 Finding a pattern like a phone number or national ID number embedded in text can be difficult and time consuming.
Finding a pattern like a phone number or national ID number embedded in text can be difficult and time consuming.
The traditional DATA step has a family of functions (collectively referred to as PRX functions) that allow using Perl regular expressions in your SAS programs to make pattern search easier. However, all of that power comes at a cost, and using PRX functions can significantly increase processing overhead. The PRX functions were also implemented in DS2, allowing threaded processing, which somewhat mitigates the performance issue. But a new pair of predefined packages in the SAS 94.M5 release of DS2 have made pattern search easier and more performant. Initial benchmarking by the development team indicated a performance boost significant enough that the PRX functions will be deprecated in future versions of DS2. Personally, I find the package syntax easier to write and remember than the various and sundry PRX functions.
For example, this program finds social security number (SSN) patterns embedded in random text:
proc ds2; data; dcl int rxid rc; dcl varchar(15) found_ssn; keep text ssn found_ssn; retain rxid; method init(); rxid=prxparse('/(\d{3}-?\d{2}-?\d{4})/'); end; method run(); set my_data.web_babble; rc=PRXMATCH(rxid,text); if rc then found_ssn=PRXPOSN(rxid,1,text); end; enddata; run; quit; |
The program produces this report:
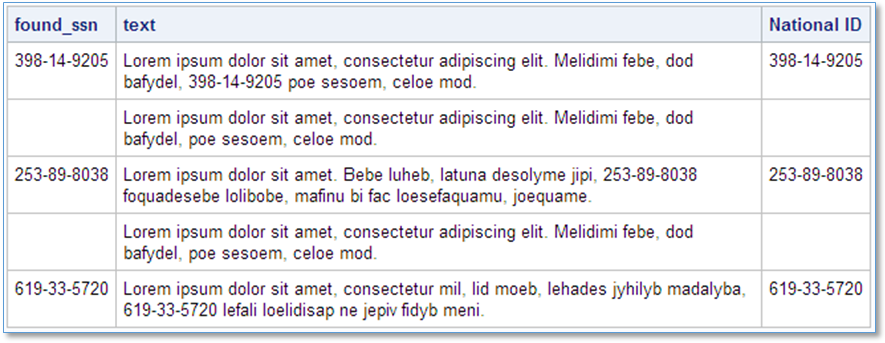
We can easily see that the process is finding and extracting the SSNs embedded in the text.
The PCRXFIND package provides several useful methods for processing text with regular expressions:

This program uses the PCRXFIND package instead of the PRX funtions to find the SSN patterns:
proc ds2; data; declare package pcrxfind rxf(); dcl int rc; dcl varchar(15) found_ssn; keep text ssn found_ssn; method init(); rc=rxf.parse('/(\d{3}-?\d{2}-?\d{4})/'); end; method run(); set my_data.web_babble; rc=rxf.match(text); if rc > 0 then rc=rxf.getGroup(found_ssn,1); end; enddata; run;quit; |
It produces a report identical to the previous program:
Let's say we would rather redact the SSNs in place rather than extract them from the text. For this, we'll use the PCRXREPLACE package. The PCRXREPLACE package includes only two methods - PARSE and APPLY. PCRXREPLACE also supports the 'global' regular expression flag (g). With the global flag set, all occurrences of the pattern will be replaced, no matter how many times it is found. Here is an example:
proc ds2; data; declare package pcrxreplace rxf(); dcl int rc; method init(); rc=rxf.parse('s/\d{3}-?\d{2}-?\d{4}/**REDACTED**/g'); end; method run(); set my_data.web_babble; rc=rxf.apply(text); end; enddata; run; quit; |
This does the job quite nicely:
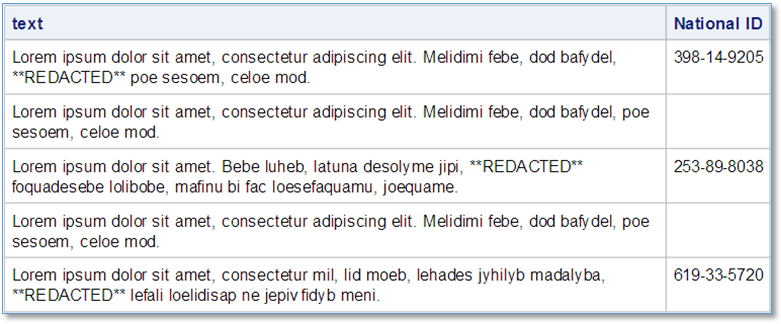
I think this is the beginning of a beautiful friendship with the new DS2 PCRX packages!
As usual, you can download the code from this link. Until the next time, may the SAS be with you!
Mark







4 Comments
How to create a sas data set from the result if I don't want to see report?
Thanks.
Just add a data set name to the DATA statement. For example:
data work.mydata;
Regards,
Mark
is it possible provide the demo data you use ?
Absolutely! Here is a program which will recreate the data for you:
data work.babble_text;
infile datalines dsd truncover;
input text:$256. ;
datalines4;
"Lorem ipsum dolor sit amet, consectetur adipiscing elit. Melidimi febe, dod bafydel, 123-45-6789 poe sesoem, celoe mod."
"Lorem ipsum dolor sit amet, consectetur adipiscing elit. Melidimi febe, dod bafydel, poe sesoem, celoe mod."
"Lorem ipsum dolor sit amet. Bebe luheb, latuna desolyme jipi, 987-65-4321 foquadesebe lolibobe, mafinu bi fac loesefaquamu, joequame."
"Lorem ipsum dolor sit amet. Bebe luheb, latuna desolyme jipi, foquadesebe lolibobe, mafinu bi fac loesefaquamu, joequame."
;;;;