 Have you ever had problems matching data that has typographical errors in it? Because of the nature of arbitrary typos and incorrect spelled words a specific matching technique is required to tackle those cases. SAS Data Quality, with its traditional, in nature deterministic matching approach is by nature not best suited for correctly matching typos such as character transpositions and missing or additional characters in words. But SAS provides a feature called suggestion based matching in SAS Data Quality especially designed for matching data with typos. Suggestion based matching provides a more probabilistic alike way towards matching. With suggestion based matching, SAS Data Quality will output multiple matchcodes based on alternative “suggestions” for a data field. Each suggestion also includes a score that reflects the closeness of the suggestion to input word.
Have you ever had problems matching data that has typographical errors in it? Because of the nature of arbitrary typos and incorrect spelled words a specific matching technique is required to tackle those cases. SAS Data Quality, with its traditional, in nature deterministic matching approach is by nature not best suited for correctly matching typos such as character transpositions and missing or additional characters in words. But SAS provides a feature called suggestion based matching in SAS Data Quality especially designed for matching data with typos. Suggestion based matching provides a more probabilistic alike way towards matching. With suggestion based matching, SAS Data Quality will output multiple matchcodes based on alternative “suggestions” for a data field. Each suggestion also includes a score that reflects the closeness of the suggestion to input word.
Let's dive a little deeper.
The concept of SAS Data Quality suggestion based matching
 Prerequisite for suggestion based matching in SAS Data Quality is a dictionary of known words along with a frequency count for each word. The matching engine will generate “suggestions” for potentially misspelled input values from the known words dictionary. The generated suggestions are made of the data input, but with spelling errors like character deletions, insertions, replacements, and transpositions. Whitespace insertion, casing, and context-dependent pronunciation can also be taken into account. For each suggestion a score, that reflects the closeness of it to the input, is calculated. The higher the match score for a suggestion, the more likely it is the true entity.
Prerequisite for suggestion based matching in SAS Data Quality is a dictionary of known words along with a frequency count for each word. The matching engine will generate “suggestions” for potentially misspelled input values from the known words dictionary. The generated suggestions are made of the data input, but with spelling errors like character deletions, insertions, replacements, and transpositions. Whitespace insertion, casing, and context-dependent pronunciation can also be taken into account. For each suggestion a score, that reflects the closeness of it to the input, is calculated. The higher the match score for a suggestion, the more likely it is the true entity.
The known words dictionary is generated with the idea that the number of correctly spelled entity names are more frequent and therefore outnumber the misspelled ones. This is an important aspect of the match score calculation for the suggestions. The matching engine will generate suggestions by taking the input value and “inject” character transpositions, replacements and other typos and compare it against the known words dictionary entries. During the whole process the input value is seen as the potentially corrupted version of the true entity. By making various character based alterations to the input data, the matching engine tries to find possible candidate entities in the known words dictionary. If one of the suggestions matches a word of the known words dictionary the engine calculates a match score based on the frequency count and the changes required to create the suggestion. This concept potentially results in a list of possible matches including the true entity and other misspelled or “close enough” words identified as 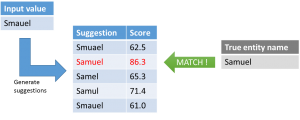 potential matches. The resulting match score can finally help to resolve the true entity.
potential matches. The resulting match score can finally help to resolve the true entity.
Suggestion based matching involves more compute resource and therefore will slow down data throughput of the matching process. Still, it is a proven approach to provide match results for input data that contains character level data quality issues. To minimize performance implication, suggestion based matching is best used as a second iteration for input data that could not be matched using the standard matchcode method.

