Order must be the most frequent cry for help in the SAS classroom. “HELP,” said my student in the classroom. “I work with messy health data. My users want to see data in this order.”
T1.col1, t1.col2, t1.col3, t1.col4, t2.col5, t1.col6 and list the remaining columns in column position from table 1.
My 2 tables, t1 and t2, have hundreds of columns. They have a common column for me to join the tables on and I really don’t want to spend manually typing each and every column name in the SELECT statement. That’s way too much time on manual work, time that could be spent doing more productive work. Can you help make this process dynamic?
How was I going to help this customer? I knew I could rely on PROC SQL dictionary tables to grab metadata, in this case the column names without hardcoding them. I also knew that the column names that dictionary tables return could be stored in a macro. Making it easy for me to write a SELECT.
Given that I only had the problem but no data to work with, I turned to the SASHELP library (PDF). It’s a great repository of over 200 sample datasets. I went ahead and submitted this code to query the dictionary tables called columns to find out which datasets I could use to answer the customer question. I wanted datasets that had the same name and type to perform the join.
*Step 1 : locating columns that have the same name & type to perform the equijoin; proc sql; select name, memname, type, length from dictionary.columns where libname ='SASHELP' group by name having count(name) > 1 AND COUNT(DISTINCT TYPE) =1 order by name; quit; |
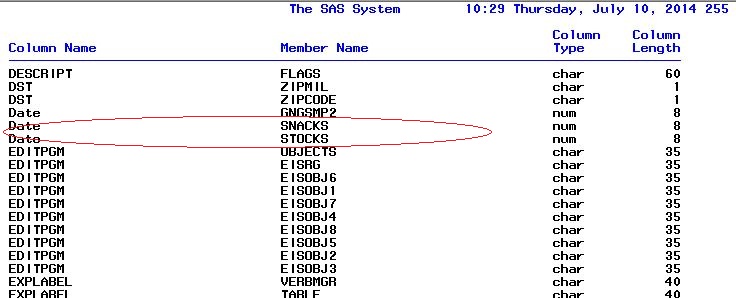
I started writing code to store the column names from the 2 tables in the desired order in macro variables:
For example:
*Step 2 : storing column names in macro variables in the order specified. Macro variable first4 stores the first 4 column names from the STOCKS dataset Macro variable fifth stores the 5th column name from the SNACKS dataset Macro variable after5 stores column names after 5th position from the STOCKS dataset; proc sql noprint; select name into : first4 separated by ', ' from dictionary.columns where libname="SASHELP" and memname="STOCKS" and varnum < 5; select name into : fifth separated by ', ' from dictionary.columns where libname="SASHELP" and memname="SNACKS" and varnum = 5; select name into : after5 separated by ', ' from dictionary.columns where libname="SASHELP" and memname="STOCKS" and varnum > 5 ; Quit; *just confirming the order of variables; %put &first4, &fifth, &after5; Stock, Date, Open, High, Date, Close, Volume, AdjClose *Step 3 : joining the 2 tables and selecting columns in the order defined in the macro variables. But why doesn't this work? Why the Error? proc sql noprint; select &first4, &fifth, &after5 from sashelp.SNACKS as t1, sashelp.STOCKS AS t2 where t1.DATE=t2.DATE; ERROR: Ambiguous reference, column Date is in more than one table. ERROR: Ambiguous reference, column Date is in more than one table. |
Well of course! The Date column appears twice, once from each table. It’s that beautifully flexible thing that SQL does. But how do you overcome this?
This is when I turned to our instructor world-wide group. Did you know that? When you sign up for SAS training you get not one, but hundreds of SAS instructors chipping in to help solve your business problems.
I got this amazing suggestion from one of the instructors.
cats('P.',name) into : first4 separated by ', ' cats('Z.',name) into : after5 separated by ', ' |
And decided to re-write my original code.
*Step 2 : storing column names in macro variables in the order specified. Macro variable first4 stores the first 4 column names from the STOCKS dataset Macro variable fifth stores the 5th column name from the SNACKS dataset Macro variable after5 stores column names after 5th position from the STOCKS dataset; proc sql noprint; select cats('t1.',name) into : first4 separated by ', ' from dictionary.columns where libname="SASHELP" and memname="STOCKS" and varnum < 5; select cats('t2.',name) into : fifth separated by ', ' from dictionary.columns where libname="SASHELP" and memname="SNACKS" and varnum = 5; select cats('t1.',name) into : after5 separated by ', ' from dictionary.columns where libname="SASHELP" and memname="STOCKS" and varnum > 5 ; *just confirming the order of variables; %put &first4, &fifth, &after5; *Step 3 : joining the 2 tables and selecting columns in the order defined in the macro variables. And this works! YAY! reset print; select &first4, &fifth, &after5 from sashelp.STOCKS as t1, sashelp.SNACKS AS t2 where t1.DATE=t2.DATE; |
And it worked like a charm!
Customer has the columns in the order in which they want it. Bonus: No hard coding of column names.
Don’t you just love the marriage of PROC SQL, the macro language and the SAS CATS function to deliver just what was required.
There is so much more you can do with PROC SQL dictionary tables. Here’s a handy reference paper (PDF) that you might like to check out.
What other ideas do you have to solve this problem? Write to me. I’d love to hear from you.




5 Comments
Donna, I believe I already replied via email but also wanted to follow up to your blog question. try the yrdif function & use age as the basis. Here' is the support.sas.com link with several examples to help you get started..https://support.sas.com/documentation/cdl/en/lefunctionsref/63354/HTML/default/viewer.htm#p1pmmr2dtec32an1vbsqmm3abil5.htm
Charu - I am from the SAS EG Kingston training with the Ministry of Health. You were on the last day trying to show me the statement for pull age out of the data set and not birthdate using the "function"
thanks for your question Glen. Take a look at the Information Schema Views here http://msdn.microsoft.com/en-us/library/ms186778.aspx:
An information schema view is one of several methods SQL Server provides for obtaining metadata. Information schema views provide an internal, system table-independent view of the SQL Server metadata. Information schema views enable applications to work correctly although significant changes have been made to the underlying system tables. The information schema views included in SQL Server comply with the ISO standard definition for the INFORMATION_SCHEMA.
A jump start that gets everything would be...
SELECT * FROM INFORMATION_SCHEMA.TABLES
SELECT * FROM INFORMATION_SCHEMA.COLUMNS
Then add your where clauses to narrow it down to tables and columns from tables you’re interested in.
"dictionary.columns" provides a great way to get information from DB2. For example, I can conduct impact analysis after a change by storing the names of all tables and fields in a SAS dataset, then running a macro to determine which were affected. However, I was wondering if there is any equivalent for SQL/Server databases? "dictionary.columns" returns no results.
You solved it in the classic program coding way.
Using DI and SAS metadata that coding has been made graphical (click your mouse).
Using the query builder (eg EGuide) is another one that the approach is graphical
There are a lot of SAS persons telling "they should not code, but use our menu-s"