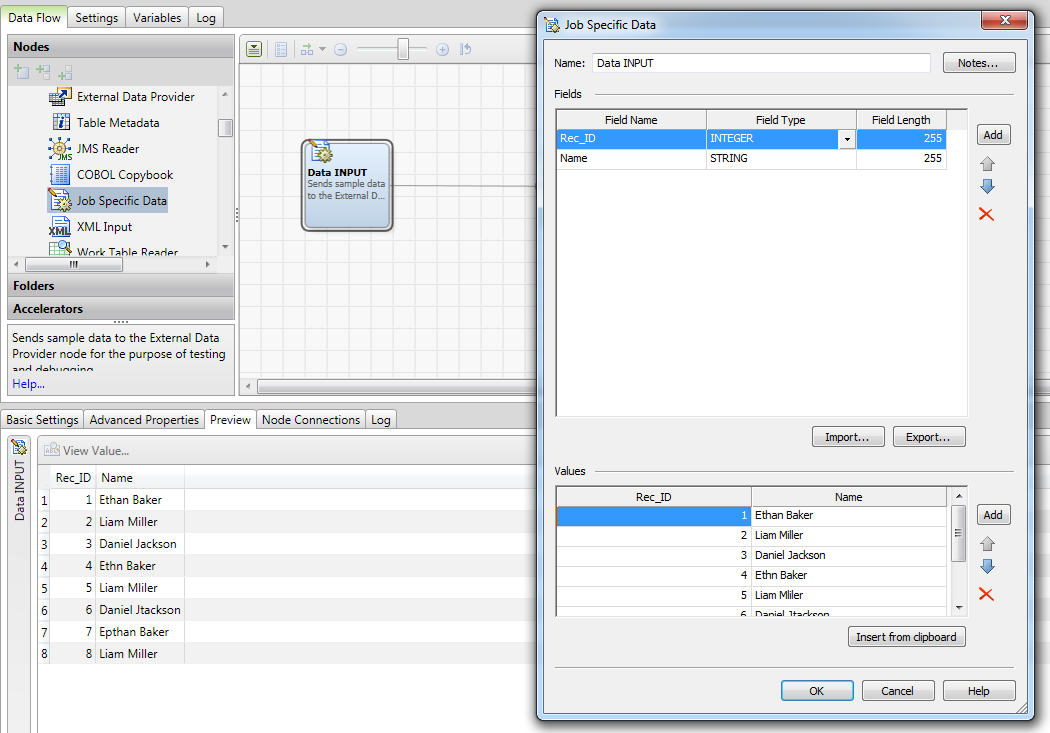
To build the suggestion-based matching feature, I have to insert and configure at least a Create Match Codes node, a Clustering Node and a Cluster Aggregation node in the data job.
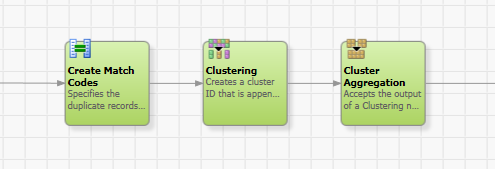
This example uses names with randomly injected typographical errors, like missing characters, additional characters and character transpositions. Please note, these types of data errors would not be matched correctly using the standard matching technique in SAS Data Quality, therefore I am leveraging the suggestion-based matching feature. The picture below shows the person names and highlights the injected errors for Ethan Baker.
For suggestion-based matching in SAS Data Quality I need to use a match definition that supports suggestions. The current Quality Knowledge Base (QKB) for Customer Information ships with a ready to use match definition called “Name (with suggestions).” For other data types, I can easily create new definitions or expand existing definitions to support the suggestions feature as well.
To continue building my suggestion-based matching job I next need to configure the Create Match Codes node as shown in the picture below.

In the property screen of the Create Match Codes node I select the Locale that matches my input data and pick the “Name (with Suggestions)” definition.
Next, I check Allow generation of multiple match codes per definition for each sensitivity in the property window. This enables the data job node to generate suggestions and also create an additional Match Score field as output.
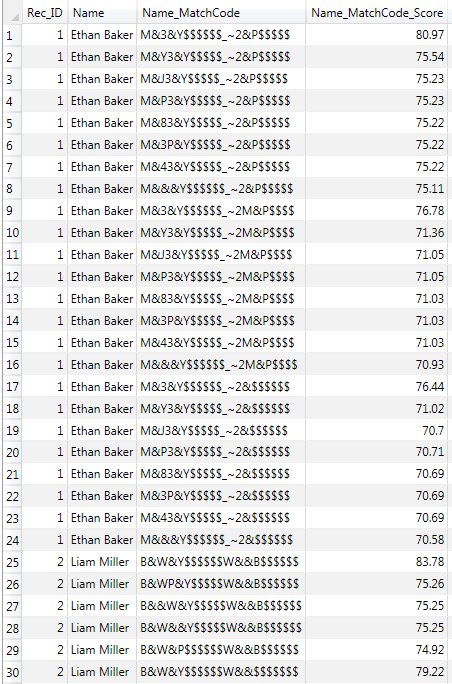
Looking at the output of the Match Codes node, we can see that we generate multiple different match codes (suggestions), and match scores for a single input (Ethan Baker). Because I selected Allow generation of multiple match codes per definition for each sensitivity, the Create Match Code node generates a match code representing the input name, plus additional match codes (suggestions) with character deletions, insertions, replacements and transpositions applied to the input name. The score value, in the Name_Match Code Score column, is an indicator for the closeness of the generated suggestion to the original input data. The more change operations are used to create the suggestion, the lower the score value. Therefore the lower the score the less likely it is that the suggestion is the true name.
