Dictionary tables are one of the things I love most about SQL! What a useful thing it is to be able to programmatically determine what your data looks like so you can write self-modifying and data-driven programs. While PROC SQL has a great set of dictionary tables, they all rely on the metadata reported by the SAS LIBNAME engine where all data types are either CHAR or NUM and all variable names are a maximum of 32 characters long. In today's work environment, data is much more likely to be stored in a database management system (DBMS) of some kind, or perhaps in Hadoop. If you are writing SQL pass-through for those platforms, or if you are manipulating your data with a more modern language like DS2, you need to know the actual ANSI data types in play, but the SAS/Access LIBNAME engine just keeps reporting column types as "CHAR, CHAR, CHAR, NUM, NUM, NUM"... I need more from my dictionary tables!
proc sql;
select *
from dictionary.columns
where libname = 'MY_ORA'
and memname LIKE 'EMPLOYEE%'
;
quit;

If you have programmed in DS2, you know that the SET statement in DS2 will accept an SQL query result set as input without first writing the result to disk. The actual language used here is the SAS-proprietary Federated Query Language, affectionately know as FedSQL. What you might not know is that you can write FedSQL stand-alone queries without invoking DS2 using the Base SAS FedSQL procedure (PROC FedSQL). FedSQL is extremely ANSI compliant, scalable and is highly effective at implicit pass-through. It comes with a completely new set of dictionary tables which provide richer information about your data, particularly if that data resides in a DBMS:
proc fedsql;
select *
from dictionary.columns
where table_cat = 'MY_ORA'
and table_schem = 'STUDENT'
and table_name LIKE 'EMPLOYEE%'
;
quit;

I and others have noticed that dictionary table queries take longer to execute in FedSQL than they do in PROC SQL. This is true, and there are a number of reasons. On my first attempt to compare, I tried something like this:
libname my_ora oracle user=student password=Metadata0 schema=student; proc sql; select * from dictionary.columns where libname = 'MY_ORA' ; quit; proc fedsql; select * from dictionary.columns where table_cat = 'MY_ORA' ; quit;
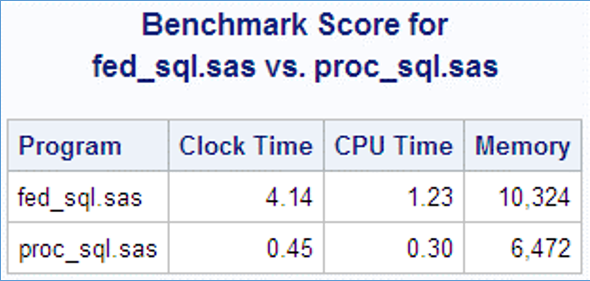
Benchmarking these two queries showed an astounding difference in execution time:
A quick look at the SAS log revealed a good reason for this disparity:
/* PROC SQL */ NOTE: Table WORK.SQL created, with 12 rows and 18 columns. /* PROC FedSQL */ NOTE: Execution succeeded. 19771 rows affected. |
Wow! 19,771 rows vs. 12 rows! Because PROC SQL accesses data through the LIBNAME engine, and the LIBNAME engine restricts access to a single schema, PROC SQL was only reporting on the tables in the STUDENT schema. However, FedSQL accesses data using a special threaded driver instead of the LIBNAME engine. And a peek at the result set revealed that PROC FedSQL was reporting on all columns in all Oracle tables to which I had read access. This included SYSTEM tables and several other schemas, such as the Orion schema.
So I re-wrote the query to restrict the FedSQL reporting to just the Student schema in Oracle, and this produced results consistent with the number of rows returned by PROC SQL:
proc fedsql;
select *
from dictionary.columns
where table_cat = 'MY_ORA'
and table_schem = 'STUDENT'
;
quit;
/* PROC SQL */ NOTE: Table WORK.SQL created, with 8 rows and 18 columns. /* PROC FedSQL */ NOTE: Execution succeeded. 8 rows affected. |
While this DID improve the execution time for FedSQL, you can see that it is still significantly slower that the PROC SQL query:
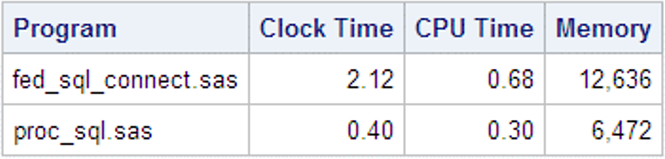
I created tables from the output for comparison, and found that the observation length produced by FedSQL was 8272 bytes, vs. 520 bytes for SQL. This is due to the fact that all character columns in the FedSQL dictionary tables are 1024 bytes in length, probably to accommodate the larger identifier string sizes allowed in ANSI databases.

With FedSQL row sizes about 16X greater than those returned by SQL, it’s no wonder FedSQL tables are a bit slower. In fact, at “only” 5X slower, it might just be a bargain!
I am currently working on a new half-day training course for SAS (working title is "SQL Methods and More"). It's designed to help SAS programmers make better use of the resources available to them, particularly when working with DBMS data. We'll focus on getting better performance out of SQL in SAS, including PROC SQL, implicit SQL generated by traditional SAS processes, and it even takes a small dip into FedSQL. It will be a lot of fun to teach, and should be available later this year. When more information becomes available, I'll add a link in the comments of this post.
Until next time, may the SAS be with you!
Mark