Next in configuring my suggestion-based matching job is the Clustering node.
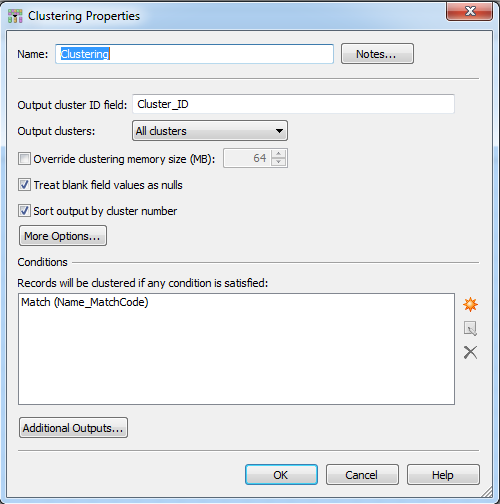
There are no specific configuration needed in the Clustering node when using it with suggestion-based matching. In my example I only set the Name_Match Code field as the match condition and I pass all input fields as output (in Additional Outputs).
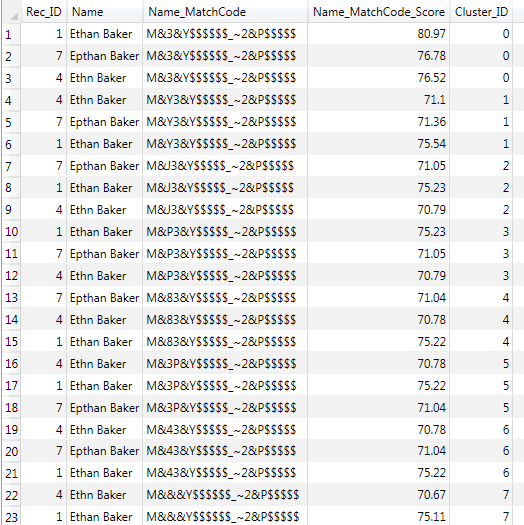
Previewing the output of the cluster node I can already see the misspelled names of “Ethan Baker” are clustered correctly. But because I generated multiple suggestions for each input record, I end up with multiple clusters holding the same input records. Ethan Baker, Ethn Baker and Epthan Baker and its suggestions are assigned to cluster 0 to 7 and would also appear in single row clusters further down the output list. It is ok at this step of the data job to have two or more clusters containing the same set of input records when using suggestion-based matching. The next node in the data job will resolve the issue and use the match score to determine the single best cluster.
In the properties of the Cluster Aggregation node I set Cluster ID, Primary Key and Score fields (which were outputs of the previous Cluster node). In order to determine the single best cluster, I select the Cluster as a scoring method and Highest Mean as scoring algorithm. The Cluster Aggregation node will compute the mean value in each cluster. By checking Remove subclusters, I make sure only the cluster with the highest mean is outputted.
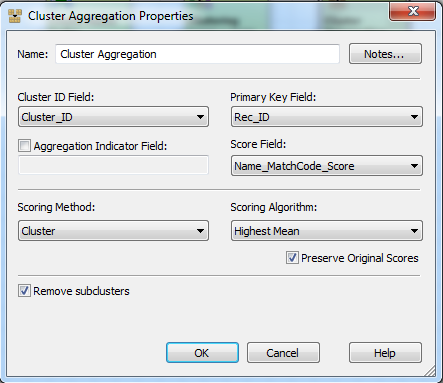
With the Cluster Aggregation node configured the output looks like this:
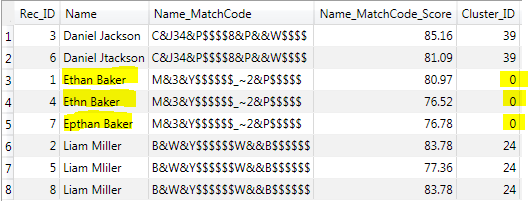
The final output of the Cluster Aggregation is reduced to the eight input records only. With the described set-up I successfully matched names that contain typographical errors like additional or missing characters.
As you can see above, the accuracy of your matching rules, and ultimately, your understanding of your customers, can be augmented through use of suggestion-based matching.
For more information, please refer to the product documentation:
